 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Guided Unsupervised Domain Adaptation for Robotic Semantic Segmentation
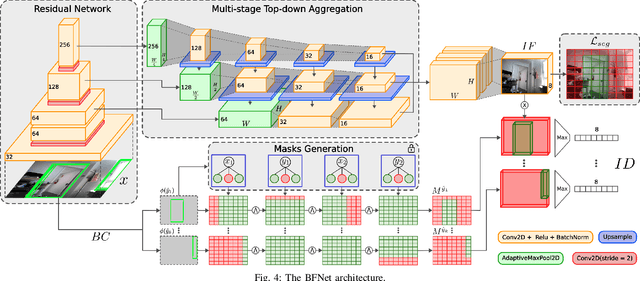
Feb 01, 2026Semantic segmentation networks, which are essential for robotic perception, often suffer from performance degradation when the visual distribution of the deployment environment differs from that of the source dataset on which they were trained. Unsupervised Domain Adaptation (UDA) addresses this challenge by adapting the network to the robot's target environment without external supervision, leveraging the large amounts of data a robot might naturally collect during long-term operation. In such settings, UDA methods can exploit multi-view consistency across the environment's map to fine-tune the model in an unsupervised fashion and mitigate domain shift. However, these approaches remain sensitive to cross-view instance-level inconsistencies. In this work, we propose a method that starts from a volumetric 3D map to generate multi-view consistent pseudo-labels. We then refine these labels using the zero-shot instance segmentation capabilities of a foundation model, enforcing instance-level coherence. The refined annotations serve as supervision for self-supervised fine-tuning, enabling the robot to adapt its perception system at deployment time. Experiments on real-world data demonstrate that our approach consistently improves performance over state-of-the-art UDA baselines based on multi-view consistency, without requiring any ground-truth labels in the target domain.
Frontier-Based Exploration for Multi-Robot Rendezvous in Communication-Restricted Unknown Environments
Mar 27, 2024Multi-robot rendezvous and exploration are fundamental challenges in the domain of mobile robotic systems. This paper addresses multi-robot rendezvous within an initially unknown environment where communication is only possible after the rendezvous. Traditionally, exploration has been focused on rapidly mapping the environment, often leading to suboptimal rendezvous performance in later stages. We adapt a standard frontier-based exploration technique to integrate exploration and rendezvous into a unified strategy, with a mechanism that allows robots to re-visit previously explored regions thus enhancing rendezvous opportunities. We validate our approach in 3D realistic simulations using ROS, showcasing its effectiveness in achieving faster rendezvous times compared to exploration strategies.
R2SNet: Scalable Domain Adaptation for Object Detection in Cloud-Based Robots Ecosystems via Proposal Refinement
Mar 21, 2024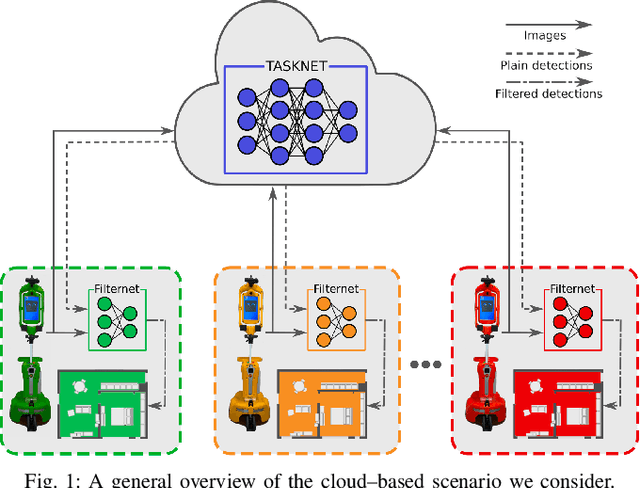

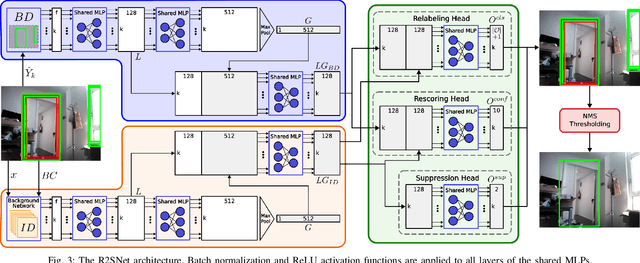
We introduce a novel approach for scalable domain adaptation in cloud robotics scenarios where robots rely on third-party AI inference services powered by large pre-trained deep neural networks. Our method is based on a downstream proposal-refinement stage running locally on the robots, exploiting a new lightweight DNN architecture, R2SNet. This architecture aims to mitigate performance degradation from domain shifts by adapting the object detection process to the target environment, focusing on relabeling, rescoring, and suppression of bounding-box proposals. Our method allows for local execution on robots, addressing the scalability challenges of domain adaptation without incurring significant computational costs. Real-world results on mobile service robots performing door detection show the effectiveness of the proposed method in achieving scalable domain adaptation.
Development and Adaptation of Robotic Vision in the Real-World: the Challenge of Door Detection
Jan 31, 2024Mobile service robots are increasingly prevalent in human-centric, real-world domains, operating autonomously in unconstrained indoor environments. In such a context, robotic vision plays a central role in enabling service robots to perceive high-level environmental features from visual observations. Despite the data-driven approaches based on deep learning push the boundaries of vision systems, applying these techniques to real-world robotic scenarios presents unique methodological challenges. Traditional models fail to represent the challenging perception constraints typical of service robots and must be adapted for the specific environment where robots finally operate. We propose a method leveraging photorealistic simulations that balances data quality and acquisition costs for synthesizing visual datasets from the robot perspective used to train deep architectures. Then, we show the benefits in qualifying a general detector for the target domain in which the robot is deployed, showing also the trade-off between the effort for obtaining new examples from such a setting and the performance gain. In our extensive experimental campaign, we focus on the door detection task (namely recognizing the presence and the traversability of doorways) that, in dynamic settings, is useful to infer the topology of the map. Our findings are validated in a real-world robot deployment, comparing prominent deep-learning models and demonstrating the effectiveness of our approach in practical settings.
Robust Multi-Agent Pickup and Delivery with Delays
Mar 30, 2023



Multi-Agent Pickup and Delivery (MAPD) is the problem of computing collision-free paths for a group of agents such that they can safely reach delivery locations from pickup ones. These locations are provided at runtime, making MAPD a combination between classical Multi-Agent Path Finding (MAPF) and online task assignment. Current algorithms for MAPD do not consider many of the practical issues encountered in real applications: real agents often do not follow the planned paths perfectly, and may be subject to delays and failures. In this paper, we study the problem of MAPD with delays, and we present two solution approaches that provide robustness guarantees by planning paths that limit the effects of imperfect execution. In particular, we introduce two algorithms, k-TP and p-TP, both based on a decentralized algorithm typically used to solve MAPD, Token Passing (TP), which offer deterministic and probabilistic guarantees, respectively. Experimentally, we compare our algorithms against a version of TP enriched with online replanning. k-TP and p-TP provide robust solutions, significantly reducing the number of replans caused by delays, with little or no increase in solution cost and running time.
Enhancing Door Detection for Autonomous Mobile Robots with Environment-Specific Data Collection
Mar 08, 2022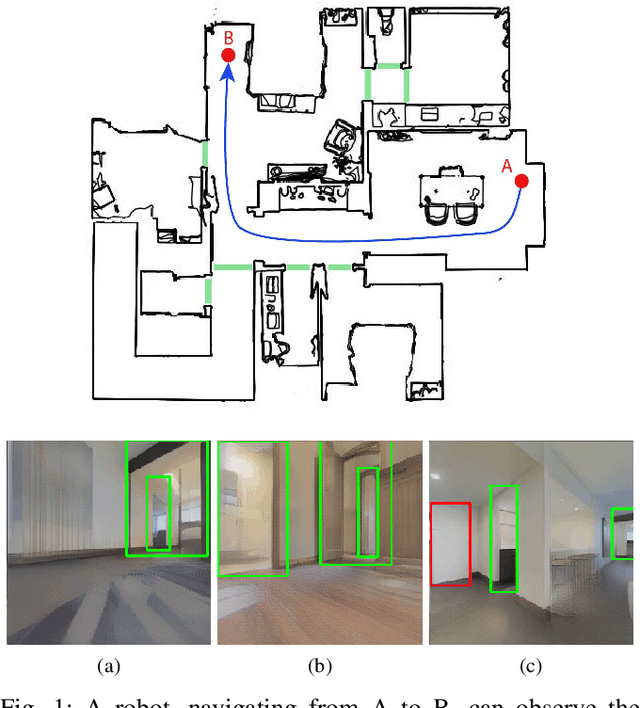
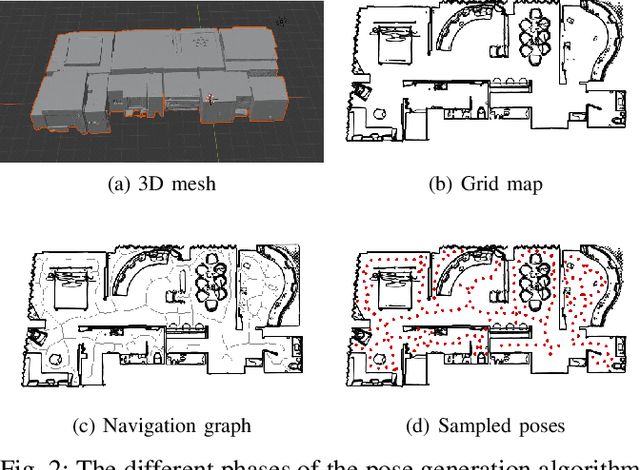

Door detection represents a fundamental capability for autonomous mobile robots employed in tasks involving indoor navigation. Recognizing the presence of a door and its status (open or closed) can induce a remarkable impact on the navigation performance, especially for dynamic settings where doors can enable or disable passages, hence changing the actual topology of the map. In this work, we address the problem of building a door detector module for an autonomous mobile robot deployed in a long-term scenario, namely operating in the same environment for a long time, thus observing the same set of doors from different points of view. First, we show how the mainstream approach for door detection, based on object recognition, falls short in considering the constrained perception setup typical of a mobile robot. Hence, we devise a method to build a dataset of images taken from a robot's perspective and we exploit it to obtain a door detector based on an established deep-learning object-recognition method. We then exploit the long-term assumption of our scenario to qualify the model on the robot working environment via fine-tuning with additional images acquired in the deployment environment. Our experimental analysis shows how this method can achieve good performance and highlights a trade-off between costs and benefits of the fine-tuning approach.
Methods for finding leader--follower equilibria with multiple followers
Jul 07, 2017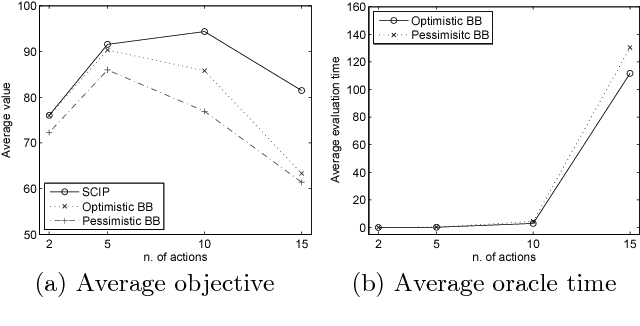
The concept of leader--follower (or Stackelberg) equilibrium plays a central role in a number of real--world applications of game theory. While the case with a single follower has been thoroughly investigated, results with multiple followers are only sporadic and the problem of designing and evaluating computationally tractable equilibrium-finding algorithms is still largely open. In this work, we focus on the fundamental case where multiple followers play a Nash equilibrium once the leader has committed to a strategy---as we illustrate, the corresponding equilibrium finding problem can be easily shown to be $\mathcal{FNP}$--hard and not in Poly--$\mathcal{APX}$ unless $\mathcal{P} = \mathcal{NP}$ and therefore it is one among the hardest problems to solve and approximate. We propose nonconvex mathematical programming formulations and global optimization methods to find both exact and approximate equilibria, as well as a heuristic black box algorithm. All the methods and formulations that we introduce are thoroughly evaluated computationally.
Team-maxmin equilibrium: efficiency bounds and algorithms
Nov 18, 2016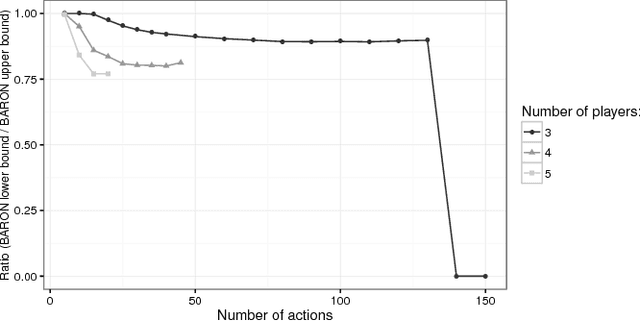
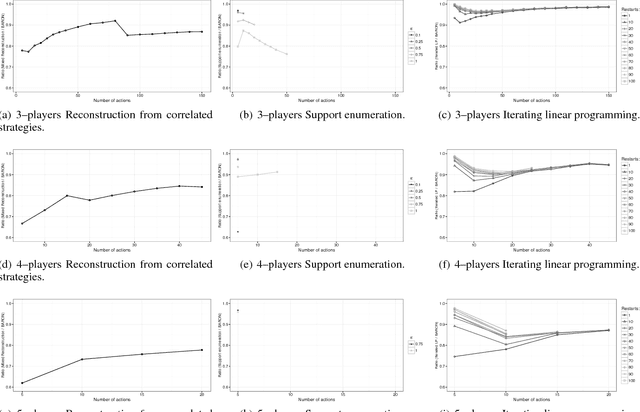
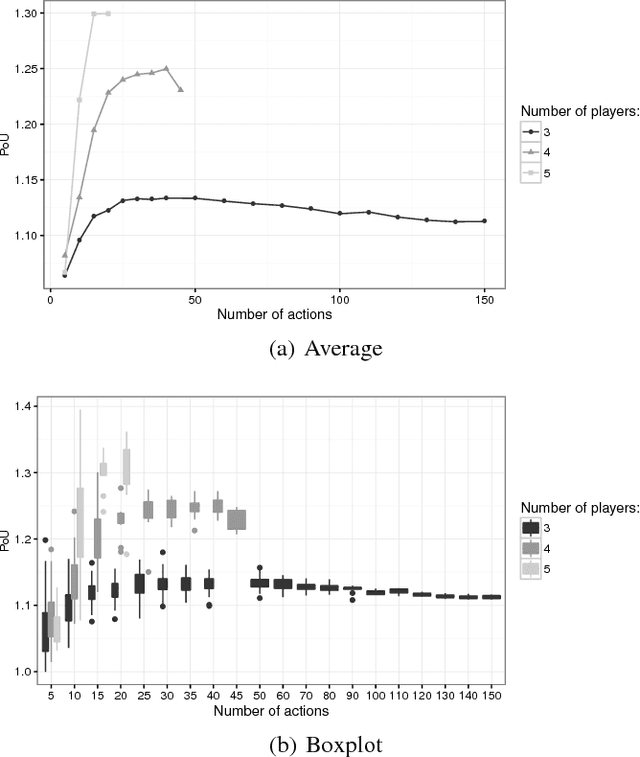
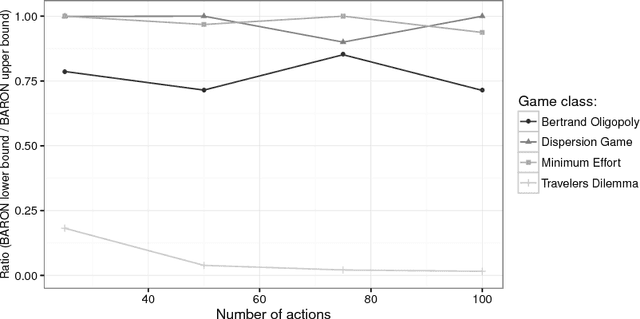
The Team-maxmin equilibrium prescribes the optimal strategies for a team of rational players sharing the same goal and without the capability of correlating their strategies in strategic games against an adversary. This solution concept can capture situations in which an agent controls multiple resources-corresponding to the team members-that cannot communicate. It is known that such equilibrium always exists and it is unique (unless degeneracy) and these properties make it a credible solution concept to be used in real-world applications, especially in security scenarios. Nevertheless, to the best of our knowledge, the Team-maxmin equilibrium is almost completely unexplored in the literature. In this paper, we investigate bounds of (in)efficiency of the Team-maxmin equilibrium w.r.t. the Nash equilibria and w.r.t. the Maxmin equilibrium when the team members can play correlated strategies. Furthermore, we study a number of algorithms to find and/or approximate an equilibrium, discussing their theoretical guarantees and evaluating their performance by using a standard testbed of game instances.
Multi-resource defensive strategies for patrolling games with alarm systems
Jun 07, 2016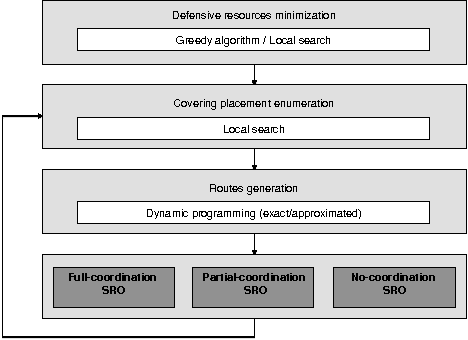
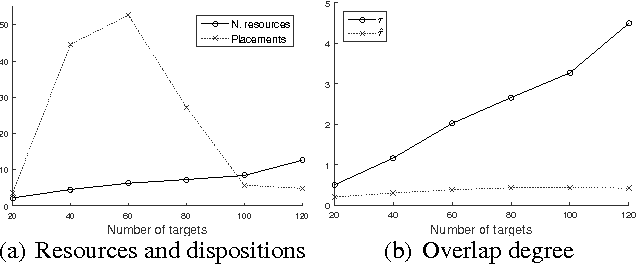
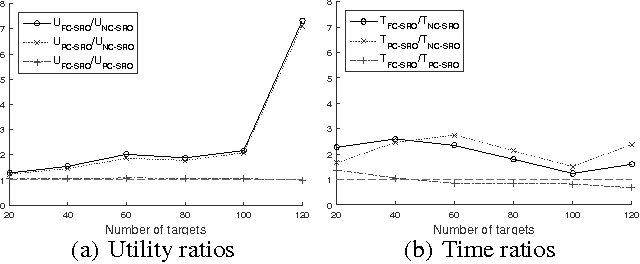
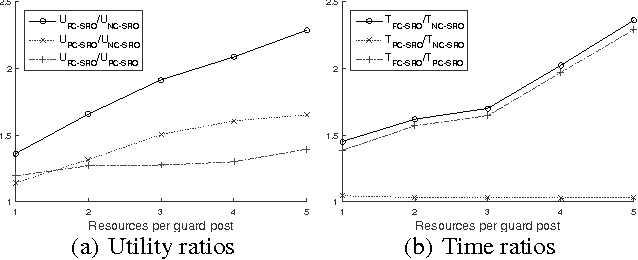
Security Games employ game theoretical tools to derive resource allocation strategies in security domains. Recent works considered the presence of alarm systems, even suffering various forms of uncertainty, and showed that disregarding alarm signals may lead to arbitrarily bad strategies. The central problem with an alarm system, unexplored in other Security Games, is finding the best strategy to respond to alarm signals for each mobile defensive resource. The literature provides results for the basic single-resource case, showing that even in that case the problem is computationally hard. In this paper, we focus on the challenging problem of designing algorithms scaling with multiple resources. First, we focus on finding the minimum number of resources assuring non-null protection to every target. Then, we deal with the computation of multi-resource strategies with different degrees of coordination among resources. For each considered problem, we provide a computational analysis and propose algorithmic methods.
Adversarial patrolling with spatially uncertain alarm signals
Jun 09, 2015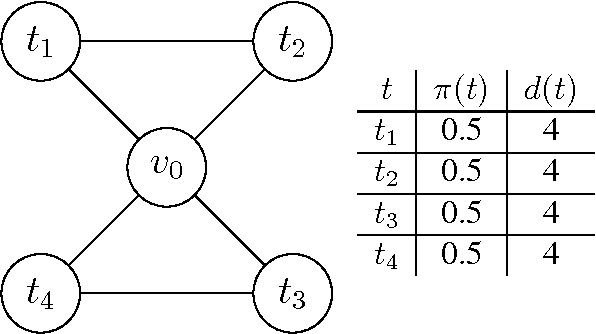
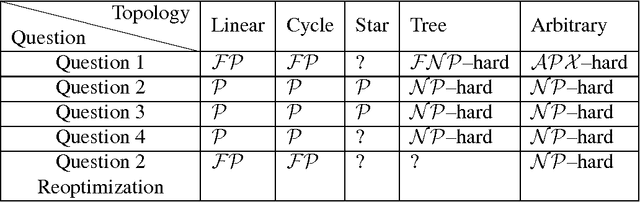
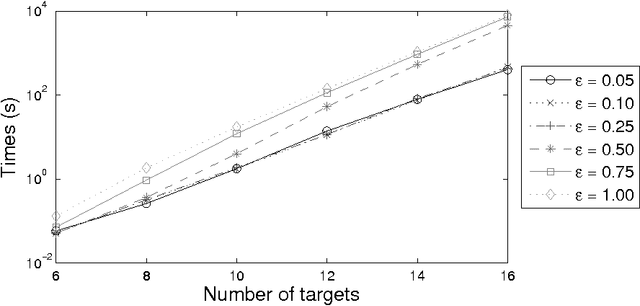
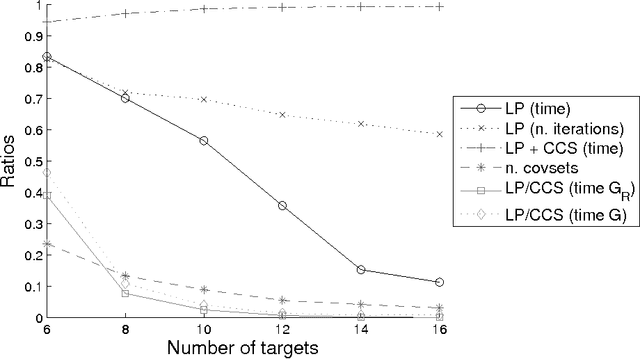
When securing complex infrastructures or large environments, constant surveillance of every area is not affordable. To cope with this issue, a common countermeasure is the usage of cheap but wide-ranged sensors, able to detect suspicious events that occur in large areas, supporting patrollers to improve the effectiveness of their strategies. However, such sensors are commonly affected by uncertainty. In the present paper, we focus on spatially uncertain alarm signals. That is, the alarm system is able to detect an attack but it is uncertain on the exact position where the attack is taking place. This is common when the area to be secured is wide such as in border patrolling and fair site surveillance. We propose, to the best of our knowledge, the first Patrolling Security Game model where a Defender is supported by a spatially uncertain alarm system which non-deterministically generates signals once a target is under attack. We show that finding the optimal strategy in arbitrary graphs is APX-hard even in zero-sum games and we provide two (exponential time) exact algorithms and two (polynomial time) approximation algorithms. Furthermore, we analyse what happens in environments with special topologies, showing that in linear and cycle graphs the optimal patrolling strategy can be found in polynomial time, de facto allowing our algorithms to be used in real-life scenarios, while in trees the problem is NP-hard. Finally, we show that without false positives and missed detections, the best patrolling strategy reduces to stay in a place, wait for a signal, and respond to it at best. This strategy is optimal even with non-negligible missed detection rates, which, unfortunately, affect every commercial alarm system. We evaluate our methods in simulation, assessing both quantitative and qualitative aspects.