 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Constrained Reinforcement Learning Algorithms for Legged Locomotion
Paper and Code
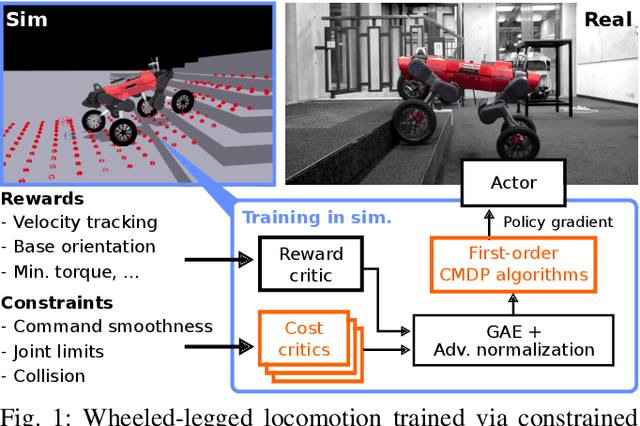
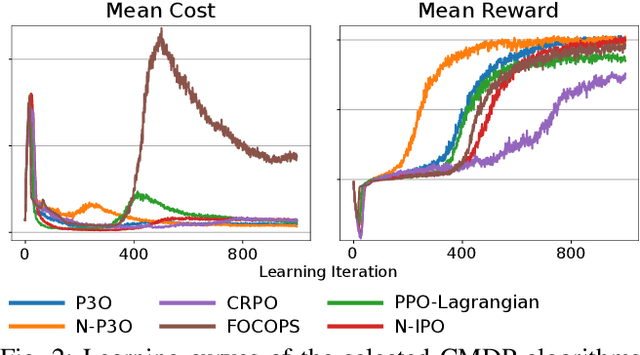
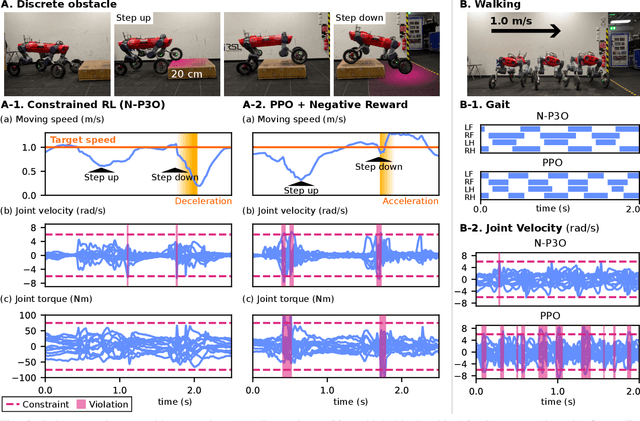
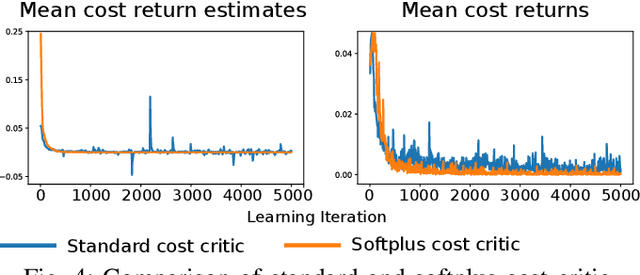
Shifting from traditional control strategies to Deep Reinforcement Learning (RL) for legged robots poses inherent challenges, especially when addressing real-world physical constraints during training. While high-fidelity simulations provide significant benefits, they often bypass these essential physical limitations. In this paper, we experiment with the Constrained Markov Decision Process (CMDP) framework instead of the conventional unconstrained RL for robotic applications. We perform a comparative study of different constrained policy optimization algorithms to identify suitable methods for practical implementation. Our robot experiments demonstrate the critical role of incorporating physical constraints, yielding successful sim-to-real transfers, and reducing operational errors on physical systems. The CMDP formulation streamlines the training process by separately handling constraints from rewards. Our findings underscore the potential of constrained RL for the effective development and deployment of learned controllers in robotics.