 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
DiffSim2Real: Deploying Quadrupedal Locomotion Policies Purely Trained in Differentiable Simulation
Nov 04, 2024
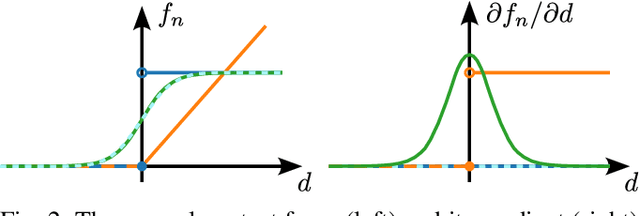

Differentiable simulators provide analytic gradients, enabling more sample-efficient learning algorithms and paving the way for data intensive learning tasks such as learning from images. In this work, we demonstrate that locomotion policies trained with analytic gradients from a differentiable simulator can be successfully transferred to the real world. Typically, simulators that offer informative gradients lack the physical accuracy needed for sim-to-real transfer, and vice-versa. A key factor in our success is a smooth contact model that combines informative gradients with physical accuracy, ensuring effective transfer of learned behaviors. To the best of our knowledge, this is the first time a real quadrupedal robot is able to locomote after training exclusively in a differentiable simulation.
Learning Quadrupedal Locomotion via Differentiable Simulation
Apr 03, 2024



The emergence of differentiable simulators enabling analytic gradient computation has motivated a new wave of learning algorithms that hold the potential to significantly increase sample efficiency over traditional Reinforcement Learning (RL) methods. While recent research has demonstrated performance gains in scenarios with comparatively smooth dynamics and, thus, smooth optimization landscapes, research on leveraging differentiable simulators for contact-rich scenarios, such as legged locomotion, is scarce. This may be attributed to the discontinuous nature of contact, which introduces several challenges to optimizing with analytic gradients. The purpose of this paper is to determine if analytic gradients can be beneficial even in the face of contact. Our investigation focuses on the effects of different soft and hard contact models on the learning process, examining optimization challenges through the lens of contact simulation. We demonstrate the viability of employing analytic gradients to learn physically plausible locomotion skills with a quadrupedal robot using Short-Horizon Actor-Critic (SHAC), a learning algorithm leveraging analytic gradients, and draw a comparison to a state-of-the-art RL algorithm, Proximal Policy Optimization (PPO), to understand the benefits of analytic gradients.