 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Blind Stair Climbing with Legged and Wheeled-Legged Robots
Feb 09, 2024
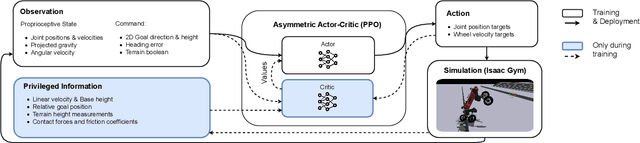


In recent years, legged and wheeled-legged robots have gained prominence for tasks in environments predominantly created for humans across various domains. One significant challenge faced by many of these robots is their limited capability to navigate stairs, which hampers their functionality in multi-story environments. This study proposes a method aimed at addressing this limitation, employing reinforcement learning to develop a versatile controller applicable to a wide range of robots. In contrast to the conventional velocity-based controllers, our approach builds upon a position-based formulation of the RL task, which we show to be vital for stair climbing. Furthermore, the methodology leverages an asymmetric actor-critic structure, enabling the utilization of privileged information from simulated environments during training while eliminating the reliance on exteroceptive sensors during real-world deployment. Another key feature of the proposed approach is the incorporation of a boolean observation within the controller, enabling the activation or deactivation of a stair-climbing mode. We present our results on different quadrupeds and bipedal robots in simulation and showcase how our method allows the balancing robot Ascento to climb 15cm stairs in the real world, a task that was previously impossible for this robot.
Motion Planning for Autonomous Vehicles in the Presence of Uncertainty Using Reinforcement Learning
Oct 01, 2021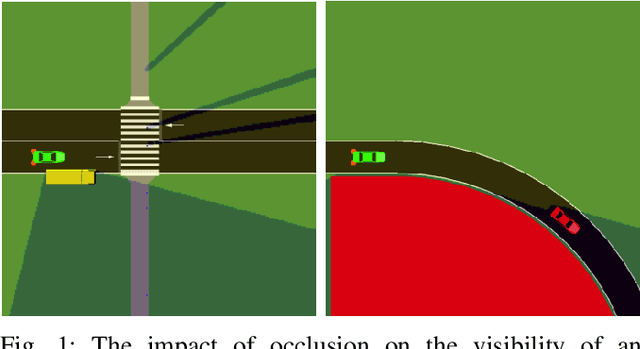
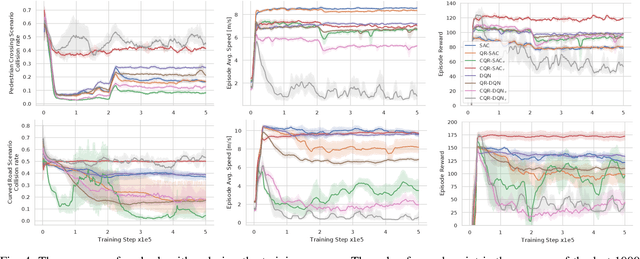
Motion planning under uncertainty is one of the main challenges in developing autonomous driving vehicles. In this work, we focus on the uncertainty in sensing and perception, resulted from a limited field of view, occlusions, and sensing range. This problem is often tackled by considering hypothetical hidden objects in occluded areas or beyond the sensing range to guarantee passive safety. However, this may result in conservative planning and expensive computation, particularly when numerous hypothetical objects need to be considered. We propose a reinforcement learning (RL) based solution to manage uncertainty by optimizing for the worst case outcome. This approach is in contrast to traditional RL, where the agents try to maximize the average expected reward. The proposed approach is built on top of the Distributional RL with its policy optimization maximizing the stochastic outcomes' lower bound. This modification can be applied to a range of RL algorithms. As a proof-of-concept, the approach is applied to two different RL algorithms, Soft Actor-Critic and DQN. The approach is evaluated against two challenging scenarios of pedestrians crossing with occlusion and curved roads with a limited field of view. The algorithm is trained and evaluated using the SUMO traffic simulator. The proposed approach yields much better motion planning behavior compared to conventional RL algorithms and behaves comparably to humans driving style.
Neural Network Based Lidar Gesture Recognition for Realtime Robot Teleoperation
Sep 17, 2021
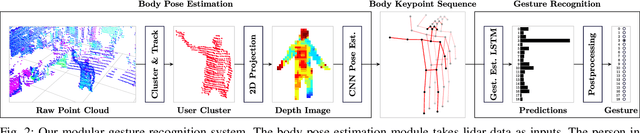
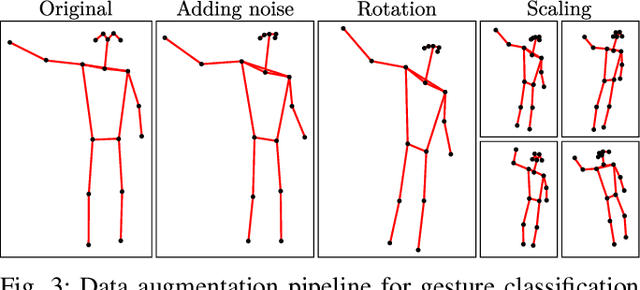
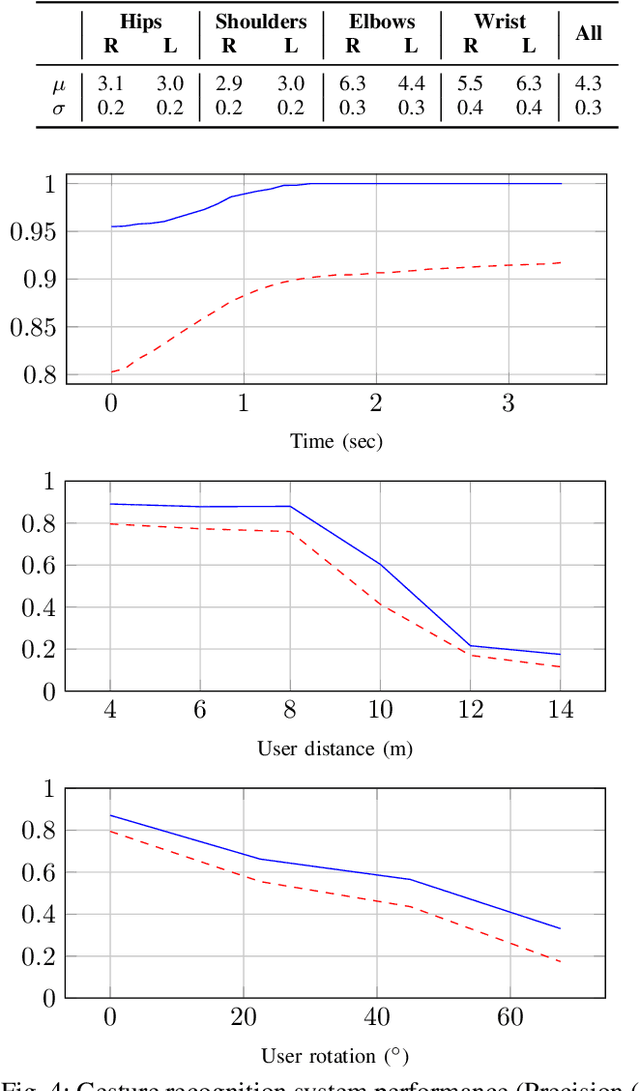
We propose a novel low-complexity lidar gesture recognition system for mobile robot control robust to gesture variation. Our system uses a modular approach, consisting of a pose estimation module and a gesture classifier. Pose estimates are predicted from lidar scans using a Convolutional Neural Network trained using an existing stereo-based pose estimation system. Gesture classification is accomplished using a Long Short-Term Memory network and uses a sequence of estimated body poses as input to predict a gesture. Breaking down the pipeline into two modules reduces the dimensionality of the input, which could be lidar scans, stereo imagery, or any other modality from which body keypoints can be extracted, making our system lightweight and suitable for mobile robot control with limited computing power. The use of lidar contributes to the robustness of the system, allowing it to operate in most outdoor conditions, to be independent of lighting conditions, and for input to be detected 360 degrees around the robot. The lidar-based pose estimator and gesture classifier use data augmentation and automated labeling techniques, requiring a minimal amount of data collection and avoiding the need for manual labeling. We report experimental results for each module of our system and demonstrate its effectiveness by testing it in a real-world robot teleoperation setting.
Navigation Agents for the Visually Impaired: A Sidewalk Simulator and Experiments
Oct 29, 2019


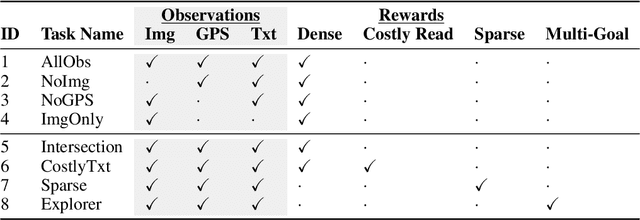
Millions of blind and visually-impaired (BVI) people navigate urban environments every day, using smartphones for high-level path-planning and white canes or guide dogs for local information. However, many BVI people still struggle to travel to new places. In our endeavor to create a navigation assistant for the BVI, we found that existing Reinforcement Learning (RL) environments were unsuitable for the task. This work introduces SEVN, a sidewalk simulation environment and a neural network-based approach to creating a navigation agent. SEVN contains panoramic images with labels for house numbers, doors, and street name signs, and formulations for several navigation tasks. We study the performance of an RL algorithm (PPO) in this setting. Our policy model fuses multi-modal observations in the form of variable resolution images, visible text, and simulated GPS data to navigate to a goal door. We hope that this dataset, simulator, and experimental results will provide a foundation for further research into the creation of agents that can assist members of the BVI community with outdoor navigation.