 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Group Relative Policy Optimization
Feb 05, 2026While Group Relative Policy Optimization (GRPO) has emerged as a scalable framework for critic-free policy learning, extending it to settings with explicit behavioral constraints remains underexplored. We introduce Constrained GRPO, a Lagrangian-based extension of GRPO for constrained policy optimization. Constraints are specified via indicator cost functions, enabling direct optimization of violation rates through a Lagrangian relaxation. We show that a naive multi-component treatment in advantage estimation can break constrained learning: mismatched component-wise standard deviations distort the relative importance of the different objective terms, which in turn corrupts the Lagrangian signal and prevents meaningful constraint enforcement. We formally derive this effect to motivate our scalarized advantage construction that preserves the intended trade-off between reward and constraint terms. Experiments in a toy gridworld confirm the predicted optimization pathology and demonstrate that scalarizing advantages restores stable constraint control. In addition, we evaluate Constrained GRPO on robotics tasks, where it improves constraint satisfaction while increasing task success, establishing a simple and effective recipe for constrained policy optimization in embodied AI domains that increasingly rely on large multimodal foundation models.
Poutine: Vision-Language-Trajectory Pre-Training and Reinforcement Learning Post-Training Enable Robust End-to-End Autonomous Driving
Jun 12, 2025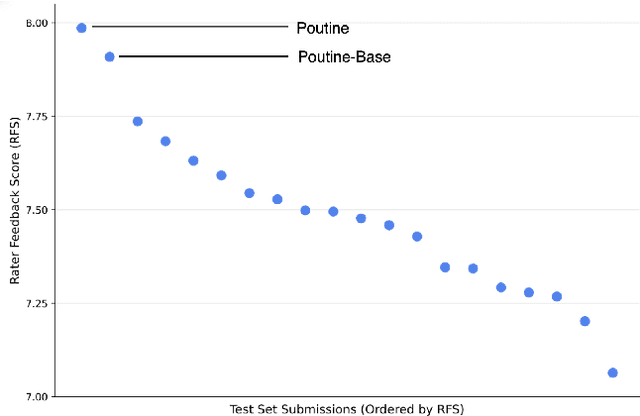



We present Poutine, a 3B-parameter vision-language model (VLM) tailored for end-to-end autonomous driving in long-tail driving scenarios. Poutine is trained in two stages. To obtain strong base driving capabilities, we train Poutine-Base in a self-supervised vision-language-trajectory (VLT) next-token prediction fashion on 83 hours of CoVLA nominal driving and 11 hours of Waymo long-tail driving. Accompanying language annotations are auto-generated with a 72B-parameter VLM. Poutine is obtained by fine-tuning Poutine-Base with Group Relative Policy Optimization (GRPO) using less than 500 preference-labeled frames from the Waymo validation set. We show that both VLT pretraining and RL fine-tuning are critical to attain strong driving performance in the long-tail. Poutine-Base achieves a rater-feedback score (RFS) of 8.12 on the validation set, nearly matching Waymo's expert ground-truth RFS. The final Poutine model achieves an RFS of 7.99 on the official Waymo test set, placing 1st in the 2025 Waymo Vision-Based End-to-End Driving Challenge by a significant margin. These results highlight the promise of scalable VLT pre-training and lightweight RL fine-tuning to enable robust and generalizable autonomy.
VERDI: VLM-Embedded Reasoning for Autonomous Driving
May 21, 2025While autonomous driving (AD) stacks struggle with decision making under partial observability and real-world complexity, human drivers are capable of commonsense reasoning to make near-optimal decisions with limited information. Recent work has attempted to leverage finetuned Vision-Language Models (VLMs) for trajectory planning at inference time to emulate human behavior. Despite their success in benchmark evaluations, these methods are often impractical to deploy (a 70B parameter VLM inference at merely 8 tokens per second requires more than 160G of memory), and their monolithic network structure prohibits safety decomposition. To bridge this gap, we propose VLM-Embedded Reasoning for autonomous Driving (VERDI), a training-time framework that distills the reasoning process and commonsense knowledge of VLMs into the AD stack. VERDI augments modular differentiable end-to-end (e2e) AD models by aligning intermediate module outputs at the perception, prediction, and planning stages with text features explaining the driving reasoning process produced by VLMs. By encouraging alignment in latent space, \textsc{VERDI} enables the modular AD stack to internalize structured reasoning, without incurring the inference-time costs of large VLMs. We demonstrate the effectiveness of our method on the NuScenes dataset and find that VERDI outperforms existing e2e methods that do not embed reasoning by 10% in $\ell_{2}$ distance, while maintaining high inference speed.
Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments
Mar 28, 2025



We introduce Scenario Dreamer, a fully data-driven generative simulator for autonomous vehicle planning that generates both the initial traffic scene - comprising a lane graph and agent bounding boxes - and closed-loop agent behaviours. Existing methods for generating driving simulation environments encode the initial traffic scene as a rasterized image and, as such, require parameter-heavy networks that perform unnecessary computation due to many empty pixels in the rasterized scene. Moreover, we find that existing methods that employ rule-based agent behaviours lack diversity and realism. Scenario Dreamer instead employs a novel vectorized latent diffusion model for initial scene generation that directly operates on the vectorized scene elements and an autoregressive Transformer for data-driven agent behaviour simulation. Scenario Dreamer additionally supports scene extrapolation via diffusion inpainting, enabling the generation of unbounded simulation environments. Extensive experiments show that Scenario Dreamer outperforms existing generative simulators in realism and efficiency: the vectorized scene-generation base model achieves superior generation quality with around 2x fewer parameters, 6x lower generation latency, and 10x fewer GPU training hours compared to the strongest baseline. We confirm its practical utility by showing that reinforcement learning planning agents are more challenged in Scenario Dreamer environments than traditional non-generative simulation environments, especially on long and adversarial driving environments.
CtRL-Sim: Reactive and Controllable Driving Agents with Offline Reinforcement Learning
Mar 29, 2024



Evaluating autonomous vehicle stacks (AVs) in simulation typically involves replaying driving logs from real-world recorded traffic. However, agents replayed from offline data do not react to the actions of the AV, and their behaviour cannot be easily controlled to simulate counterfactual scenarios. Existing approaches have attempted to address these shortcomings by proposing methods that rely on heuristics or learned generative models of real-world data but these approaches either lack realism or necessitate costly iterative sampling procedures to control the generated behaviours. In this work, we take an alternative approach and propose CtRL-Sim, a method that leverages return-conditioned offline reinforcement learning within a physics-enhanced Nocturne simulator to efficiently generate reactive and controllable traffic agents. Specifically, we process real-world driving data through the Nocturne simulator to generate a diverse offline reinforcement learning dataset, annotated with various reward terms. With this dataset, we train a return-conditioned multi-agent behaviour model that allows for fine-grained manipulation of agent behaviours by modifying the desired returns for the various reward components. This capability enables the generation of a wide range of driving behaviours beyond the scope of the initial dataset, including those representing adversarial behaviours. We demonstrate that CtRL-Sim can efficiently generate diverse and realistic safety-critical scenarios while providing fine-grained control over agent behaviours. Further, we show that fine-tuning our model on simulated safety-critical scenarios generated by our model enhances this controllability.
Direct Behavior Specification via Constrained Reinforcement Learning
Jan 19, 2022
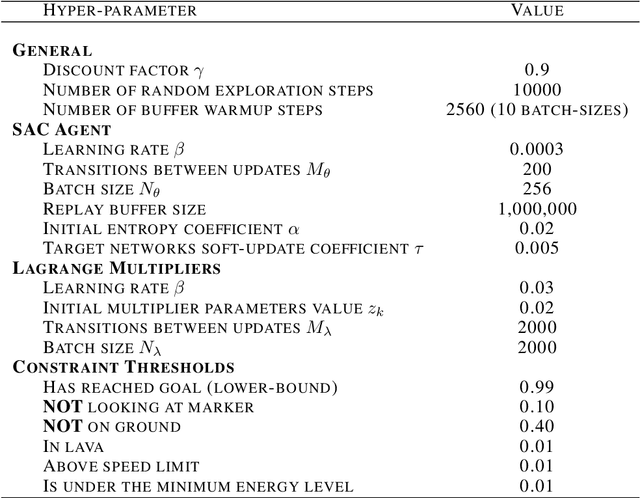

The standard formulation of Reinforcement Learning lacks a practical way of specifying what are admissible and forbidden behaviors. Most often, practitioners go about the task of behavior specification by manually engineering the reward function, a counter-intuitive process that requires several iterations and is prone to reward hacking by the agent. In this work, we argue that constrained RL, which has almost exclusively been used for safe RL, also has the potential to significantly reduce the amount of work spent for reward specification in applied RL projects. To this end, we propose to specify behavioral preferences in the CMDP framework and to use Lagrangian methods to automatically weigh each of these behavioral constraints. Specifically, we investigate how CMDPs can be adapted to solve goal-based tasks while adhering to several constraints simultaneously. We evaluate this framework on a set of continuous control tasks relevant to the application of Reinforcement Learning for NPC design in video games.
Navigation Agents for the Visually Impaired: A Sidewalk Simulator and Experiments
Oct 29, 2019


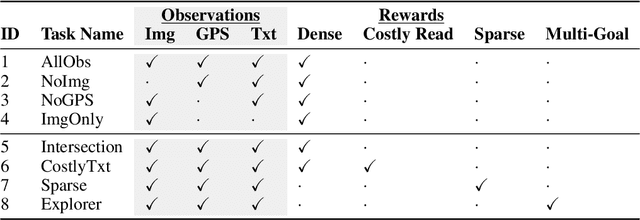
Millions of blind and visually-impaired (BVI) people navigate urban environments every day, using smartphones for high-level path-planning and white canes or guide dogs for local information. However, many BVI people still struggle to travel to new places. In our endeavor to create a navigation assistant for the BVI, we found that existing Reinforcement Learning (RL) environments were unsuitable for the task. This work introduces SEVN, a sidewalk simulation environment and a neural network-based approach to creating a navigation agent. SEVN contains panoramic images with labels for house numbers, doors, and street name signs, and formulations for several navigation tasks. We study the performance of an RL algorithm (PPO) in this setting. Our policy model fuses multi-modal observations in the form of variable resolution images, visible text, and simulated GPS data to navigate to a goal door. We hope that this dataset, simulator, and experimental results will provide a foundation for further research into the creation of agents that can assist members of the BVI community with outdoor navigation.
A Survey of Mobile Computing for the Visually Impaired
Nov 27, 2018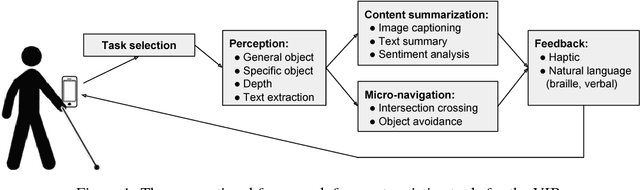
The number of visually impaired or blind (VIB) people in the world is estimated at several hundred million. Based on a series of interviews with the VIB and developers of assistive technology, this paper provides a survey of machine-learning based mobile applications and identifies the most relevant applications. We discuss the functionality of these apps, how they align with the needs and requirements of the VIB users, and how they can be improved with techniques such as federated learning and model compression. As a result of this study we identify promising future directions of research in mobile perception, micro-navigation, and content-summarization.