 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManagerTower: Aggregating the Insights of Uni-Modal Experts for Vision-Language Representation Learning
Paper and Code
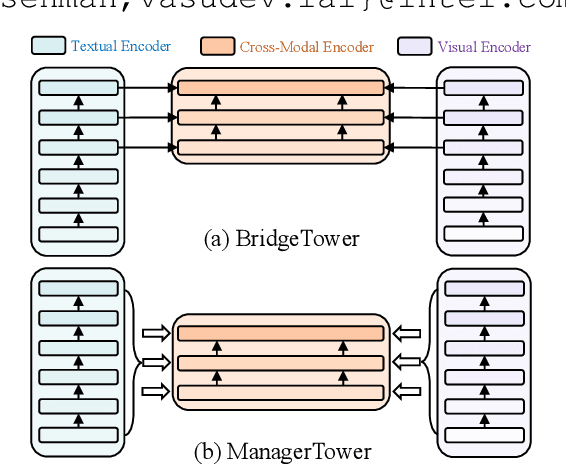
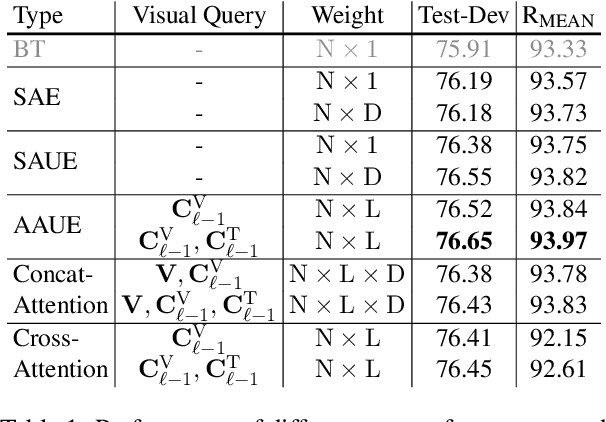
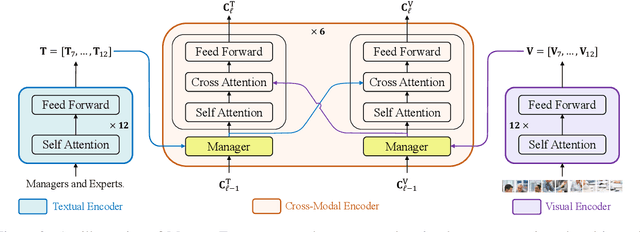
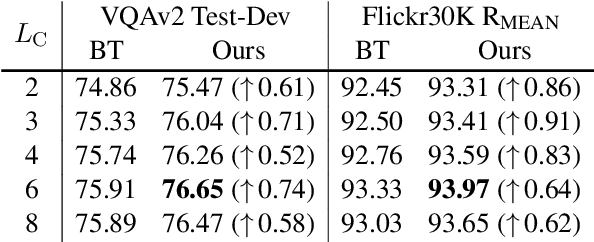
Two-Tower Vision-Language (VL) models have shown promising improvements on various downstream VL tasks. Although the most advanced work improves performance by building bridges between encoders, it suffers from ineffective layer-by-layer utilization of uni-modal representations and cannot flexibly exploit different levels of uni-modal semantic knowledge. In this work, we propose ManagerTower, a novel VL model architecture that gathers and combines the insights of pre-trained uni-modal experts at different levels. The managers introduced in each cross-modal layer can adaptively aggregate uni-modal semantic knowledge to facilitate more comprehensive cross-modal alignment and fusion. ManagerTower outperforms previous strong baselines both with and without Vision-Language Pre-training (VLP). With only 4M VLP data, ManagerTower achieves superior performances on various downstream VL tasks, especially 79.15% accuracy on VQAv2 Test-Std, 86.56% IR@1 and 95.64% TR@1 on Flickr30K. Code and checkpoints are available at https://github.com/LooperXX/ManagerTower.