 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridge-Tower: Building Bridges Between Encoders in Vision-Language Representation Learning
Paper and Code
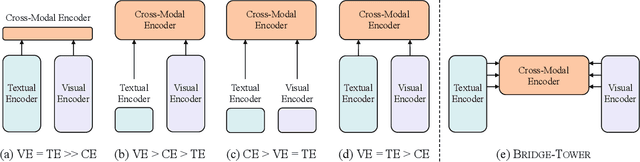


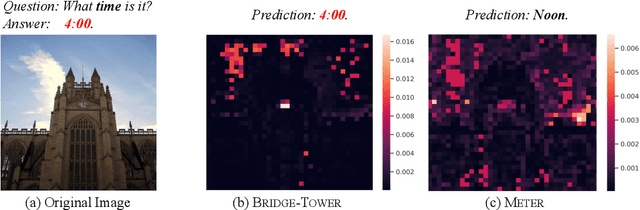
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a cross-modal encoder, or feed the last-layer uni-modal features directly into the top cross-modal encoder, ignoring the semantic information at the different levels in the deep uni-modal encoders. Both approaches possibly restrict vision-language representation learning and limit model performance. In this paper, we introduce multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables comprehensive bottom-up interactions between visual and textual representations at different semantic levels, resulting in more effective cross-modal alignment and fusion. Our proposed Bridge-Tower, pre-trained with only $4$M images, achieves state-of-the-art performance on various downstream vision-language tasks. On the VQAv2 test-std set, Bridge-Tower achieves an accuracy of $78.73\%$, outperforming the previous state-of-the-art METER model by $1.09\%$ with the same pre-training data and almost no additional parameters and computational cost. Notably, when further scaling the model, Bridge-Tower achieves an accuracy of $81.15\%$, surpassing models that are pre-trained on orders-of-magnitude larger datasets. Code is available at https://github.com/microsoft/BridgeTower.