 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding
Nov 06, 2024Large language models (LLMs) have shown impressive capabilities, but still struggle with complex reasoning tasks requiring multiple steps. While prompt-based methods like Chain-of-Thought (CoT) can improve LLM reasoning at inference time, optimizing reasoning capabilities during training remains challenging. We introduce LaTent Reasoning Optimization (LaTRO), a principled framework that formulates reasoning as sampling from a latent distribution and optimizes it via variational approaches. LaTRO enables LLMs to concurrently improve both their reasoning process and ability to evaluate reasoning quality, without requiring external feedback or reward models. We validate LaTRO through experiments on GSM8K and ARC-Challenge datasets using multiple model architectures. On GSM8K, LaTRO improves zero-shot accuracy by an average of 12.5% over base models and 9.6% over supervised fine-tuning across Phi-3.5-mini, Mistral-7B, and Llama-3.1-8B. Our findings suggest that pre-trained LLMs possess latent reasoning capabilities that can be unlocked and enhanced through our proposed optimization approach in a self-improvement manner. The code of LaTRO is available at \url{https://github.com/SalesforceAIResearch/LaTRO}.
Distill-SynthKG: Distilling Knowledge Graph Synthesis Workflow for Improved Coverage and Efficiency
Oct 22, 2024



Knowledge graphs (KGs) generated by large language models (LLMs) are becoming increasingly valuable for Retrieval-Augmented Generation (RAG) applications that require knowledge-intensive reasoning. However, existing KG extraction methods predominantly rely on prompt-based approaches, which are inefficient for processing large-scale corpora. These approaches often suffer from information loss, particularly with long documents, due to the lack of specialized design for KG construction. Additionally, there is a gap in evaluation datasets and methodologies for ontology-free KG construction. To overcome these limitations, we propose SynthKG, a multi-step, document-level ontology-free KG synthesis workflow based on LLMs. By fine-tuning a smaller LLM on the synthesized document-KG pairs, we streamline the multi-step process into a single-step KG generation approach called Distill-SynthKG, substantially reducing the number of LLM inference calls. Furthermore, we re-purpose existing question-answering datasets to establish KG evaluation datasets and introduce new evaluation metrics. Using KGs produced by Distill-SynthKG, we also design a novel graph-based retrieval framework for RAG. Experimental results demonstrate that Distill-SynthKG not only surpasses all baseline models in KG quality -- including models up to eight times larger -- but also consistently excels in retrieval and question-answering tasks. Our proposed graph retrieval framework also outperforms all KG-retrieval methods across multiple benchmark datasets. We release the SynthKG dataset and Distill-SynthKG model publicly to support further research and development.
BOLAA: Benchmarking and Orchestrating LLM-augmented Autonomous Agents
Aug 11, 2023The massive successes of large language models (LLMs) encourage the emerging exploration of LLM-augmented Autonomous Agents (LAAs). An LAA is able to generate actions with its core LLM and interact with environments, which facilitates the ability to resolve complex tasks by conditioning on past interactions such as observations and actions. Since the investigation of LAA is still very recent, limited explorations are available. Therefore, we provide a comprehensive comparison of LAA in terms of both agent architectures and LLM backbones. Additionally, we propose a new strategy to orchestrate multiple LAAs such that each labor LAA focuses on one type of action, \textit{i.e.} BOLAA, where a controller manages the communication among multiple agents. We conduct simulations on both decision-making and multi-step reasoning environments, which comprehensively justify the capacity of LAAs. Our performance results provide quantitative suggestions for designing LAA architectures and the optimal choice of LLMs, as well as the compatibility of both. We release our implementation code of LAAs to the public at \url{https://github.com/salesforce/BOLAA}.
Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization
Aug 04, 2023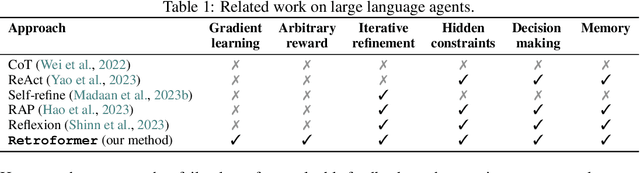
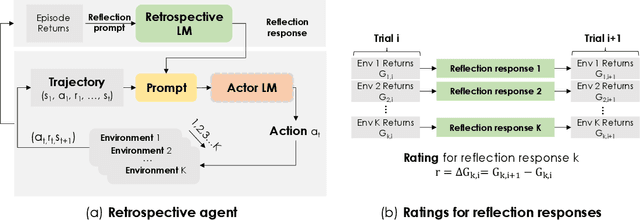
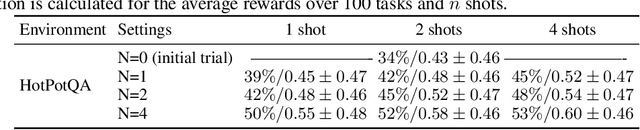
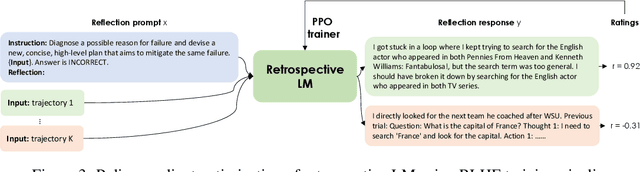
Recent months have seen the emergence of a powerful new trend in which large language models (LLMs) are augmented to become autonomous language agents capable of performing objective oriented multi-step tasks on their own, rather than merely responding to queries from human users. Most existing language agents, however, are not optimized using environment-specific rewards. Although some agents enable iterative refinement through verbal feedback, they do not reason and plan in ways that are compatible with gradient-based learning from rewards. This paper introduces a principled framework for reinforcing large language agents by learning a retrospective model, which automatically tunes the language agent prompts from environment feedback through policy gradient. Specifically, our proposed agent architecture learns from rewards across multiple environments and tasks, for fine-tuning a pre-trained language model which refines the language agent prompt by summarizing the root cause of prior failed attempts and proposing action plans. Experimental results on various tasks demonstrate that the language agents improve over time and that our approach considerably outperforms baselines that do not properly leverage gradients from the environment. This demonstrates that using policy gradient optimization to improve language agents, for which we believe our work is one of the first, seems promising and can be applied to optimize other models in the agent architecture to enhance agent performances over time.
REX: Rapid Exploration and eXploitation for AI Agents
Jul 18, 2023



In this paper, we propose an enhanced approach for Rapid Exploration and eXploitation for AI Agents called REX. Existing AutoGPT-style techniques have inherent limitations, such as a heavy reliance on precise descriptions for decision-making, and the lack of a systematic approach to leverage try-and-fail procedures akin to traditional Reinforcement Learning (RL). REX introduces an additional layer of rewards and integrates concepts similar to Upper Confidence Bound (UCB) scores, leading to more robust and efficient AI agent performance. This approach has the advantage of enabling the utilization of offline behaviors from logs and allowing seamless integration with existing foundation models while it does not require any model fine-tuning. Through comparative analysis with existing methods such as Chain-of-Thoughts(CoT) and Reasoning viA Planning(RAP), REX-based methods demonstrate comparable performance and, in certain cases, even surpass the results achieved by these existing techniques. Notably, REX-based methods exhibit remarkable reductions in execution time, enhancing their practical applicability across a diverse set of scenarios.