 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and accurate factorized neural transducer for text adaption of end-to-end speech recognition models
Dec 05, 2022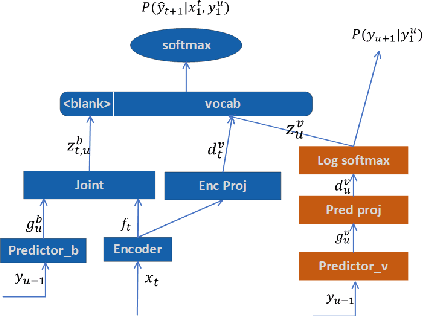
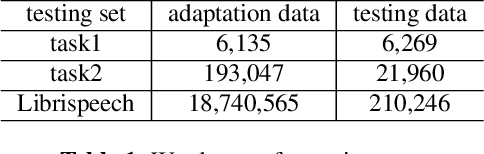
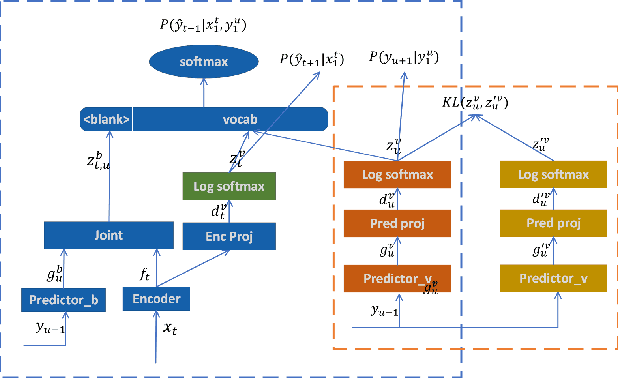
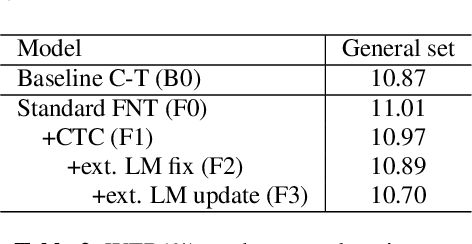
Neural transducer is now the most popular end-to-end model for speech recognition, due to its naturally streaming ability. However, it is challenging to adapt it with text-only data. Factorized neural transducer (FNT) model was proposed to mitigate this problem. The improved adaptation ability of FNT on text-only adaptation data came at the cost of lowered accuracy compared to the standard neural transducer model. We propose several methods to improve the performance of the FNT model. They are: adding CTC criterion during training, adding KL divergence loss during adaptation, using a pre-trained language model to seed the vocabulary predictor, and an efficient adaptation approach by interpolating the vocabulary predictor with the n-gram language model. A combination of these approaches results in a relative word-error-rate reduction of 9.48\% from the standard FNT model. Furthermore, n-gram interpolation with the vocabulary predictor improves the adaptation speed hugely with satisfactory adaptation performance.
Towards Contextual Spelling Correction for Customization of End-to-end Speech Recognition Systems
Mar 02, 2022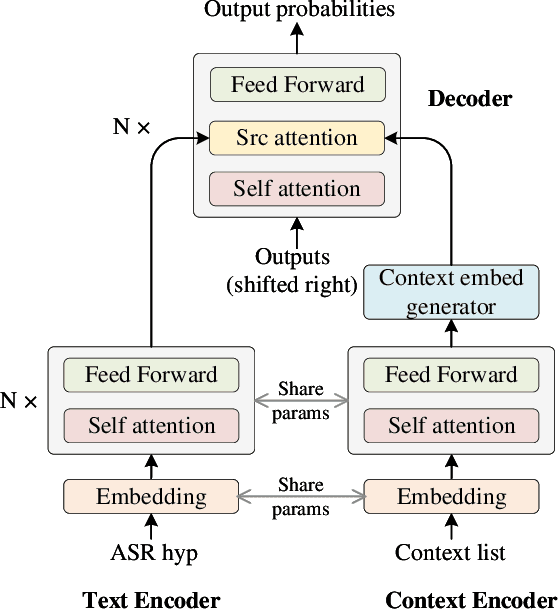
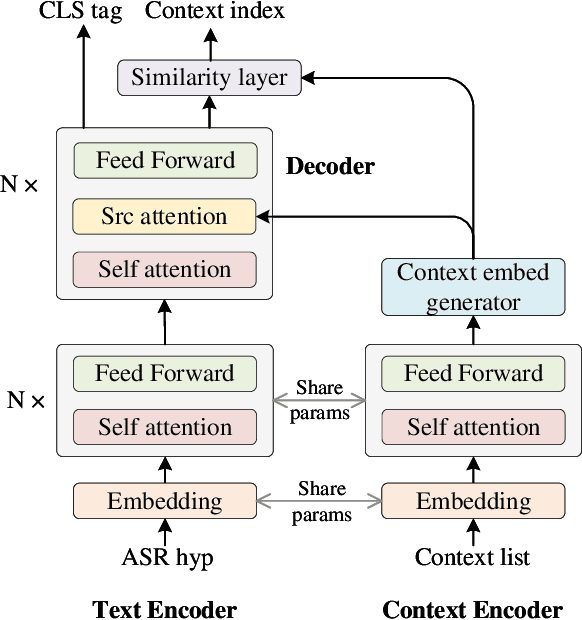
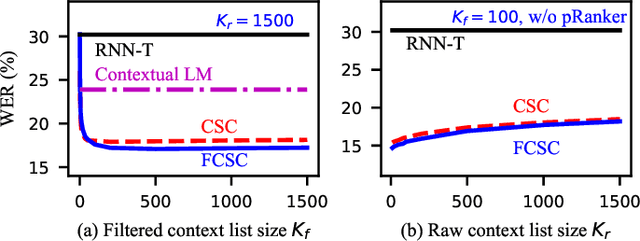
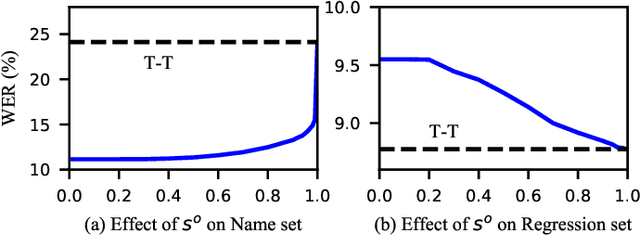
Contextual biasing is an important and challenging task for end-to-end automatic speech recognition (ASR) systems, which aims to achieve better recognition performance by biasing the ASR system to particular context phrases such as person names, music list, proper nouns, etc. Existing methods mainly include contextual LM biasing and adding bias encoder into end-to-end ASR models. In this work, we introduce a novel approach to do contextual biasing by adding a contextual spelling correction model on top of the end-to-end ASR system. We incorporate contextual information into a sequence-to-sequence spelling correction model with a shared context encoder. Our proposed model includes two different mechanisms: autoregressive (AR) and non-autoregressive (NAR). We propose filtering algorithms to handle large-size context lists, and performance balancing mechanisms to control the biasing degree of the model. We demonstrate the proposed model is a general biasing solution which is domain-insensitive and can be adopted in different scenarios. Experiments show that the proposed method achieves as much as 51% relative word error rate (WER) reduction over ASR system and outperforms traditional biasing methods. Compared to the AR solution, the proposed NAR model reduces model size by 43.2% and speeds up inference by 2.1 times.