 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and accurate factorized neural transducer for text adaption of end-to-end speech recognition models
Dec 05, 2022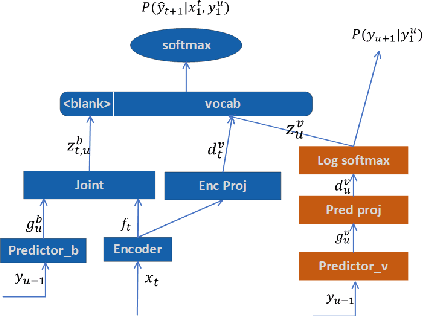
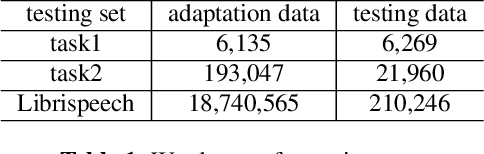
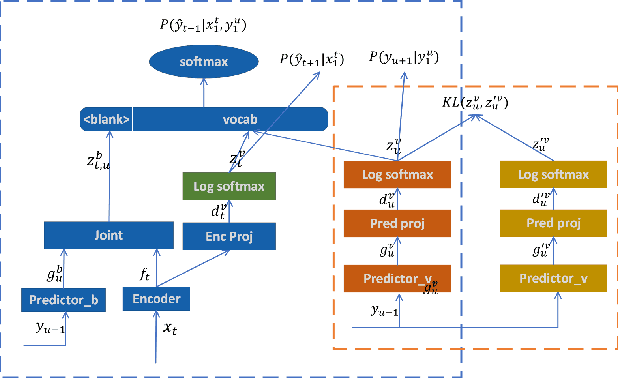
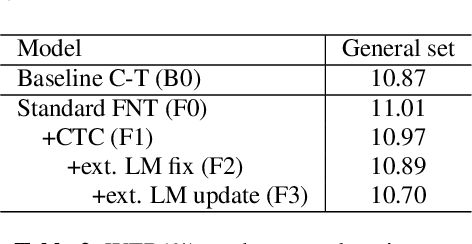
Neural transducer is now the most popular end-to-end model for speech recognition, due to its naturally streaming ability. However, it is challenging to adapt it with text-only data. Factorized neural transducer (FNT) model was proposed to mitigate this problem. The improved adaptation ability of FNT on text-only adaptation data came at the cost of lowered accuracy compared to the standard neural transducer model. We propose several methods to improve the performance of the FNT model. They are: adding CTC criterion during training, adding KL divergence loss during adaptation, using a pre-trained language model to seed the vocabulary predictor, and an efficient adaptation approach by interpolating the vocabulary predictor with the n-gram language model. A combination of these approaches results in a relative word-error-rate reduction of 9.48\% from the standard FNT model. Furthermore, n-gram interpolation with the vocabulary predictor improves the adaptation speed hugely with satisfactory adaptation performance.
Advances in Online Audio-Visual Meeting Transcription
Dec 10, 2019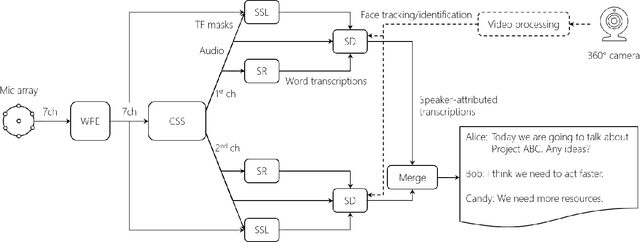

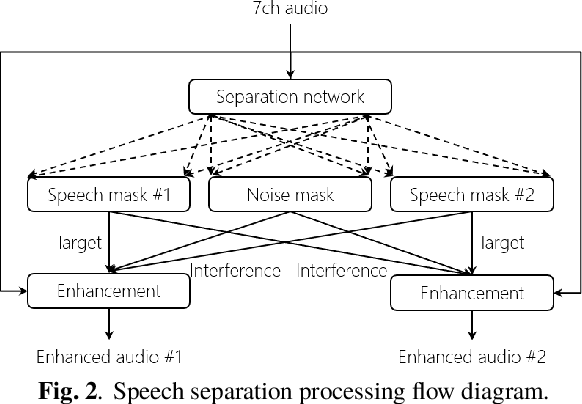
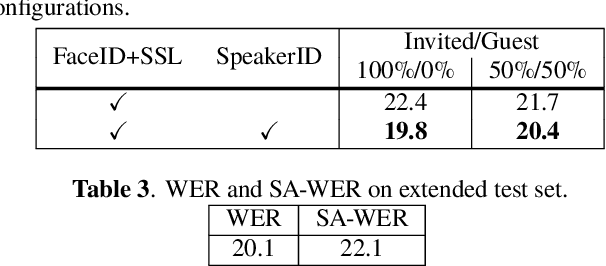
This paper describes a system that generates speaker-annotated transcripts of meetings by using a microphone array and a 360-degree camera. The hallmark of the system is its ability to handle overlapped speech, which has been an unsolved problem in realistic settings for over a decade. We show that this problem can be addressed by using a continuous speech separation approach. In addition, we describe an online audio-visual speaker diarization method that leverages face tracking and identification, sound source localization, speaker identification, and, if available, prior speaker information for robustness to various real world challenges. All components are integrated in a meeting transcription framework called SRD, which stands for "separate, recognize, and diarize". Experimental results using recordings of natural meetings involving up to 11 attendees are reported. The continuous speech separation improves a word error rate (WER) by 16.1% compared with a highly tuned beamformer. When a complete list of meeting attendees is available, the discrepancy between WER and speaker-attributed WER is only 1.0%, indicating accurate word-to-speaker association. This increases marginally to 1.6% when 50% of the attendees are unknown to the system.