 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevising the Problem of Partial Labels from the Perspective of CNNs' Robustness
Jul 24, 2024


Convolutional neural networks (CNNs) have gained increasing popularity and versatility in recent decades, finding applications in diverse domains. These remarkable achievements are greatly attributed to the support of extensive datasets with precise labels. However, annotating image datasets is intricate and complex, particularly in the case of multi-label datasets. Hence, the concept of partial-label setting has been proposed to reduce annotation costs, and numerous corresponding solutions have been introduced. The evaluation methods for these existing solutions have been primarily based on accuracy. That is, their performance is assessed by their predictive accuracy on the test set. However, we insist that such an evaluation is insufficient and one-sided. On one hand, since the quality of the test set has not been evaluated, the assessment results are unreliable. On the other hand, the partial-label problem may also be raised by undergoing adversarial attacks. Therefore, incorporating robustness into the evaluation system is crucial. For this purpose, we first propose two attack models to generate multiple partial-label datasets with varying degrees of label missing rates. Subsequently, we introduce a lightweight partial-label solution using pseudo-labeling techniques and a designed loss function. Then, we employ D-Score to analyze both the proposed and existing methods to determine whether they can enhance robustness while improving accuracy. Extensive experimental results demonstrate that while certain methods may improve accuracy, the enhancement in robustness is not significant, and in some cases, it even diminishes.
SwarmBrain: Embodied agent for real-time strategy game StarCraft II via large language models
Jan 31, 2024Large language models (LLMs) have recently garnered significant accomplishments in various exploratory tasks, even surpassing the performance of traditional reinforcement learning-based methods that have historically dominated the agent-based field. The purpose of this paper is to investigate the efficacy of LLMs in executing real-time strategy war tasks within the StarCraft II gaming environment. In this paper, we introduce SwarmBrain, an embodied agent leveraging LLM for real-time strategy implementation in the StarCraft II game environment. The SwarmBrain comprises two key components: 1) a Overmind Intelligence Matrix, powered by state-of-the-art LLMs, is designed to orchestrate macro-level strategies from a high-level perspective. This matrix emulates the overarching consciousness of the Zerg intelligence brain, synthesizing strategic foresight with the aim of allocating resources, directing expansion, and coordinating multi-pronged assaults. 2) a Swarm ReflexNet, which is agile counterpart to the calculated deliberation of the Overmind Intelligence Matrix. Due to the inherent latency in LLM reasoning, the Swarm ReflexNet employs a condition-response state machine framework, enabling expedited tactical responses for fundamental Zerg unit maneuvers. In the experimental setup, SwarmBrain is in control of the Zerg race in confrontation with an Computer-controlled Terran adversary. Experimental results show the capacity of SwarmBrain to conduct economic augmentation, territorial expansion, and tactical formulation, and it shows the SwarmBrain is capable of achieving victory against Computer players set at different difficulty levels.
Towards Imbalanced Large Scale Multi-label Classification with Partially Annotated Labels
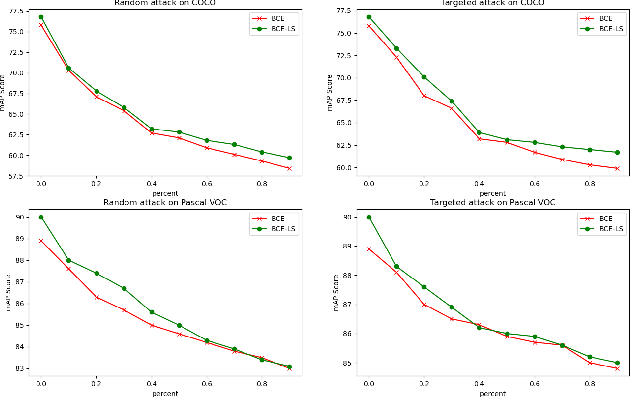
Jul 31, 2023Multi-label classification is a widely encountered problem in daily life, where an instance can be associated with multiple classes. In theory, this is a supervised learning method that requires a large amount of labeling. However, annotating data is time-consuming and may be infeasible for huge labeling spaces. In addition, label imbalance can limit the performance of multi-label classifiers, especially when some labels are missing. Therefore, it is meaningful to study how to train neural networks using partial labels. In this work, we address the issue of label imbalance and investigate how to train classifiers using partial labels in large labeling spaces. First, we introduce the pseudo-labeling technique, which allows commonly adopted networks to be applied in partially labeled settings without the need for additional complex structures. Then, we propose a novel loss function that leverages statistical information from existing datasets to effectively alleviate the label imbalance problem. In addition, we design a dynamic training scheme to reduce the dimension of the labeling space and further mitigate the imbalance. Finally, we conduct extensive experiments on some publicly available multi-label datasets such as COCO, NUS-WIDE, CUB, and Open Images to demonstrate the effectiveness of the proposed approach. The results show that our approach outperforms several state-of-the-art methods, and surprisingly, in some partial labeling settings, our approach even exceeds the methods trained with full labels.
D-Score: A White-Box Diagnosis Score for CNNs Based on Mutation Operators
Apr 03, 2023Convolutional neural networks (CNNs) have been widely applied in many safety-critical domains, such as autonomous driving and medical diagnosis. However, concerns have been raised with respect to the trustworthiness of these models: The standard testing method evaluates the performance of a model on a test set, while low-quality and insufficient test sets can lead to unreliable evaluation results, which can have unforeseeable consequences. Therefore, how to comprehensively evaluate CNNs and, based on the evaluation results, how to enhance their trustworthiness are the key problems to be urgently addressed. Prior work has used mutation tests to evaluate the test sets of CNNs. However, the evaluation scores are black boxes and not explicit enough for what is being tested. In this paper, we propose a white-box diagnostic approach that uses mutation operators and image transformation to calculate the feature and attention distribution of the model and further present a diagnosis score, namely D-Score, to reflect the model's robustness and fitness to a dataset. We also propose a D-Score based data augmentation method to enhance the CNN's performance to translations and rescalings. Comprehensive experiments on two widely used datasets and three commonly adopted CNNs demonstrate the effectiveness of our approach.
TRScore: A Novel GPT-based Readability Scorer for ASR Segmentation and Punctuation model evaluation and selection
Oct 27, 2022
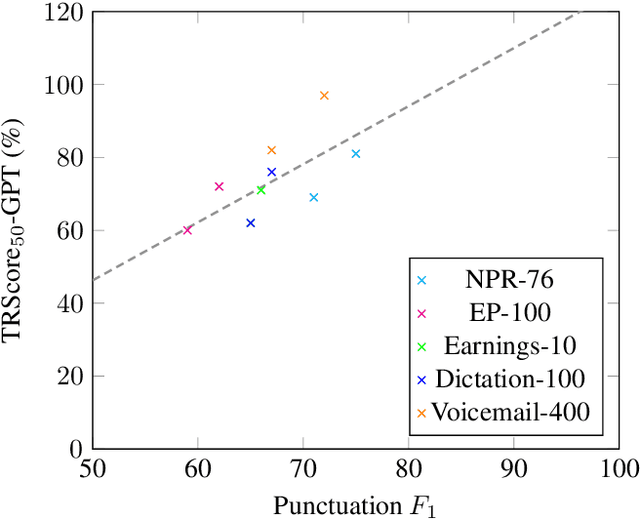
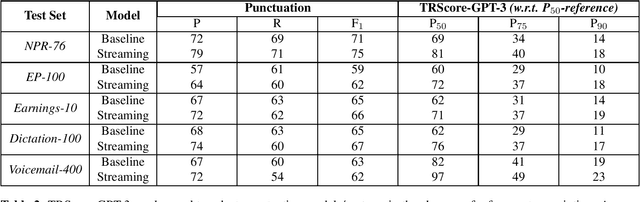
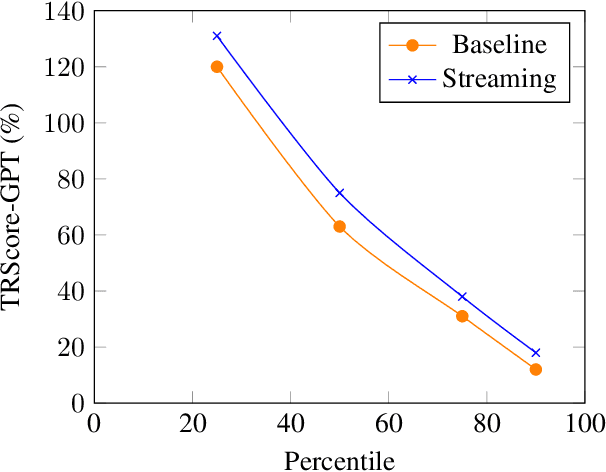
Punctuation and Segmentation are key to readability in Automatic Speech Recognition (ASR), often evaluated using F1 scores that require high-quality human transcripts and do not reflect readability well. Human evaluation is expensive, time-consuming, and suffers from large inter-observer variability, especially in conversational speech devoid of strict grammatical structures. Large pre-trained models capture a notion of grammatical structure. We present TRScore, a novel readability measure using the GPT model to evaluate different segmentation and punctuation systems. We validate our approach with human experts. Additionally, our approach enables quantitative assessment of text post-processing techniques such as capitalization, inverse text normalization (ITN), and disfluency on overall readability, which traditional word error rate (WER) and slot error rate (SER) metrics fail to capture. TRScore is strongly correlated to traditional F1 and human readability scores, with Pearson's correlation coefficients of 0.67 and 0.98, respectively. It also eliminates the need for human transcriptions for model selection.
Erase and Restore: Simple, Accurate and Resilient Detection of $L_2$ Adversarial Examples
Jan 01, 2020
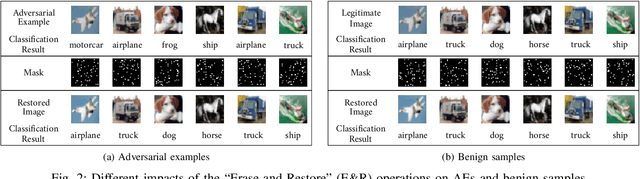
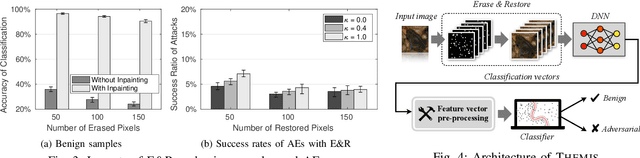
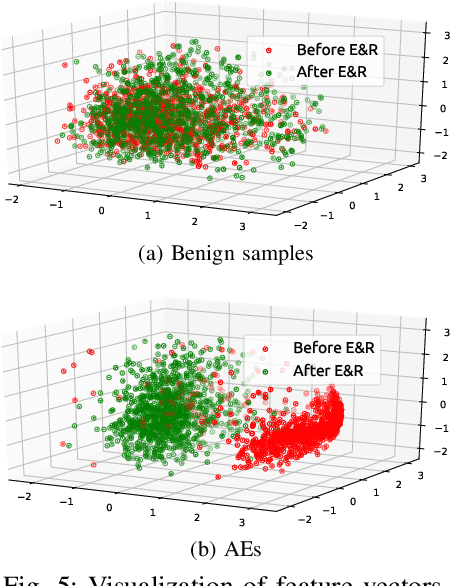
By adding carefully crafted perturbations to input images, adversarial examples (AEs) can be generated to mislead neural-network-based image classifiers. $L_2$ adversarial perturbations by Carlini and Wagner (CW) are regarded as among the most effective attacks. While many countermeasures against AEs have been proposed, detection of adaptive CW $L_2$ AEs has been very inaccurate. Our observation is that those deliberately altered pixels in an $L_2$ AE, altogether, exert their malicious influence. By randomly erasing some pixels from an $L_2$ AE and then restoring it with an inpainting technique, such an AE, before and after the steps, tends to have different classification results, while a benign sample does not show this symptom. Based on this, we propose a novel AE detection technique, Erase and Restore (E\&R), that exploits the limitation of $L_2$ attacks. On two popular image datasets, CIFAR-10 and ImageNet, our experiments show that the proposed technique is able to detect over 98% of the AEs generated by CW and other $L_2$ algorithms and has a very low false positive rate on benign images. Moreover, our approach demonstrate strong resilience to adaptive attacks. While adding noises and inpainting each have been well studied, by combining them together, we deliver a simple, accurate and resilient detection technique against adaptive $L_2$ AEs.
Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs
Aug 08, 2018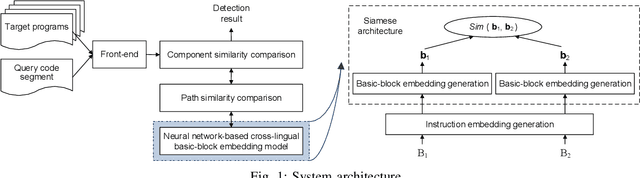
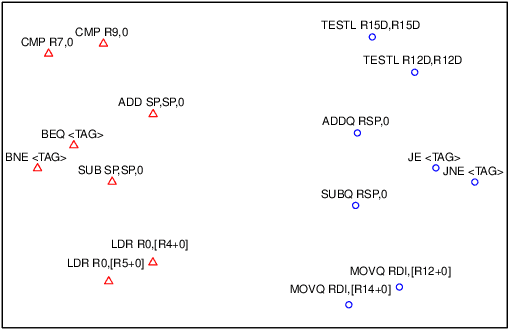
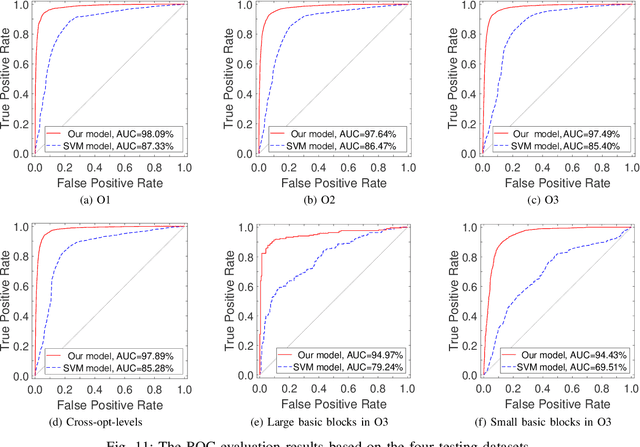
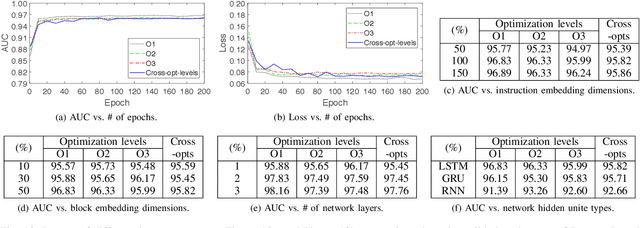
Binary code analysis allows analyzing binary code without having access to the corresponding source code. A binary, after disassembly, is expressed in an assembly language. This inspires us to approach binary analysis by leveraging ideas and techniques from Natural Language Processing (NLP), a rich area focused on processing text of various natural languages. We notice that binary code analysis and NLP share a lot of analogical topics, such as semantics extraction, summarization, and classification. This work utilizes these ideas to address two important code similarity comparison problems. (I) Given a pair of basic blocks for different instruction set architectures (ISAs), determining whether their semantics is similar or not; and (II) given a piece of code of interest, determining if it is contained in another piece of assembly code for a different ISA. The solutions to these two problems have many applications, such as cross-architecture vulnerability discovery and code plagiarism detection. We implement a prototype system INNEREYE and perform a comprehensive evaluation. A comparison between our approach and existing approaches to Problem I shows that our system outperforms them in terms of accuracy, efficiency and scalability. And the case studies utilizing the system demonstrate that our solution to Problem II is effective. Moreover, this research showcases how to apply ideas and techniques from NLP to large-scale binary code analysis.