 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErase and Restore: Simple, Accurate and Resilient Detection of $L_2$ Adversarial Examples
Paper and Code

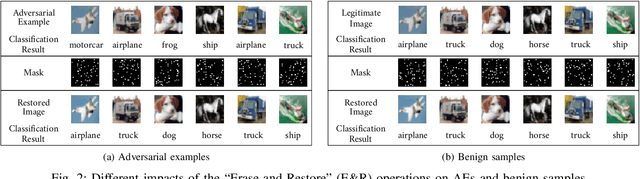
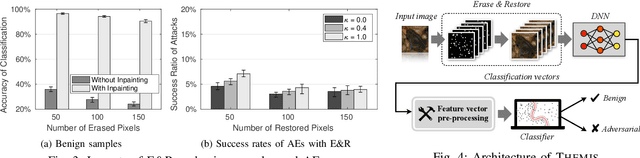
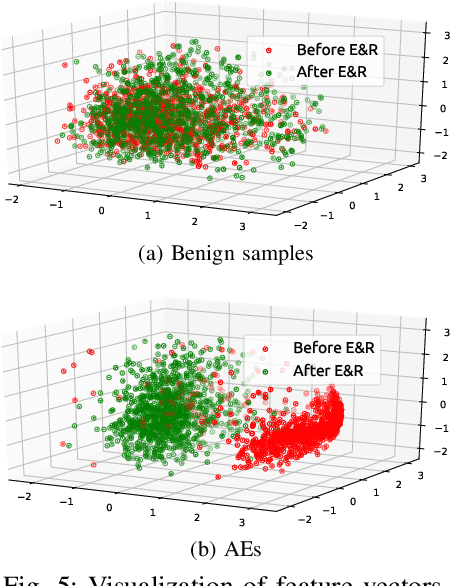
By adding carefully crafted perturbations to input images, adversarial examples (AEs) can be generated to mislead neural-network-based image classifiers. $L_2$ adversarial perturbations by Carlini and Wagner (CW) are regarded as among the most effective attacks. While many countermeasures against AEs have been proposed, detection of adaptive CW $L_2$ AEs has been very inaccurate. Our observation is that those deliberately altered pixels in an $L_2$ AE, altogether, exert their malicious influence. By randomly erasing some pixels from an $L_2$ AE and then restoring it with an inpainting technique, such an AE, before and after the steps, tends to have different classification results, while a benign sample does not show this symptom. Based on this, we propose a novel AE detection technique, Erase and Restore (E\&R), that exploits the limitation of $L_2$ attacks. On two popular image datasets, CIFAR-10 and ImageNet, our experiments show that the proposed technique is able to detect over 98% of the AEs generated by CW and other $L_2$ algorithms and has a very low false positive rate on benign images. Moreover, our approach demonstrate strong resilience to adaptive attacks. While adding noises and inpainting each have been well studied, by combining them together, we deliver a simple, accurate and resilient detection technique against adaptive $L_2$ AEs.