 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Bidirectional Unsupervised Translation Through Multilingual Finetuning and Back-Translation
Paper and Code
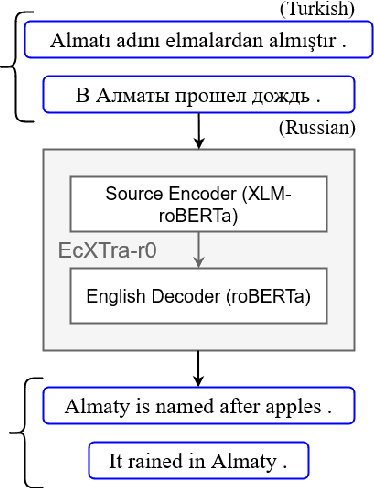

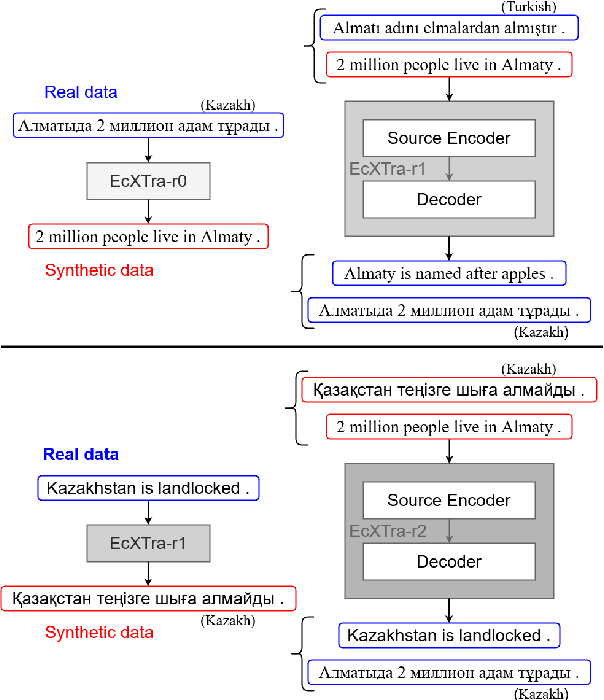
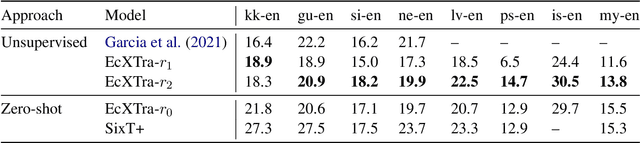
We propose a two-stage training approach for developing a single NMT model to translate unseen languages both to and from English. For the first stage, we initialize an encoder-decoder model to pretrained XLM-R and RoBERTa weights, then perform multilingual fine-tuning on parallel data in 25 languages to English. We find this model can generalize to zero-shot translations on unseen languages. For the second stage, we leverage this generalization ability to generate synthetic parallel data from monolingual datasets, then train with successive rounds of back-translation. The final model extends to the English-to-Many direction, while retaining Many-to-English performance. We term our approach EcXTra (English-centric Crosslingual (X) Transfer). Our approach sequentially leverages auxiliary parallel data and monolingual data, and is conceptually simple, only using a standard cross-entropy objective in both stages. The final EcXTra model is evaluated on unsupervised NMT on 8 low-resource languages achieving a new state-of-the-art for English-to-Kazakh (22.3 > 10.4 BLEU), and competitive performance for the other 15 translation directions.