 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Wikily" Neural Machine Translation Tailored to Cross-Lingual Tasks
Paper and Code
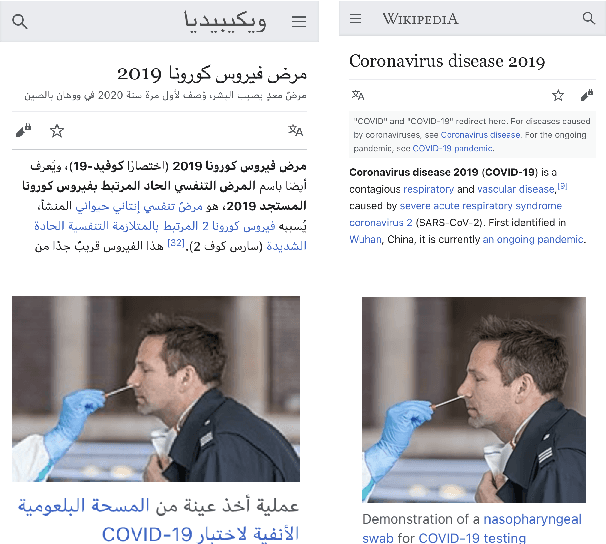

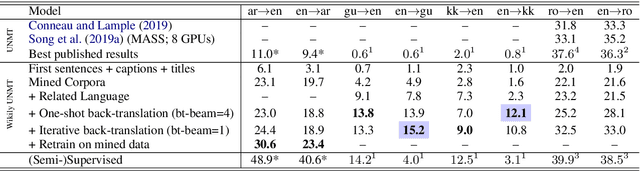
We present a simple but effective approach for leveraging Wikipedia for neural machine translation as well as cross-lingual tasks of image captioning and dependency parsing without using any direct supervision from external parallel data or supervised models in the target language. We show that first sentences and titles of linked Wikipedia pages, as well as cross-lingual image captions, are strong signals for a seed parallel data to extract bilingual dictionaries and cross-lingual word embeddings for mining parallel text from Wikipedia. Our final model achieves high BLEU scores that are close to or sometimes higher than strong supervised baselines in low-resource languages; e.g. supervised BLEU of 4.0 versus 12.1 from our model in English-to-Kazakh. Moreover, we tailor our wikily translation models to unsupervised image captioning and cross-lingual dependency parser transfer. In image captioning, we train a multi-tasking machine translation and image captioning pipeline for Arabic and English from which the Arabic training data is a wikily translation of the English captioning data. Our captioning results in Arabic are slightly better than that of its supervised model. In dependency parsing, we translate a large amount of monolingual text, and use it as an artificial training data in an annotation projection framework. We show that our model outperforms recent work on cross-lingual transfer of dependency parsers.