 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreathNet: Generalizable Audio Deepfake Detection via Breath-Cue-Guided Feature Refinement
Feb 14, 2026As deepfake audio becomes more realistic and diverse, developing generalizable countermeasure systems has become crucial. Existing detection methods primarily depend on XLS-R front-end features to improve generalization. Nonetheless, their performance remains limited, partly due to insufficient attention to fine-grained information, such as physiological cues or frequency-domain features. In this paper, we propose BreathNet, a novel audio deepfake detection framework that integrates fine-grained breath information to improve generalization. Specifically, we design BreathFiLM, a feature-wise linear modulation mechanism that selectively amplifies temporal representations based on the presence of breathing sounds. BreathFiLM is trained jointly with the XLS-R extractor, in turn encouraging the extractor to learn and encode breath-related cues into the temporal features. Then, we use the frequency front-end to extract spectral features, which are then fused with temporal features to provide complementary information introduced by vocoders or compression artifacts. Additionally, we propose a group of feature losses comprising Positive-only Supervised Contrastive Loss (PSCL), center loss, and contrast loss. These losses jointly enhance the discriminative ability, encouraging the model to separate bona fide and deepfake samples more effectively in the feature space. Extensive experiments on five benchmark datasets demonstrate state-of-the-art (SOTA) performance. Using the ASVspoof 2019 LA training set, our method attains 1.99% average EER across four related eval benchmarks, with particularly strong performance on the In-the-Wild dataset, where it achieves 4.70% EER. Moreover, under the ASVspoof5 evaluation protocol, our method achieves an EER of 4.94% on this latest benchmark.
HI-TransPA: Hearing Impairments Translation Personal Assistant
Nov 14, 2025Hearing-impaired individuals often face significant barriers in daily communication due to the inherent challenges of producing clear speech. To address this, we introduce the Omni-Model paradigm into assistive technology and present HI-TransPA, an instruction-driven audio-visual personal assistant. The model fuses indistinct speech with lip dynamics, enabling both translation and dialogue within a single multimodal framework. To address the distinctive pronunciation patterns of hearing-impaired speech and the limited adaptability of existing models, we develop a multimodal preprocessing and curation pipeline that detects facial landmarks, stabilizes the lip region, and quantitatively evaluates sample quality. These quality scores guide a curriculum learning strategy that first trains on clean, high-confidence samples and progressively incorporates harder cases to strengthen model robustness. Architecturally, we employs a novel unified 3D-Resampler to efficiently encode the lip dynamics, which is critical for accurate interpretation. Experiments on purpose-built HI-Dialogue dataset show that HI-TransPA achieves state-of-the-art performance in both literal accuracy and semantic fidelity. Our work establishes a foundation for applying Omni-Models to assistive communication technology, providing an end-to-end modeling framework and essential processing tools for future research.
Speech Emotion Recognition via Entropy-Aware Score Selection
Aug 28, 2025In this paper, we propose a multimodal framework for speech emotion recognition that leverages entropy-aware score selection to combine speech and textual predictions. The proposed method integrates a primary pipeline that consists of an acoustic model based on wav2vec2.0 and a secondary pipeline that consists of a sentiment analysis model using RoBERTa-XLM, with transcriptions generated via Whisper-large-v3. We propose a late score fusion approach based on entropy and varentropy thresholds to overcome the confidence constraints of primary pipeline predictions. A sentiment mapping strategy translates three sentiment categories into four target emotion classes, enabling coherent integration of multimodal predictions. The results on the IEMOCAP and MSP-IMPROV datasets show that the proposed method offers a practical and reliable enhancement over traditional single-modality systems.
TRNet: Two-level Refinement Network leveraging Speech Enhancement for Noise Robust Speech Emotion Recognition
Apr 19, 2024



One persistent challenge in Speech Emotion Recognition (SER) is the ubiquitous environmental noise, which frequently results in diminished SER performance in practical use. In this paper, we introduce a Two-level Refinement Network, dubbed TRNet, to address this challenge. Specifically, a pre-trained speech enhancement module is employed for front-end noise reduction and noise level estimation. Later, we utilize clean speech spectrograms and their corresponding deep representations as reference signals to refine the spectrogram distortion and representation shift of enhanced speech during model training. Experimental results validate that the proposed TRNet substantially increases the system's robustness in both matched and unmatched noisy environments, without compromising its performance in clean environments.
Modality-Collaborative Transformer with Hybrid Feature Reconstruction for Robust Emotion Recognition
Dec 26, 2023As a vital aspect of affective computing, Multimodal Emotion Recognition has been an active research area in the multimedia community. Despite recent progress, this field still confronts two major challenges in real-world applications: 1) improving the efficiency of constructing joint representations from unaligned multimodal features, and 2) relieving the performance decline caused by random modality feature missing. In this paper, we propose a unified framework, Modality-Collaborative Transformer with Hybrid Feature Reconstruction (MCT-HFR), to address these issues. The crucial component of MCT is a novel attention-based encoder which concurrently extracts and dynamically balances the intra- and inter-modality relations for all associated modalities. With additional modality-wise parameter sharing, a more compact representation can be encoded with less time and space complexity. To improve the robustness of MCT, we further introduce HFR which consists of two modules: Local Feature Imagination (LFI) and Global Feature Alignment (GFA). During model training, LFI leverages complete features as supervisory signals to recover local missing features, while GFA is designed to reduce the global semantic gap between pairwise complete and incomplete representations. Experimental evaluations on two popular benchmark datasets demonstrate that our proposed method consistently outperforms advanced baselines in both complete and incomplete data scenarios.
DSNet: Disentangled Siamese Network with Neutral Calibration for Speech Emotion Recognition
Dec 25, 2023One persistent challenge in deep learning based speech emotion recognition (SER) is the unconscious encoding of emotion-irrelevant factors (e.g., speaker or phonetic variability), which limits the generalization of SER in practical use. In this paper, we propose DSNet, a Disentangled Siamese Network with neutral calibration, to meet the demand for a more robust and explainable SER model. Specifically, we introduce an orthogonal feature disentanglement module to explicitly project the high-level representation into two distinct subspaces. Later, we propose a novel neutral calibration mechanism to encourage one subspace to capture sufficient emotion-irrelevant information. In this way, the other one can better isolate and emphasize the emotion-relevant information within speech signals. Experimental results on two popular benchmark datasets demonstrate the superiority of DSNet over various state-of-the-art methods for speaker-independent SER.
Audio-Visual Scene Classification Using A Transfer Learning Based Joint Optimization Strategy
Apr 25, 2022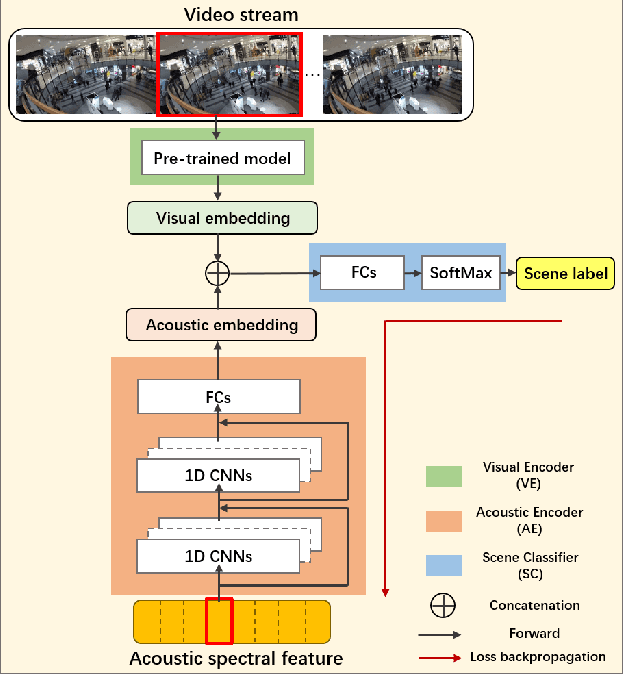


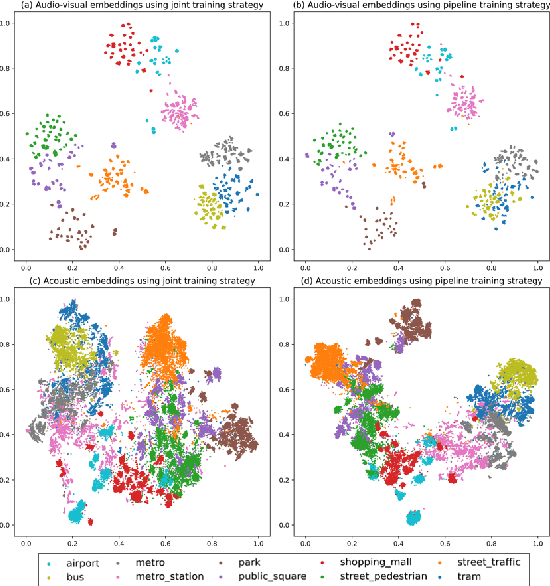
Recently, audio-visual scene classification (AVSC) has attracted increasing attention from multidisciplinary communities. Previous studies tended to adopt a pipeline training strategy, which uses well-trained visual and acoustic encoders to extract high-level representations (embeddings) first, then utilizes them to train the audio-visual classifier. In this way, the extracted embeddings are well suited for uni-modal classifiers, but not necessarily suited for multi-modal ones. In this paper, we propose a joint training framework, using the acoustic features and raw images directly as inputs for the AVSC task. Specifically, we retrieve the bottom layers of pre-trained image models as visual encoder, and jointly optimize the scene classifier and 1D-CNN based acoustic encoder during training. We evaluate the approach on the development dataset of TAU Urban Audio-Visual Scenes 2021. The experimental results show that our proposed approach achieves significant improvement over the conventional pipeline training strategy. Moreover, our best single system outperforms previous state-of-the-art methods, yielding a log loss of 0.1517 and accuracy of 94.59% on the official test fold.
CTA-RNN: Channel and Temporal-wise Attention RNN Leveraging Pre-trained ASR Embeddings for Speech Emotion Recognition
Mar 31, 2022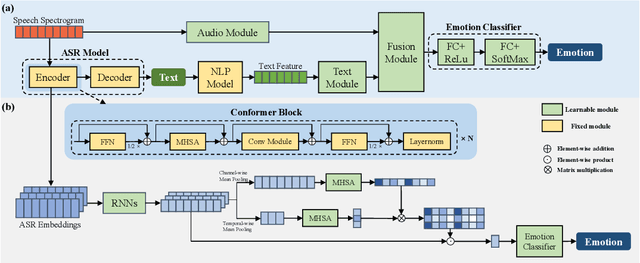

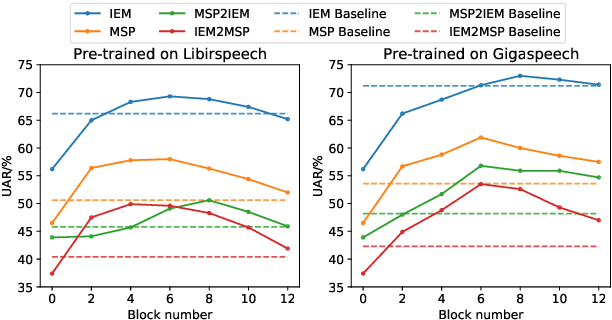
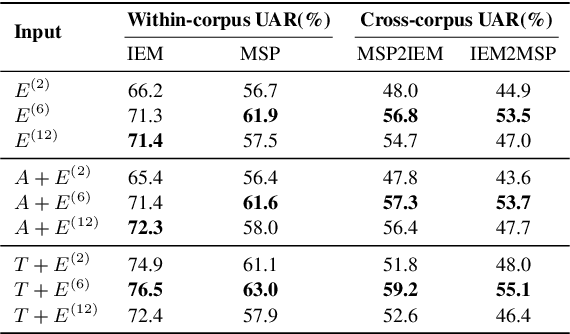
Previous research has looked into ways to improve speech emotion recognition (SER) by utilizing both acoustic and linguistic cues of speech. However, the potential association between state-of-the-art ASR models and the SER task has yet to be investigated. In this paper, we propose a novel channel and temporal-wise attention RNN (CTA-RNN) architecture based on the intermediate representations of pre-trained ASR models. Specifically, the embeddings of a large-scale pre-trained end-to-end ASR encoder contain both acoustic and linguistic information, as well as the ability to generalize to different speakers, making them well suited for downstream SER task. To further exploit the embeddings from different layers of the ASR encoder, we propose a novel CTA-RNN architecture to capture the emotional salient parts of embeddings in both the channel and temporal directions. We evaluate our approach on two popular benchmark datasets, IEMOCAP and MSP-IMPROV, using both within-corpus and cross-corpus settings. Experimental results show that our proposed method can achieve excellent performance in terms of accuracy and robustness.