 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Foundation AI Model for Generalizable Disease Detection in Head Computed Tomography
Feb 04, 2025



Head computed tomography (CT) imaging is a widely-used imaging modality with multitudes of medical indications, particularly in assessing pathology of the brain, skull, and cerebrovascular system. It is commonly the first-line imaging in neurologic emergencies given its rapidity of image acquisition, safety, cost, and ubiquity. Deep learning models may facilitate detection of a wide range of diseases. However, the scarcity of high-quality labels and annotations, particularly among less common conditions, significantly hinders the development of powerful models. To address this challenge, we introduce FM-CT: a Foundation Model for Head CT for generalizable disease detection, trained using self-supervised learning. Our approach pre-trains a deep learning model on a large, diverse dataset of 361,663 non-contrast 3D head CT scans without the need for manual annotations, enabling the model to learn robust, generalizable features. To investigate the potential of self-supervised learning in head CT, we employed both discrimination with self-distillation and masked image modeling, and we construct our model in 3D rather than at the slice level (2D) to exploit the structure of head CT scans more comprehensively and efficiently. The model's downstream classification performance is evaluated using internal and three external datasets, encompassing both in-distribution (ID) and out-of-distribution (OOD) data. Our results demonstrate that the self-supervised foundation model significantly improves performance on downstream diagnostic tasks compared to models trained from scratch and previous 3D CT foundation models on scarce annotated datasets. This work highlights the effectiveness of self-supervised learning in medical imaging and sets a new benchmark for head CT image analysis in 3D, enabling broader use of artificial intelligence for head CT-based diagnosis.
Benchmarking Large Language Model Volatility
Nov 26, 2023
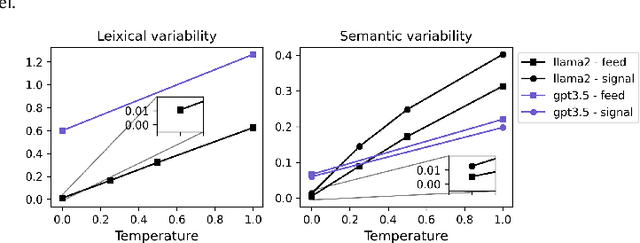

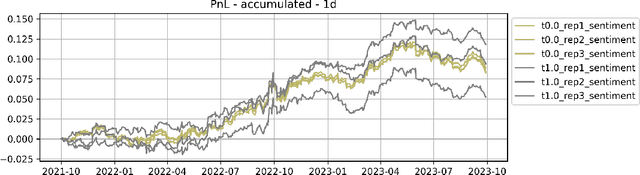
The impact of non-deterministic outputs from Large Language Models (LLMs) is not well examined for financial text understanding tasks. Through a compelling case study on investing in the US equity market via news sentiment analysis, we uncover substantial variability in sentence-level sentiment classification results, underscoring the innate volatility of LLM outputs. These uncertainties cascade downstream, leading to more significant variations in portfolio construction and return. While tweaking the temperature parameter in the language model decoder presents a potential remedy, it comes at the expense of stifled creativity. Similarly, while ensembling multiple outputs mitigates the effect of volatile outputs, it demands a notable computational investment. This work furnishes practitioners with invaluable insights for adeptly navigating uncertainty in the integration of LLMs into financial decision-making, particularly in scenarios dictated by non-deterministic information.
Quantifying Impairment and Disease Severity Using AI Models Trained on Healthy Subjects
Nov 21, 2023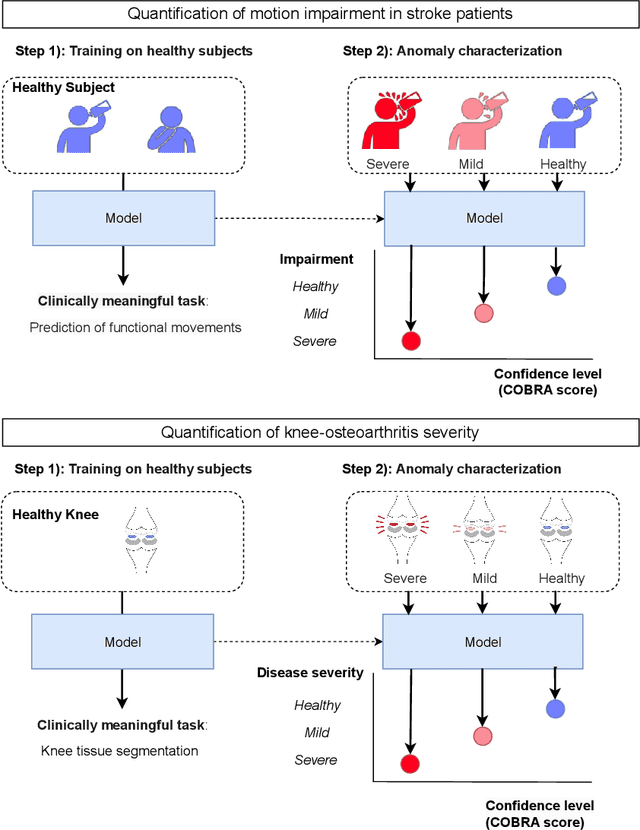
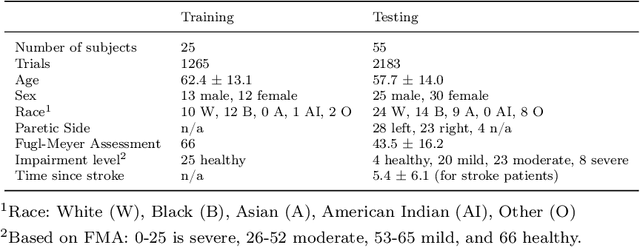
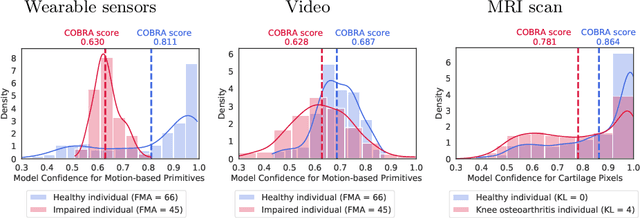
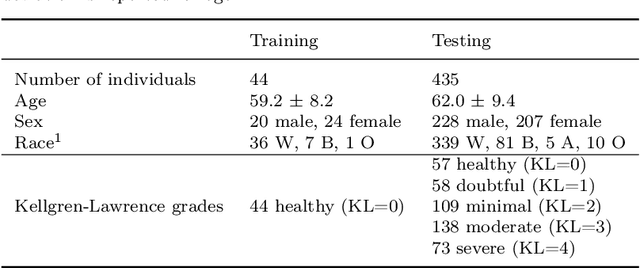
Automatic assessment of impairment and disease severity is a key challenge in data-driven medicine. We propose a novel framework to address this challenge, which leverages AI models trained exclusively on healthy individuals. The COnfidence-Based chaRacterization of Anomalies (COBRA) score exploits the decrease in confidence of these models when presented with impaired or diseased patients to quantify their deviation from the healthy population. We applied the COBRA score to address a key limitation of current clinical evaluation of upper-body impairment in stroke patients. The gold-standard Fugl-Meyer Assessment (FMA) requires in-person administration by a trained assessor for 30-45 minutes, which restricts monitoring frequency and precludes physicians from adapting rehabilitation protocols to the progress of each patient. The COBRA score, computed automatically in under one minute, is shown to be strongly correlated with the FMA on an independent test cohort for two different data modalities: wearable sensors ($\rho = 0.845$, 95% CI [0.743,0.908]) and video ($\rho = 0.746$, 95% C.I [0.594, 0.847]). To demonstrate the generalizability of the approach to other conditions, the COBRA score was also applied to quantify severity of knee osteoarthritis from magnetic-resonance imaging scans, again achieving significant correlation with an independent clinical assessment ($\rho = 0.644$, 95% C.I [0.585,0.696]).
Improved selective background Monte Carlo simulation at Belle II with graph attention networks and weighted events
Jul 12, 2023


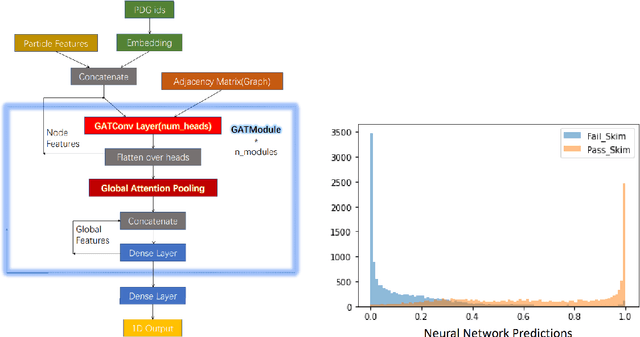
When measuring rare processes at Belle II, a huge luminosity is required, which means a large number of simulations are necessary to determine signal efficiencies and background contributions. However, this process demands high computation costs while most of the simulated data, in particular in case of background, are discarded by the event selection. Thus, filters using graph neural networks are introduced at an early stage to save the resources for the detector simulation and reconstruction of events discarded at analysis level. In our work, we improved the performance of the filters using graph attention and investigated statistical methods including sampling and reweighting to deal with the biases introduced by the filtering.
Doubly Stochastic Models: Learning with Unbiased Label Noises and Inference Stability
Apr 01, 2023Random label noises (or observational noises) widely exist in practical machine learning settings. While previous studies primarily focus on the affects of label noises to the performance of learning, our work intends to investigate the implicit regularization effects of the label noises, under mini-batch sampling settings of stochastic gradient descent (SGD), with assumptions that label noises are unbiased. Specifically, we analyze the learning dynamics of SGD over the quadratic loss with unbiased label noises, where we model the dynamics of SGD as a stochastic differentiable equation (SDE) with two diffusion terms (namely a Doubly Stochastic Model). While the first diffusion term is caused by mini-batch sampling over the (label-noiseless) loss gradients as many other works on SGD, our model investigates the second noise term of SGD dynamics, which is caused by mini-batch sampling over the label noises, as an implicit regularizer. Our theoretical analysis finds such implicit regularizer would favor some convergence points that could stabilize model outputs against perturbation of parameters (namely inference stability). Though similar phenomenon have been investigated, our work doesn't assume SGD as an Ornstein-Uhlenbeck like process and achieve a more generalizable result with convergence of approximation proved. To validate our analysis, we design two sets of empirical studies to analyze the implicit regularizer of SGD with unbiased random label noises for deep neural networks training and linear regression.
4D Facial Expression Diffusion Model
Mar 29, 2023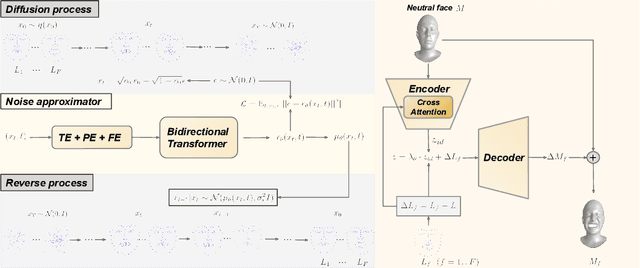
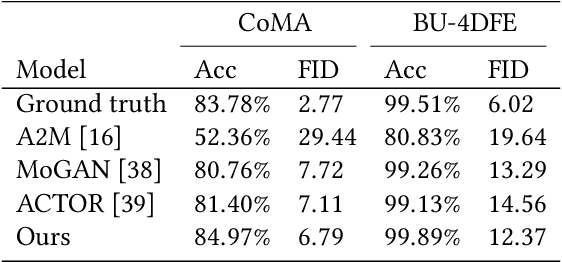

Facial expression generation is one of the most challenging and long-sought aspects of character animation, with many interesting applications. The challenging task, traditionally having relied heavily on digital craftspersons, remains yet to be explored. In this paper, we introduce a generative framework for generating 3D facial expression sequences (i.e. 4D faces) that can be conditioned on different inputs to animate an arbitrary 3D face mesh. It is composed of two tasks: (1) Learning the generative model that is trained over a set of 3D landmark sequences, and (2) Generating 3D mesh sequences of an input facial mesh driven by the generated landmark sequences. The generative model is based on a Denoising Diffusion Probabilistic Model (DDPM), which has achieved remarkable success in generative tasks of other domains. While it can be trained unconditionally, its reverse process can still be conditioned by various condition signals. This allows us to efficiently develop several downstream tasks involving various conditional generation, by using expression labels, text, partial sequences, or simply a facial geometry. To obtain the full mesh deformation, we then develop a landmark-guided encoder-decoder to apply the geometrical deformation embedded in landmarks on a given facial mesh. Experiments show that our model has learned to generate realistic, quality expressions solely from the dataset of relatively small size, improving over the state-of-the-art methods. Videos and qualitative comparisons with other methods can be found at https://github.com/ZOUKaifeng/4DFM. Code and models will be made available upon acceptance.
Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning
Nov 24, 2021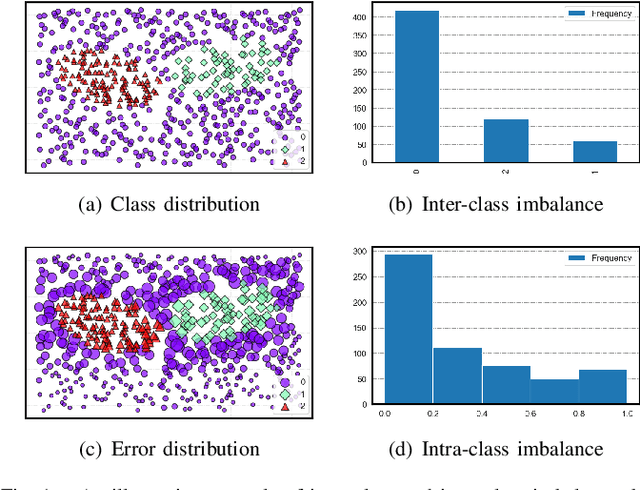
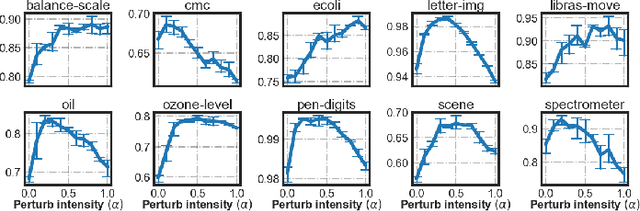
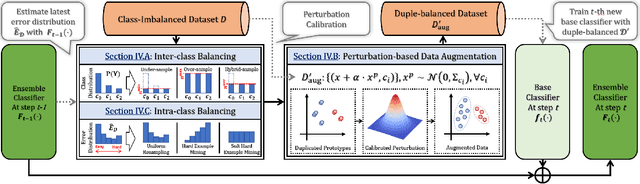
Imbalanced Learning (IL) is an important problem that widely exists in data mining applications. Typical IL methods utilize intuitive class-wise resampling or reweighting to directly balance the training set. However, some recent research efforts in specific domains show that class-imbalanced learning can be achieved without class-wise manipulation. This prompts us to think about the relationship between the two different IL strategies and the nature of the class imbalance. Fundamentally, they correspond to two essential imbalances that exist in IL: the difference in quantity between examples from different classes as well as between easy and hard examples within a single class, i.e., inter-class and intra-class imbalance. Existing works fail to explicitly take both imbalances into account and thus suffer from suboptimal performance. In light of this, we present Duple-Balanced Ensemble, namely DUBE , a versatile ensemble learning framework. Unlike prevailing methods, DUBE directly performs inter-class and intra-class balancing without relying on heavy distance-based computation, which allows it to achieve competitive performance while being computationally efficient. We also present a detailed discussion and analysis about the pros and cons of different inter/intra-class balancing strategies based on DUBE . Extensive experiments validate the effectiveness of the proposed method. Code and examples are available at https://github.com/ICDE2022Sub/duplebalance.
IMBENS: Ensemble Class-imbalanced Learning in Python
Nov 24, 2021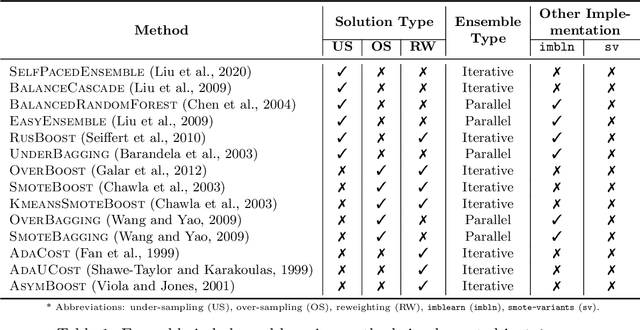
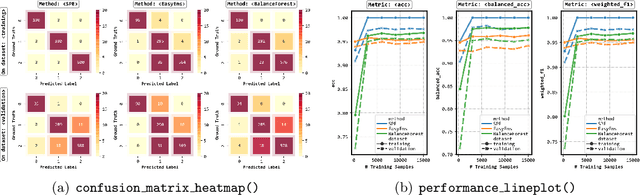
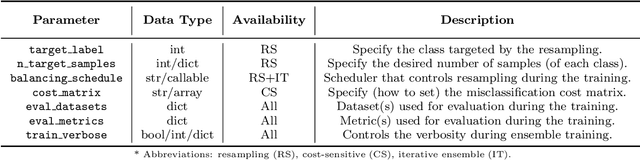
imbalanced-ensemble, abbreviated as imbens, is an open-source Python toolbox for quick implementing and deploying ensemble learning algorithms on class-imbalanced data. It provides access to multiple state-of-art ensemble imbalanced learning (EIL) methods, visualizer, and utility functions for dealing with the class imbalance problem. These ensemble methods include resampling-based, e.g., under/over-sampling, and reweighting-based ones, e.g., cost-sensitive learning. Beyond the implementation, we also extend conventional binary EIL algorithms with new functionalities like multi-class support and resampling scheduler, thereby enabling them to handle more complex tasks. The package was developed under a simple, well-documented API design follows that of scikit-learn for increased ease of use. imbens is released under the MIT open-source license and can be installed from Python Package Index (PyPI). Source code, binaries, detailed documentation, and usage examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.
Deep Probability Estimation
Nov 21, 2021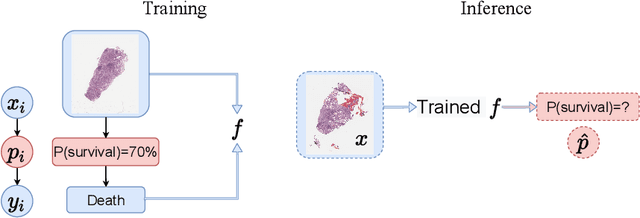
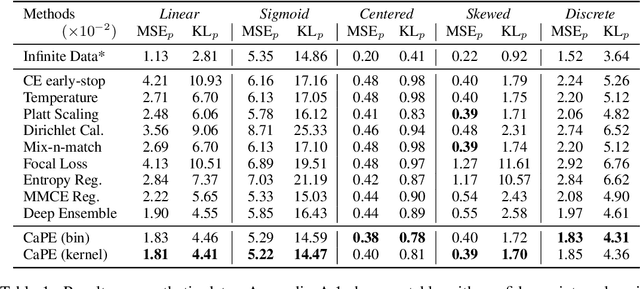

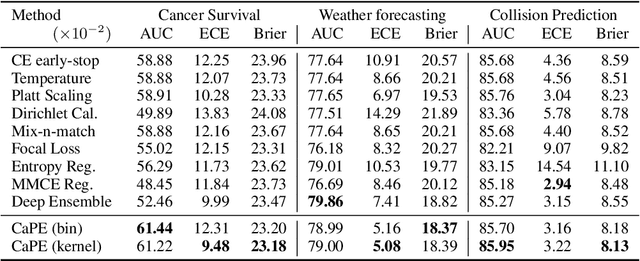
Reliable probability estimation is of crucial importance in many real-world applications where there is inherent uncertainty, such as weather forecasting, medical prognosis, or collision avoidance in autonomous vehicles. Probability-estimation models are trained on observed outcomes (e.g. whether it has rained or not, or whether a patient has died or not), because the ground-truth probabilities of the events of interest are typically unknown. The problem is therefore analogous to binary classification, with the important difference that the objective is to estimate probabilities rather than predicting the specific outcome. The goal of this work is to investigate probability estimation from high-dimensional data using deep neural networks. There exist several methods to improve the probabilities generated by these models but they mostly focus on classification problems where the probabilities are related to model uncertainty. In the case of problems with inherent uncertainty, it is challenging to evaluate performance without access to ground-truth probabilities. To address this, we build a synthetic dataset to study and compare different computable metrics. We evaluate existing methods on the synthetic data as well as on three real-world probability estimation tasks, all of which involve inherent uncertainty: precipitation forecasting from radar images, predicting cancer patient survival from histopathology images, and predicting car crashes from dashcam videos. Finally, we also propose a new method for probability estimation using neural networks, which modifies the training process to promote output probabilities that are consistent with empirical probabilities computed from the data. The method outperforms existing approaches on most metrics on the simulated as well as real-world data.