 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Foundation AI Model for Generalizable Disease Detection in Head Computed Tomography
Feb 04, 2025



Head computed tomography (CT) imaging is a widely-used imaging modality with multitudes of medical indications, particularly in assessing pathology of the brain, skull, and cerebrovascular system. It is commonly the first-line imaging in neurologic emergencies given its rapidity of image acquisition, safety, cost, and ubiquity. Deep learning models may facilitate detection of a wide range of diseases. However, the scarcity of high-quality labels and annotations, particularly among less common conditions, significantly hinders the development of powerful models. To address this challenge, we introduce FM-CT: a Foundation Model for Head CT for generalizable disease detection, trained using self-supervised learning. Our approach pre-trains a deep learning model on a large, diverse dataset of 361,663 non-contrast 3D head CT scans without the need for manual annotations, enabling the model to learn robust, generalizable features. To investigate the potential of self-supervised learning in head CT, we employed both discrimination with self-distillation and masked image modeling, and we construct our model in 3D rather than at the slice level (2D) to exploit the structure of head CT scans more comprehensively and efficiently. The model's downstream classification performance is evaluated using internal and three external datasets, encompassing both in-distribution (ID) and out-of-distribution (OOD) data. Our results demonstrate that the self-supervised foundation model significantly improves performance on downstream diagnostic tasks compared to models trained from scratch and previous 3D CT foundation models on scarce annotated datasets. This work highlights the effectiveness of self-supervised learning in medical imaging and sets a new benchmark for head CT image analysis in 3D, enabling broader use of artificial intelligence for head CT-based diagnosis.
Free Form Medical Visual Question Answering in Radiology
Jan 23, 2024Visual Question Answering (VQA) in the medical domain presents a unique, interdisciplinary challenge, combining fields such as Computer Vision, Natural Language Processing, and Knowledge Representation. Despite its importance, research in medical VQA has been scant, only gaining momentum since 2018. Addressing this gap, our research delves into the effective representation of radiology images and the joint learning of multimodal representations, surpassing existing methods. We innovatively augment the SLAKE dataset, enabling our model to respond to a more diverse array of questions, not limited to the immediate content of radiology or pathology images. Our model achieves a top-1 accuracy of 79.55\% with a less complex architecture, demonstrating comparable performance to current state-of-the-art models. This research not only advances medical VQA but also opens avenues for practical applications in diagnostic settings.
ReGNL: Rapid Prediction of GDP during Disruptive Events using Nightlights
Jan 19, 2022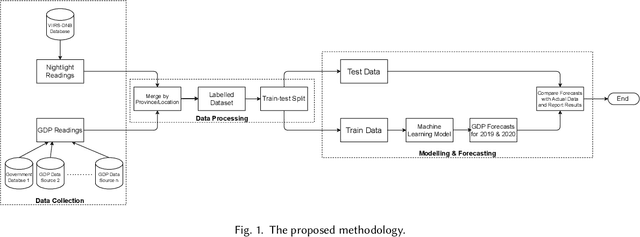



Policy makers often make decisions based on parameters such as GDP, unemployment rate, industrial output, etc. The primary methods to obtain or even estimate such information are resource intensive and time consuming. In order to make timely and well-informed decisions, it is imperative to be able to come up with proxies for these parameters which can be sampled quickly and efficiently, especially during disruptive events, like the COVID-19 pandemic. Recently, there has been a lot of focus on using remote sensing data for this purpose. The data has become cheaper to collect compared to surveys, and can be available in real time. In this work, we present Regional GDP NightLight (ReGNL), a neural network based model which is trained on a custom dataset of historical nightlights and GDP data along with the geographical coordinates of a place, and estimates the GDP of the place, given the other parameters. Taking the case of 50 US states, we find that ReGNL is disruption-agnostic and is able to predict the GDP for both normal years (2019) and for years with a disruptive event (2020). ReGNL outperforms timeseries ARIMA methods for prediction, even during the pandemic. Following from our findings, we make a case for building infrastructures to collect and make available granular data, especially in resource-poor geographies, so that these can be leveraged for policy making during disruptive events.