 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Facial Expression Diffusion Model
Mar 29, 2023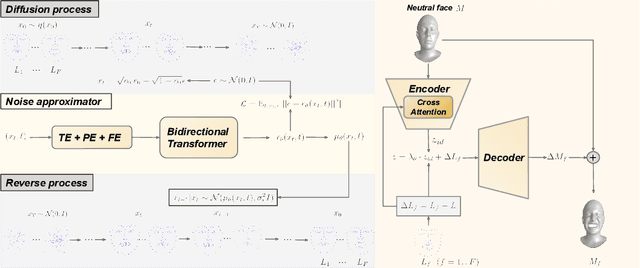
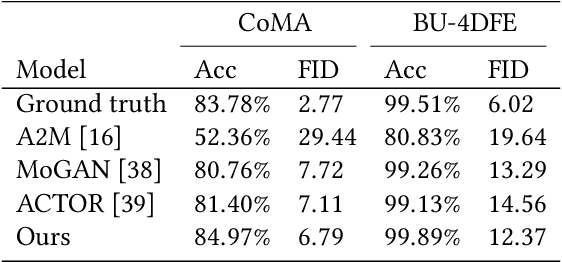

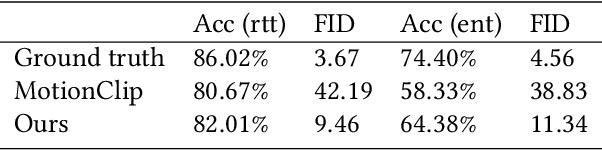
Facial expression generation is one of the most challenging and long-sought aspects of character animation, with many interesting applications. The challenging task, traditionally having relied heavily on digital craftspersons, remains yet to be explored. In this paper, we introduce a generative framework for generating 3D facial expression sequences (i.e. 4D faces) that can be conditioned on different inputs to animate an arbitrary 3D face mesh. It is composed of two tasks: (1) Learning the generative model that is trained over a set of 3D landmark sequences, and (2) Generating 3D mesh sequences of an input facial mesh driven by the generated landmark sequences. The generative model is based on a Denoising Diffusion Probabilistic Model (DDPM), which has achieved remarkable success in generative tasks of other domains. While it can be trained unconditionally, its reverse process can still be conditioned by various condition signals. This allows us to efficiently develop several downstream tasks involving various conditional generation, by using expression labels, text, partial sequences, or simply a facial geometry. To obtain the full mesh deformation, we then develop a landmark-guided encoder-decoder to apply the geometrical deformation embedded in landmarks on a given facial mesh. Experiments show that our model has learned to generate realistic, quality expressions solely from the dataset of relatively small size, improving over the state-of-the-art methods. Videos and qualitative comparisons with other methods can be found at https://github.com/ZOUKaifeng/4DFM. Code and models will be made available upon acceptance.
Disentangled representations: towards interpretation of sex determination from hip bone
Dec 17, 2021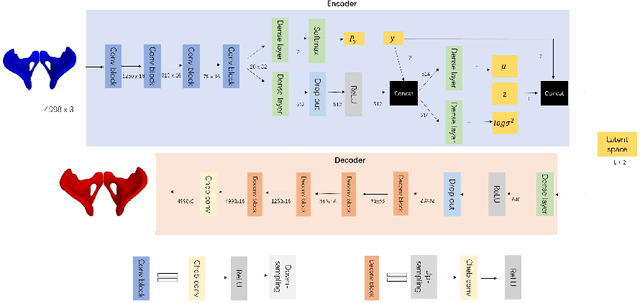


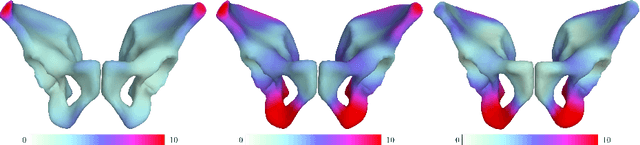
By highlighting the regions of the input image that contribute the most to the decision, saliency maps have become a popular method to make neural networks interpretable. In medical imaging, they are particularly well-suited to explain neural networks in the context of abnormality localization. However, from our experiments, they are less suited to classification problems where the features that allow to distinguish between the different classes are spatially correlated, scattered and definitely non-trivial. In this paper we thus propose a new paradigm for better interpretability. To this end we provide the user with relevant and easily interpretable information so that he can form his own opinion. We use Disentangled Variational Auto-Encoders which latent representation is divided into two components: the non-interpretable part and the disentangled part. The latter accounts for the categorical variables explicitly representing the different classes of interest. In addition to providing the class of a given input sample, such a model offers the possibility to transform the sample from a given class to a sample of another class, by modifying the value of the categorical variables in the latent representation. This paves the way to easier interpretation of class differences. We illustrate the relevance of this approach in the context of automatic sex determination from hip bones in forensic medicine. The features encoded by the model, that distinguish the different classes were found to be consistent with expert knowledge.