 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled representations: towards interpretation of sex determination from hip bone
Dec 17, 2021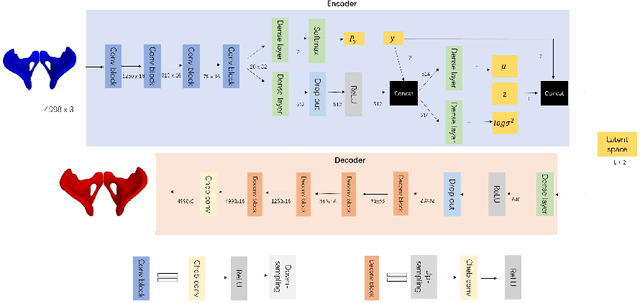


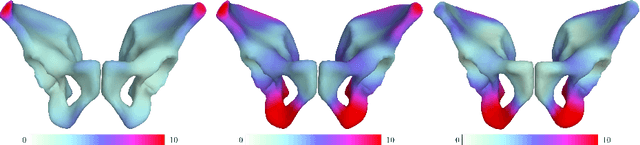
By highlighting the regions of the input image that contribute the most to the decision, saliency maps have become a popular method to make neural networks interpretable. In medical imaging, they are particularly well-suited to explain neural networks in the context of abnormality localization. However, from our experiments, they are less suited to classification problems where the features that allow to distinguish between the different classes are spatially correlated, scattered and definitely non-trivial. In this paper we thus propose a new paradigm for better interpretability. To this end we provide the user with relevant and easily interpretable information so that he can form his own opinion. We use Disentangled Variational Auto-Encoders which latent representation is divided into two components: the non-interpretable part and the disentangled part. The latter accounts for the categorical variables explicitly representing the different classes of interest. In addition to providing the class of a given input sample, such a model offers the possibility to transform the sample from a given class to a sample of another class, by modifying the value of the categorical variables in the latent representation. This paves the way to easier interpretation of class differences. We illustrate the relevance of this approach in the context of automatic sex determination from hip bones in forensic medicine. The features encoded by the model, that distinguish the different classes were found to be consistent with expert knowledge.
Unsupervised learning-based long-term superpixel tracking
Feb 25, 2019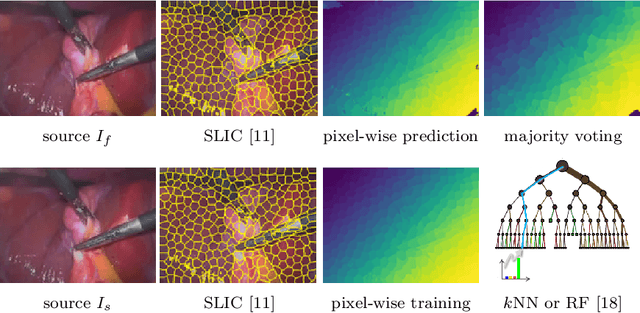
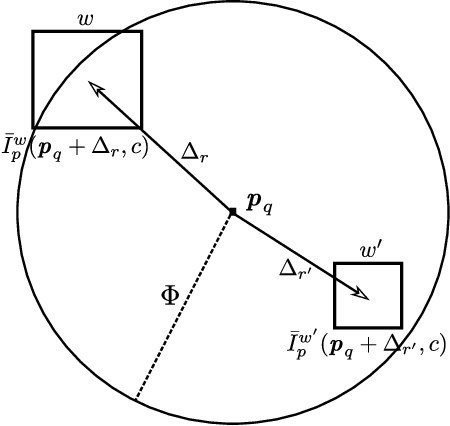
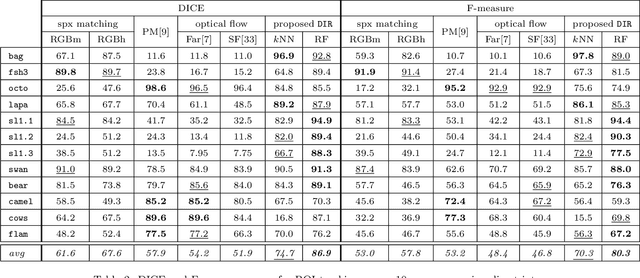
Finding correspondences between structural entities decomposing images is of high interest for computer vision applications. In particular, we analyze how to accurately track superpixels - visual primitives generated by aggregating adjacent pixels sharing similar characteristics - over extended time periods relying on unsupervised learning and temporal integration. A two-step video processing pipeline dedicated to long-term superpixel tracking is proposed. First, unsupervised learning-based superpixel matching provides correspondences between consecutive and distant frames using new context-rich features extended from greyscale to multi-channel and forward-backward consistency contraints. Resulting elementary matches are then combined along multi-step paths running through the whole sequence with various inter-frame distances. This produces a large set of candidate long-term superpixel pairings upon which majority voting is performed. Video object tracking experiments demonstrate the accuracy of our elementary estimator against state-of-the-art methods and proves the ability of multi-step integration to provide accurate long-term superpixel matches compared to usual direct and sequential integration.