 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$L^3$:Scene-agnostic Visual Localization in the Wild
Mar 09, 2026Standard visual localization methods typically require offline pre-processing of scenes to obtain 3D structural information for better performance. This inevitably introduces additional computational and time costs, as well as the overhead of storing scene representations. Can we visually localize in a wild scene without any off-line preprocessing step? In this paper, we leverage the online inference capabilities of feed-forward 3D reconstruction networks to propose a novel map-free visual localization framework $L^3$. Specifically, by performing direct online 3D reconstruction on RGB images, followed by two-stage metric scale recovery and pose refinement based on 2D-3D correspondences, $L^3$ achieves high accuracy without the need to pre-build or store any offline scene representations. Extensive experiments demonstrate $L^3$ not only that the performance is comparable to state-of-the-art solutions on various benchmarks, but also that it exhibits significantly superior robustness in sparse scenes (fewer reference images per scene).
DisorientLiDAR: Physical Attacks on LiDAR-based Localization
Sep 16, 2025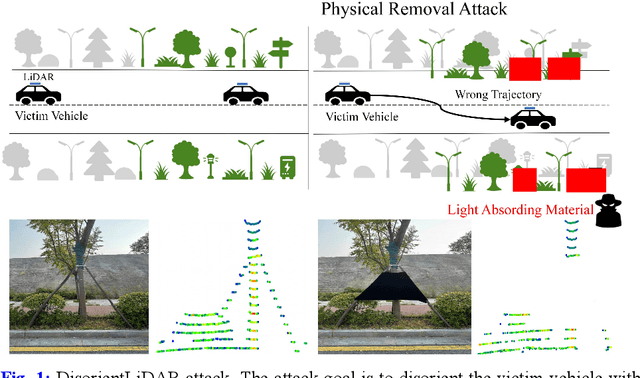
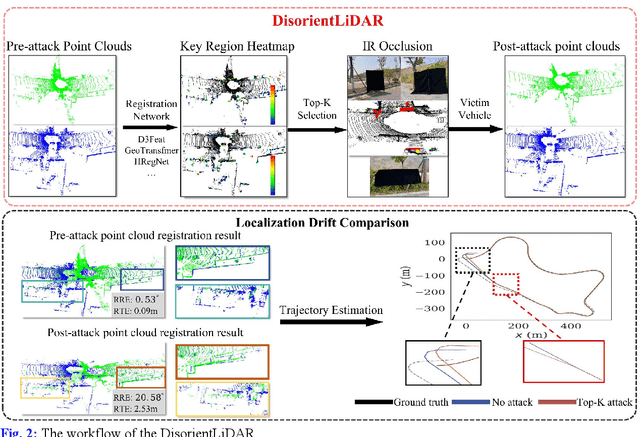
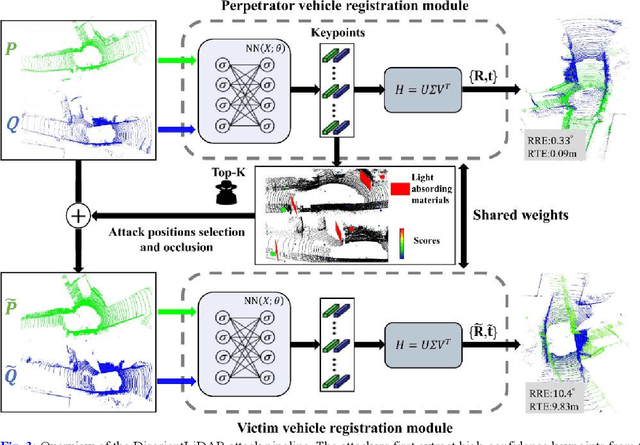
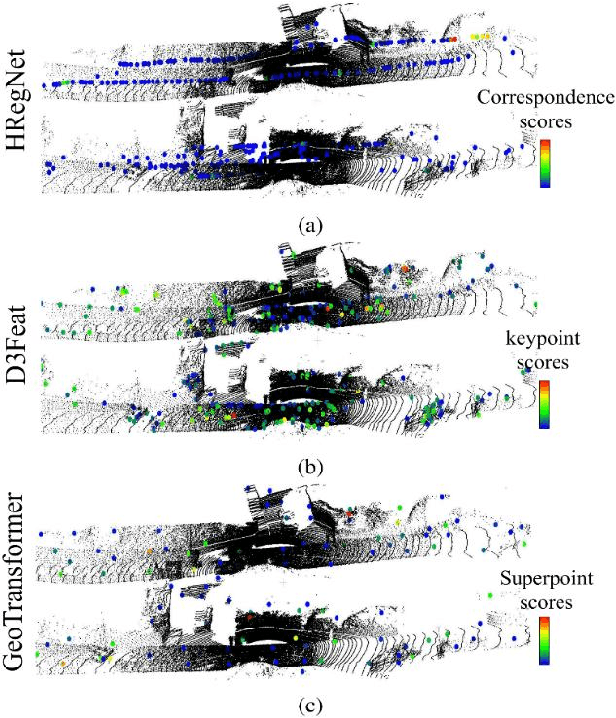
Deep learning models have been shown to be susceptible to adversarial attacks with visually imperceptible perturbations. Even this poses a serious security challenge for the localization of self-driving cars, there has been very little exploration of attack on it, as most of adversarial attacks have been applied to 3D perception. In this work, we propose a novel adversarial attack framework called DisorientLiDAR targeting LiDAR-based localization. By reverse-engineering localization models (e.g., feature extraction networks), adversaries can identify critical keypoints and strategically remove them, thereby disrupting LiDAR-based localization. Our proposal is first evaluated on three state-of-the-art point-cloud registration models (HRegNet, D3Feat, and GeoTransformer) using the KITTI dataset. Experimental results demonstrate that removing regions containing Top-K keypoints significantly degrades their registration accuracy. We further validate the attack's impact on the Autoware autonomous driving platform, where hiding merely a few critical regions induces noticeable localization drift. Finally, we extended our attacks to the physical world by hiding critical regions with near-infrared absorptive materials, thereby successfully replicate the attack effects observed in KITTI data. This step has been closer toward the realistic physical-world attack that demonstrate the veracity and generality of our proposal.
PIS3R: Very Large Parallax Image Stitching via Deep 3D Reconstruction
Aug 06, 2025Image stitching aim to align two images taken from different viewpoints into one seamless, wider image. However, when the 3D scene contains depth variations and the camera baseline is significant, noticeable parallax occurs-meaning the relative positions of scene elements differ substantially between views. Most existing stitching methods struggle to handle such images with large parallax effectively. To address this challenge, in this paper, we propose an image stitching solution called PIS3R that is robust to very large parallax based on the novel concept of deep 3D reconstruction. First, we apply visual geometry grounded transformer to two input images with very large parallax to obtain both intrinsic and extrinsic parameters, as well as the dense 3D scene reconstruction. Subsequently, we reproject reconstructed dense point cloud onto a designated reference view using the recovered camera parameters, achieving pixel-wise alignment and generating an initial stitched image. Finally, to further address potential artifacts such as holes or noise in the initial stitching, we propose a point-conditioned image diffusion module to obtain the refined result.Compared with existing methods, our solution is very large parallax tolerant and also provides results that fully preserve the geometric integrity of all pixels in the 3D photogrammetric context, enabling direct applicability to downstream 3D vision tasks such as SfM. Experimental results demonstrate that the proposed algorithm provides accurate stitching results for images with very large parallax, and outperforms the existing methods qualitatively and quantitatively.
Faster and Better 3D Splatting via Group Training
Dec 10, 2024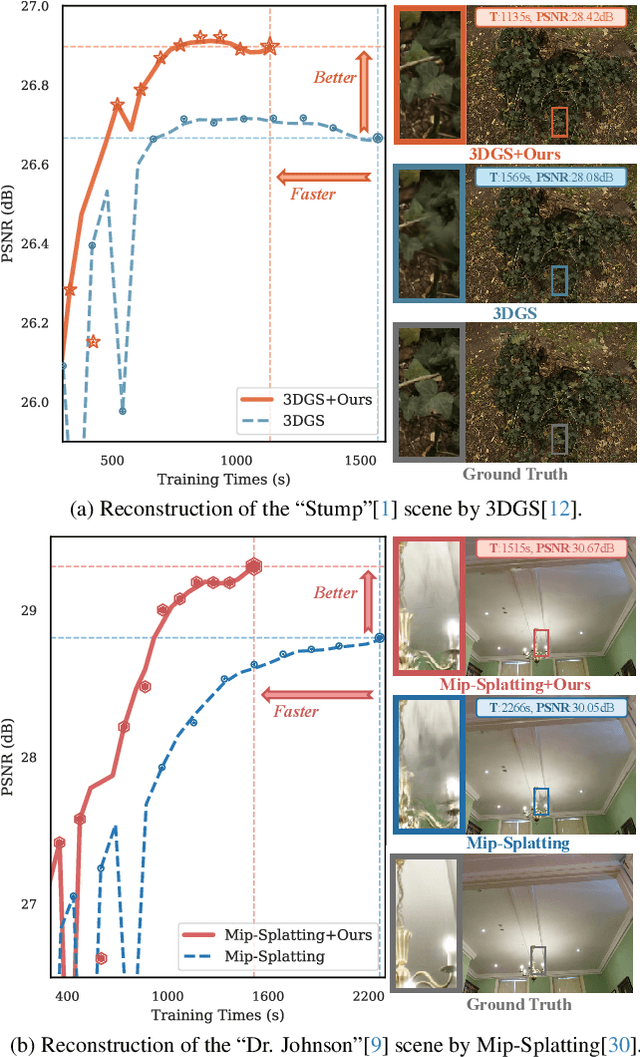

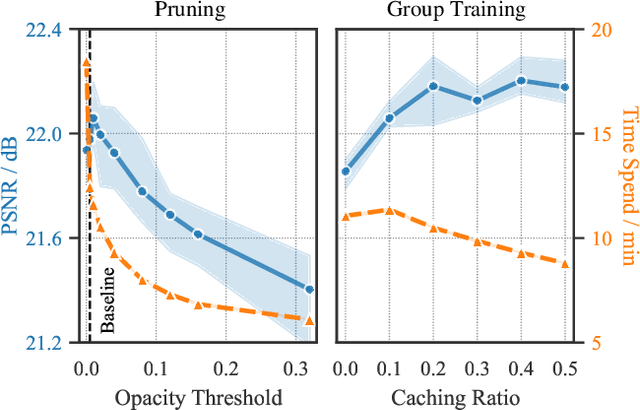

3D Gaussian Splatting (3DGS) has emerged as a powerful technique for novel view synthesis, demonstrating remarkable capability in high-fidelity scene reconstruction through its Gaussian primitive representations. However, the computational overhead induced by the massive number of primitives poses a significant bottleneck to training efficiency. To overcome this challenge, we propose Group Training, a simple yet effective strategy that organizes Gaussian primitives into manageable groups, optimizing training efficiency and improving rendering quality. This approach shows universal compatibility with existing 3DGS frameworks, including vanilla 3DGS and Mip-Splatting, consistently achieving accelerated training while maintaining superior synthesis quality. Extensive experiments reveal that our straightforward Group Training strategy achieves up to 30% faster convergence and improved rendering quality across diverse scenarios.
RSL-BA: Rolling Shutter Line Bundle Adjustment
Aug 10, 2024
The line is a prevalent element in man-made environments, inherently encoding spatial structural information, thus making it a more robust choice for feature representation in practical applications. Despite its apparent advantages, previous rolling shutter bundle adjustment (RSBA) methods have only supported sparse feature points, which lack robustness, particularly in degenerate environments. In this paper, we introduce the first rolling shutter line-based bundle adjustment solution, RSL-BA. Specifically, we initially establish the rolling shutter camera line projection theory utilizing Pl\"ucker line parameterization. Subsequently, we derive a series of reprojection error formulations which are stable and efficient. Finally, we theoretically and experimentally demonstrate that our method can prevent three common degeneracies, one of which is first discovered in this paper. Extensive synthetic and real data experiments demonstrate that our method achieves efficiency and accuracy comparable to existing point-based rolling shutter bundle adjustment solutions.
IOVS4NeRF:Incremental Optimal View Selection for Large-Scale NeRFs
Jul 26, 2024



Urban-level three-dimensional reconstruction for modern applications demands high rendering fidelity while minimizing computational costs. The advent of Neural Radiance Fields (NeRF) has enhanced 3D reconstruction, yet it exhibits artifacts under multiple viewpoints. In this paper, we propose a new NeRF framework method to address these issues. Our method uses image content and pose data to iteratively plan the next best view. A crucial aspect of this method involves uncertainty estimation, guiding the selection of views with maximum information gain from a candidate set. This iterative process enhances rendering quality over time. Simultaneously, we introduce the Vonoroi diagram and threshold sampling together with flight classifier to boost the efficiency, while keep the original NeRF network intact. It can serve as a plug-in tool to assist in better rendering, outperforming baselines and similar prior works.
BirdNeRF: Fast Neural Reconstruction of Large-Scale Scenes From Aerial Imagery
Feb 11, 2024In this study, we introduce BirdNeRF, an adaptation of Neural Radiance Fields (NeRF) designed specifically for reconstructing large-scale scenes using aerial imagery. Unlike previous research focused on small-scale and object-centric NeRF reconstruction, our approach addresses multiple challenges, including (1) Addressing the issue of slow training and rendering associated with large models. (2) Meeting the computational demands necessitated by modeling a substantial number of images, requiring extensive resources such as high-performance GPUs. (3) Overcoming significant artifacts and low visual fidelity commonly observed in large-scale reconstruction tasks due to limited model capacity. Specifically, we present a novel bird-view pose-based spatial decomposition algorithm that decomposes a large aerial image set into multiple small sets with appropriately sized overlaps, allowing us to train individual NeRFs of sub-scene. This decomposition approach not only decouples rendering time from the scene size but also enables rendering to scale seamlessly to arbitrarily large environments. Moreover, it allows for per-block updates of the environment, enhancing the flexibility and adaptability of the reconstruction process. Additionally, we propose a projection-guided novel view re-rendering strategy, which aids in effectively utilizing the independently trained sub-scenes to generate superior rendering results. We evaluate our approach on existing datasets as well as against our own drone footage, improving reconstruction speed by 10x over classical photogrammetry software and 50x over state-of-the-art large-scale NeRF solution, on a single GPU with similar rendering quality.
DFR: Depth from Rotation by Uncalibrated Image Rectification with Latitudinal Motion Assumption
Jul 11, 2023Despite the increasing prevalence of rotating-style capture (e.g., surveillance cameras), conventional stereo rectification techniques frequently fail due to the rotation-dominant motion and small baseline between views. In this paper, we tackle the challenge of performing stereo rectification for uncalibrated rotating cameras. To that end, we propose Depth-from-Rotation (DfR), a novel image rectification solution that analytically rectifies two images with two-point correspondences and serves for further depth estimation. Specifically, we model the motion of a rotating camera as the camera rotates on a sphere with fixed latitude. The camera's optical axis lies perpendicular to the sphere's surface. We call this latitudinal motion assumption. Then we derive a 2-point analytical solver from directly computing the rectified transformations on the two images. We also present a self-adaptive strategy to reduce the geometric distortion after rectification. Extensive synthetic and real data experiments demonstrate that the proposed method outperforms existing works in effectiveness and efficiency by a significant margin.
Application of attention-based Siamese composite neural network in medical image recognition
Apr 20, 2023Medical image recognition often faces the problem of insufficient data in practical applications. Image recognition and processing under few-shot conditions will produce overfitting, low recognition accuracy, low reliability and insufficient robustness. It is often the case that the difference of characteristics is subtle, and the recognition is affected by perspectives, background, occlusion and other factors, which increases the difficulty of recognition. Furthermore, in fine-grained images, the few-shot problem leads to insufficient useful feature information in the images. Considering the characteristics of few-shot and fine-grained image recognition, this study has established a recognition model based on attention and Siamese neural network. Aiming at the problem of few-shot samples, a Siamese neural network suitable for classification model is proposed. The Attention-Based neural network is used as the main network to improve the classification effect. Covid- 19 lung samples have been selected for testing the model. The results show that the less the number of image samples are, the more obvious the advantage shows than the ordinary neural network.
Towards Nonlinear-Motion-Aware and Occlusion-Robust Rolling Shutter Correction
Apr 04, 2023



This paper addresses the problem of rolling shutter correction in complex nonlinear and dynamic scenes with extreme occlusion. Existing methods suffer from two main drawbacks. Firstly, they face challenges in estimating the accurate correction field due to the uniform velocity assumption, leading to significant image correction errors under complex motion. Secondly, the drastic occlusion in dynamic scenes prevents current solutions from achieving better image quality because of the inherent difficulties in aligning and aggregating multiple frames. To tackle these challenges, we model the curvilinear trajectory of pixels analytically and propose a geometry-based Quadratic Rolling Shutter (QRS) motion solver, which precisely estimates the high-order correction field of individual pixel. Besides, to reconstruct high-quality occlusion frames in dynamic scenes, we present a 3D video architecture that effectively Aligns and Aggregates multi-frame context, namely, RSA^2-Net. We evaluate our method across a broad range of cameras and video sequences, demonstrating its significant superiority. Specifically, our method surpasses the state-of-the-arts by +4.98, +0.77, and +4.33 of PSNR on Carla-RS, Fastec-RS, and BS-RSC datasets, respectively.