 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions
May 01, 2025Memory is a fundamental component of AI systems, underpinning large language models (LLMs) based agents. While prior surveys have focused on memory applications with LLMs, they often overlook the atomic operations that underlie memory dynamics. In this survey, we first categorize memory representations into parametric, contextual structured, and contextual unstructured and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression. We systematically map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory. By reframing memory systems through the lens of atomic operations and representation types, this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI, clarifying the functional interplay in LLMs based agents while outlining promising directions for future research\footnote{The paper list, datasets, methods and tools are available at \href{https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI}{https://github.com/Elvin-Yiming-Du/Survey\_Memory\_in\_AI}.}.
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
May 10, 2024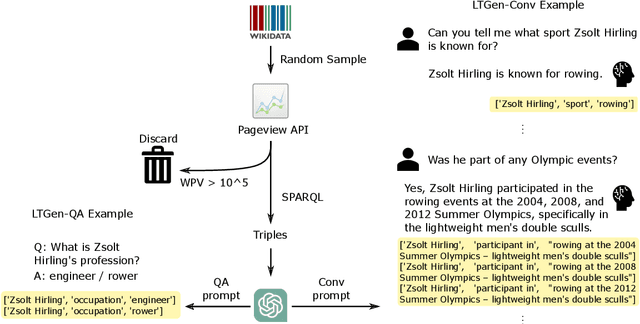
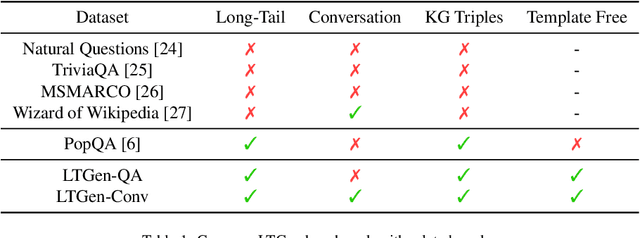
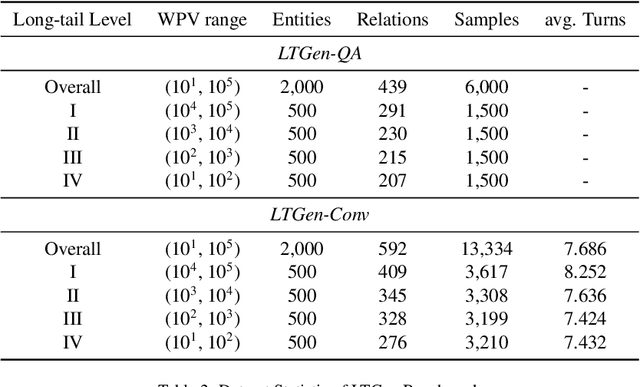
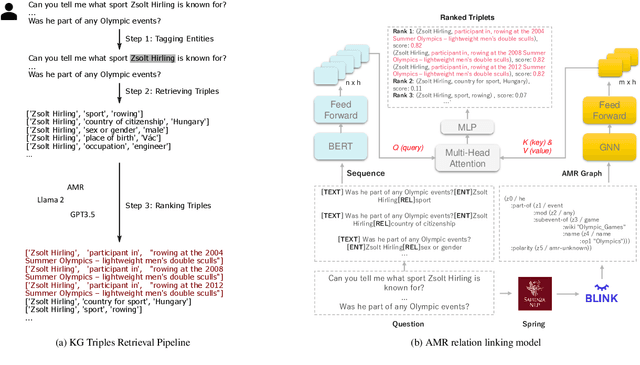
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
Investigating the Effect of Relative Positional Embeddings on AMR-to-Text Generation with Structural Adapters
Feb 12, 2023



Text generation from Abstract Meaning Representation (AMR) has substantially benefited from the popularized Pretrained Language Models (PLMs). Myriad approaches have linearized the input graph as a sequence of tokens to fit the PLM tokenization requirements. Nevertheless, this transformation jeopardizes the structural integrity of the graph and is therefore detrimental to its resulting representation. To overcome this issue, Ribeiro et al. have recently proposed StructAdapt, a structure-aware adapter which injects the input graph connectivity within PLMs using Graph Neural Networks (GNNs). In this paper, we investigate the influence of Relative Position Embeddings (RPE) on AMR-to-Text, and, in parallel, we examine the robustness of StructAdapt. Through ablation studies, graph attack and link prediction, we reveal that RPE might be partially encoding input graphs. We suggest further research regarding the role of RPE will provide valuable insights for Graph-to-Text generation.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Hyperbolic Temporal Knowledge Graph Embeddings with Relational and Time Curvatures
Jun 08, 2021



Knowledge Graph (KG) completion has been excessively studied with a massive number of models proposed for the Link Prediction (LP) task. The main limitation of such models is their insensitivity to time. Indeed, the temporal aspect of stored facts is often ignored. To this end, more and more works consider time as a parameter to complete KGs. In this paper, we first demonstrate that, by simply increasing the number of negative samples, the recent AttH model can achieve competitive or even better performance than the state-of-the-art on Temporal KGs (TKGs), albeit its nontemporality. We further propose Hercules, a time-aware extension of AttH model, which defines the curvature of a Riemannian manifold as the product of both relation and time. Our experiments show that both Hercules and AttH achieve competitive or new state-of-the-art performances on ICEWS04 and ICEWS05-15 datasets. Therefore, one should raise awareness when learning TKGs representations to identify whether time truly boosts performances.
Denoising Pre-Training and Data Augmentation Strategies for Enhanced RDF Verbalization with Transformers
Dec 01, 2020
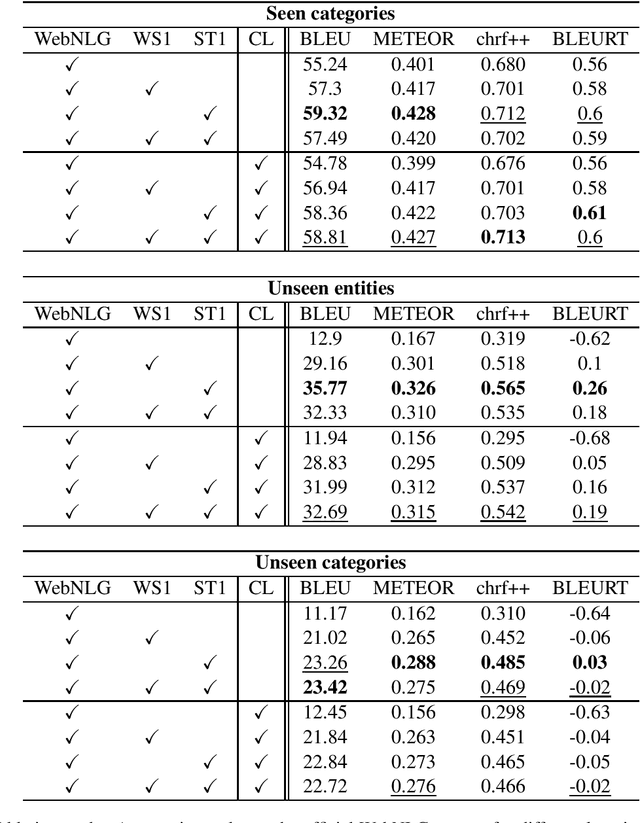
The task of verbalization of RDF triples has known a growth in popularity due to the rising ubiquity of Knowledge Bases (KBs). The formalism of RDF triples is a simple and efficient way to store facts at a large scale. However, its abstract representation makes it difficult for humans to interpret. For this purpose, the WebNLG challenge aims at promoting automated RDF-to-text generation. We propose to leverage pre-trainings from augmented data with the Transformer model using a data augmentation strategy. Our experiment results show a minimum relative increases of 3.73%, 126.05% and 88.16% in BLEU score for seen categories, unseen entities and unseen categories respectively over the standard training.