 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effect of Relative Positional Embeddings on AMR-to-Text Generation with Structural Adapters
Feb 12, 2023



Text generation from Abstract Meaning Representation (AMR) has substantially benefited from the popularized Pretrained Language Models (PLMs). Myriad approaches have linearized the input graph as a sequence of tokens to fit the PLM tokenization requirements. Nevertheless, this transformation jeopardizes the structural integrity of the graph and is therefore detrimental to its resulting representation. To overcome this issue, Ribeiro et al. have recently proposed StructAdapt, a structure-aware adapter which injects the input graph connectivity within PLMs using Graph Neural Networks (GNNs). In this paper, we investigate the influence of Relative Position Embeddings (RPE) on AMR-to-Text, and, in parallel, we examine the robustness of StructAdapt. Through ablation studies, graph attack and link prediction, we reveal that RPE might be partially encoding input graphs. We suggest further research regarding the role of RPE will provide valuable insights for Graph-to-Text generation.
Hyperbolic Temporal Knowledge Graph Embeddings with Relational and Time Curvatures
Jun 08, 2021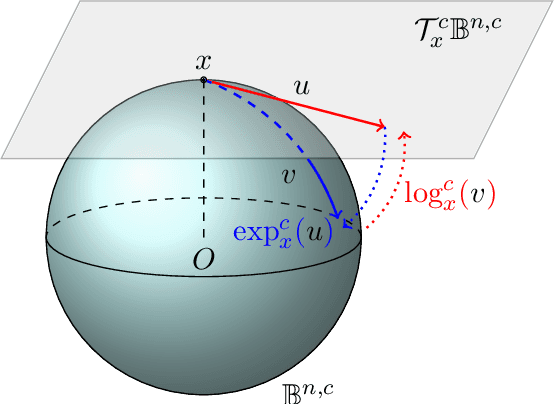



Knowledge Graph (KG) completion has been excessively studied with a massive number of models proposed for the Link Prediction (LP) task. The main limitation of such models is their insensitivity to time. Indeed, the temporal aspect of stored facts is often ignored. To this end, more and more works consider time as a parameter to complete KGs. In this paper, we first demonstrate that, by simply increasing the number of negative samples, the recent AttH model can achieve competitive or even better performance than the state-of-the-art on Temporal KGs (TKGs), albeit its nontemporality. We further propose Hercules, a time-aware extension of AttH model, which defines the curvature of a Riemannian manifold as the product of both relation and time. Our experiments show that both Hercules and AttH achieve competitive or new state-of-the-art performances on ICEWS04 and ICEWS05-15 datasets. Therefore, one should raise awareness when learning TKGs representations to identify whether time truly boosts performances.
Denoising Pre-Training and Data Augmentation Strategies for Enhanced RDF Verbalization with Transformers
Dec 01, 2020
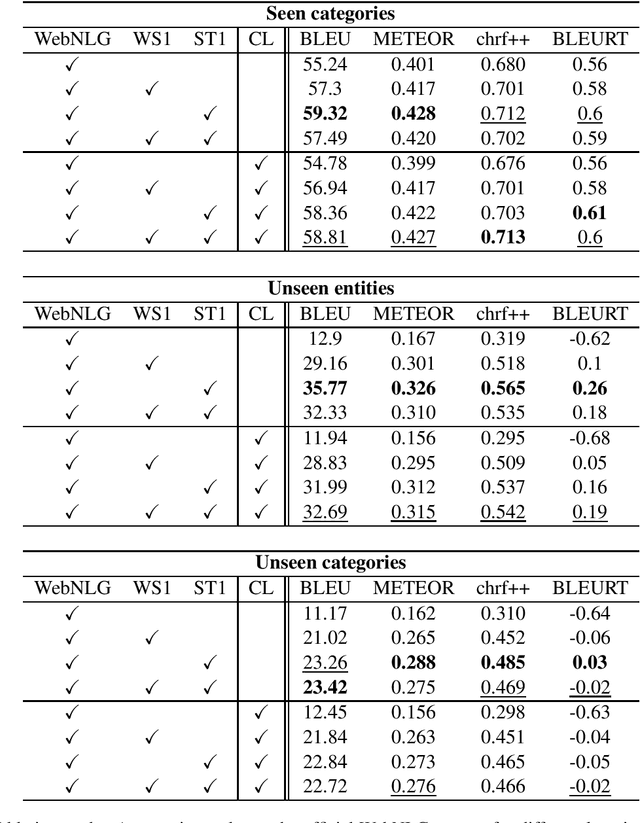
The task of verbalization of RDF triples has known a growth in popularity due to the rising ubiquity of Knowledge Bases (KBs). The formalism of RDF triples is a simple and efficient way to store facts at a large scale. However, its abstract representation makes it difficult for humans to interpret. For this purpose, the WebNLG challenge aims at promoting automated RDF-to-text generation. We propose to leverage pre-trainings from augmented data with the Transformer model using a data augmentation strategy. Our experiment results show a minimum relative increases of 3.73%, 126.05% and 88.16% in BLEU score for seen categories, unseen entities and unseen categories respectively over the standard training.
MaskParse@Deskin at SemEval-2019 Task 1: Cross-lingual UCCA Semantic Parsing using Recursive Masked Sequence Tagging
Oct 07, 2019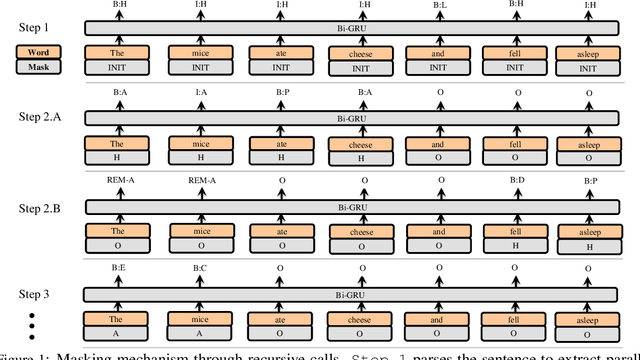
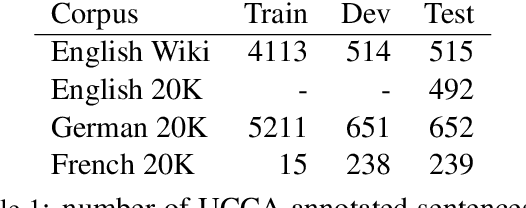
This paper describes our recursive system for SemEval-2019 \textit{ Task 1: Cross-lingual Semantic Parsing with UCCA}. Each recursive step consists of two parts. We first perform semantic parsing using a sequence tagger to estimate the probabilities of the UCCA categories in the sentence. Then, we apply a decoding policy which interprets these probabilities and builds the graph nodes. Parsing is done recursively, we perform a first inference on the sentence to extract the main scenes and links and then we recursively apply our model on the sentence using a masking feature that reflects the decisions made in previous steps. Process continues until the terminal nodes are reached. We choose a standard neural tagger and we focused on our recursive parsing strategy and on the cross lingual transfer problem to develop a robust model for the French language, using only few training samples.
Spoken Conversational Search for General Knowledge
Sep 26, 2019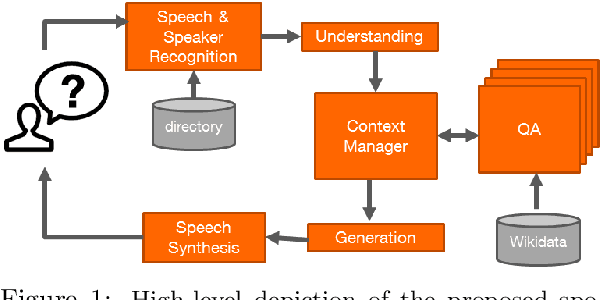

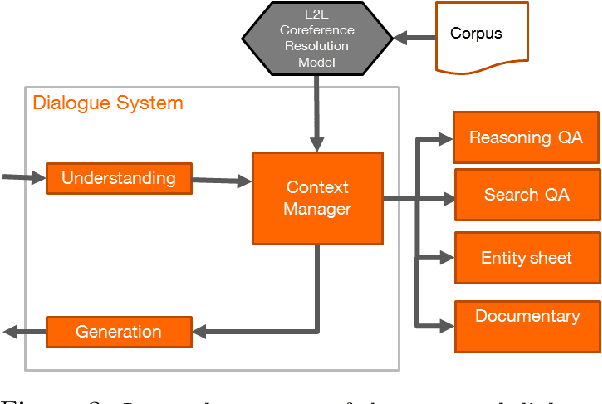
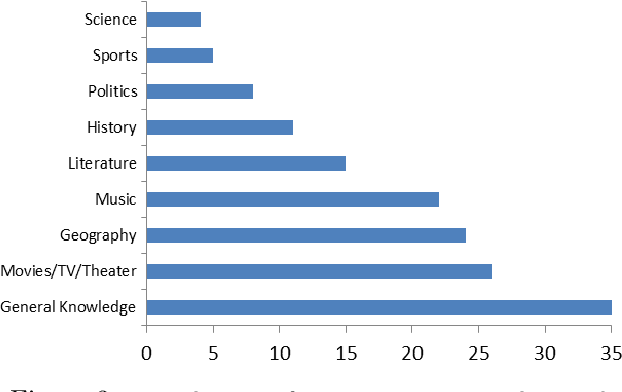
We present a spoken conversational question answering proof of concept that is able to answer questions about general knowledge from Wikidata. The dialogue component does not only orchestrate various components but also solve coreferences and ellipsis.
A Lexical Semantic Database for Verbmobil
Jul 30, 1996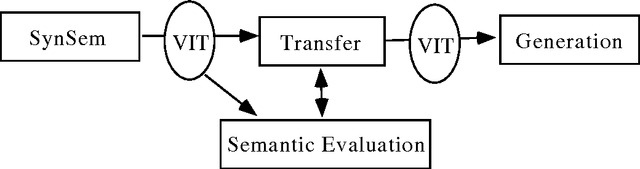



This paper describes the development and use of a lexical semantic database for the Verbmobil speech-to-speech machine translation system. The motivation is to provide a common information source for the distributed development of the semantics, transfer and semantic evaluation modules and to store lexical semantic information application-independently. The database is organized around a set of abstract semantic classes and has been used to define the semantic contributions of the lemmata in the vocabulary of the system, to automatically create semantic lexica and to check the correctness of the semantic representations built up. The semantic classes are modelled using an inheritance hierarchy. The database is implemented using the lexicon formalism LeX4 developed during the project.