 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting a FrameNet Semantic Parser for Spoken Language Understanding Using Adversarial Learning
Oct 07, 2019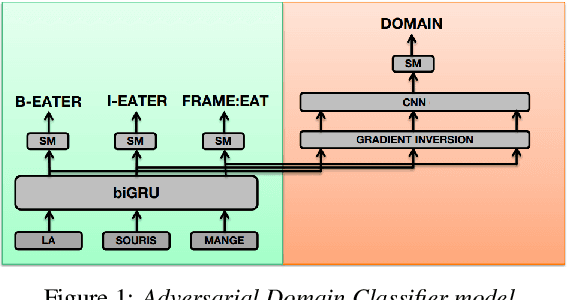
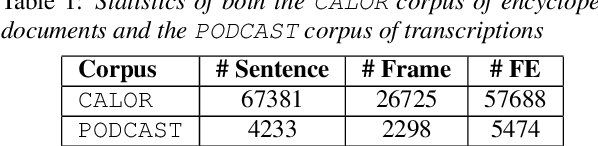
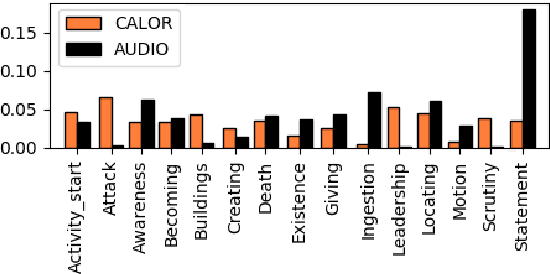
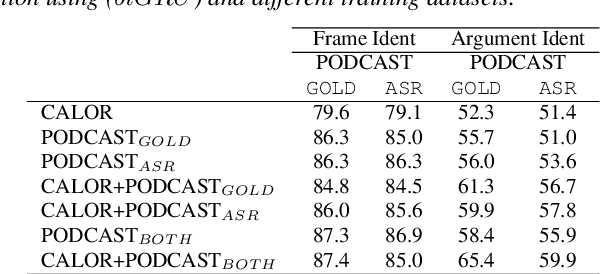
This paper presents a new semantic frame parsing model, based on Berkeley FrameNet, adapted to process spoken documents in order to perform information extraction from broadcast contents. Building upon previous work that had shown the effectiveness of adversarial learning for domain generalization in the context of semantic parsing of encyclopedic written documents, we propose to extend this approach to elocutionary style generalization. The underlying question throughout this study is whether adversarial learning can be used to combine data from different sources and train models on a higher level of abstraction in order to increase their robustness to lexical and stylistic variations as well as automatic speech recognition errors. The proposed strategy is evaluated on a French corpus of encyclopedic written documents and a smaller corpus of radio podcast transcriptions, both annotated with a FrameNet paradigm. We show that adversarial learning increases all models generalization capabilities both on manual and automatic speech transcription as well as on encyclopedic data.
MaskParse@Deskin at SemEval-2019 Task 1: Cross-lingual UCCA Semantic Parsing using Recursive Masked Sequence Tagging
Oct 07, 2019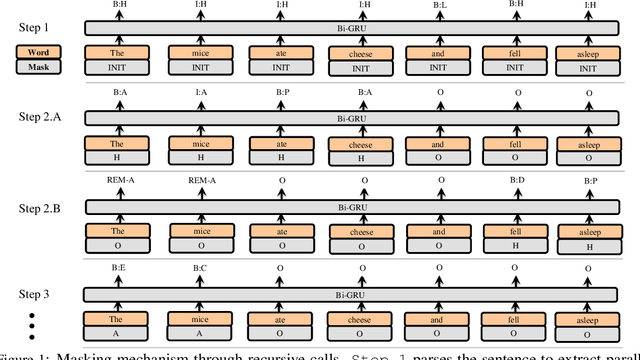
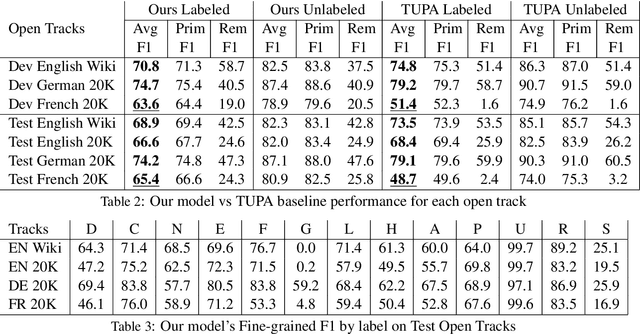
This paper describes our recursive system for SemEval-2019 \textit{ Task 1: Cross-lingual Semantic Parsing with UCCA}. Each recursive step consists of two parts. We first perform semantic parsing using a sequence tagger to estimate the probabilities of the UCCA categories in the sentence. Then, we apply a decoding policy which interprets these probabilities and builds the graph nodes. Parsing is done recursively, we perform a first inference on the sentence to extract the main scenes and links and then we recursively apply our model on the sentence using a masking feature that reflects the decisions made in previous steps. Process continues until the terminal nodes are reached. We choose a standard neural tagger and we focused on our recursive parsing strategy and on the cross lingual transfer problem to develop a robust model for the French language, using only few training samples.
Robust Semantic Parsing with Adversarial Learning for Domain Generalization
Oct 01, 2019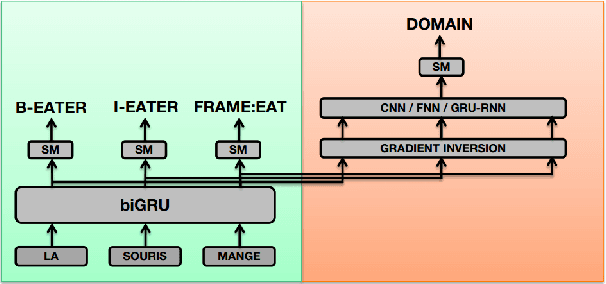


This paper addresses the issue of generalization for Semantic Parsing in an adversarial framework. Building models that are more robust to inter-document variability is crucial for the integration of Semantic Parsing technologies in real applications. The underlying question throughout this study is whether adversarial learning can be used to train models on a higher level of abstraction in order to increase their robustness to lexical and stylistic variations.We propose to perform Semantic Parsing with a domain classification adversarial task without explicit knowledge of the domain. The strategy is first evaluated on a French corpus of encyclopedic documents, annotated with FrameNet, in an information retrieval perspective, then on PropBank Semantic Role Labeling task on the CoNLL-2005 benchmark. We show that adversarial learning increases all models generalization capabilities both on in and out-of-domain data.
Sources of Complexity in Semantic Frame Parsing for Information Extraction
Dec 21, 2018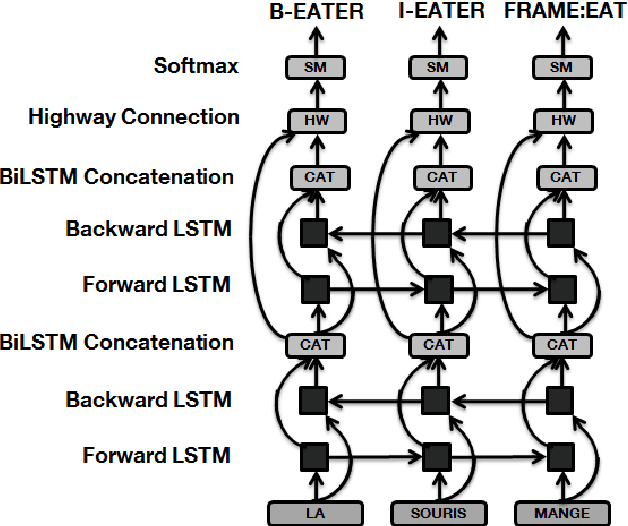

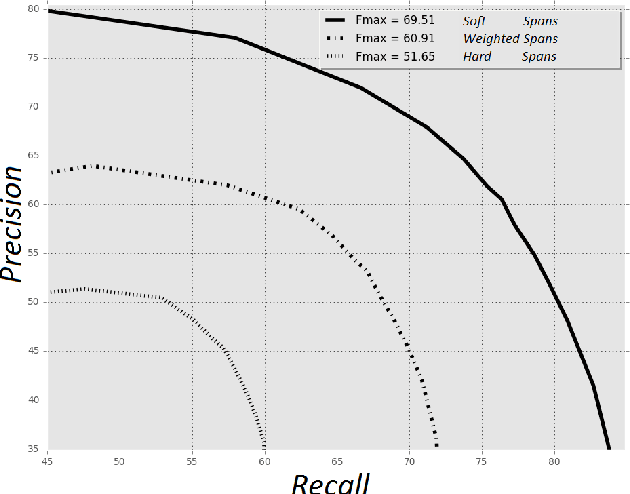
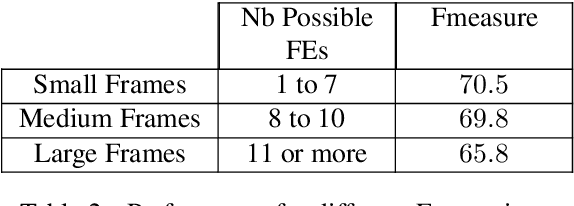
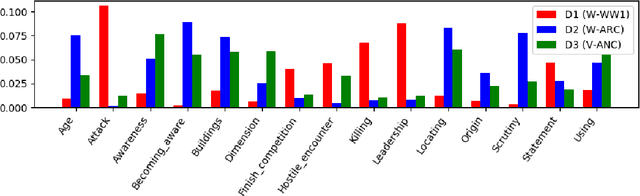
This paper describes a Semantic Frame parsing System based on sequence labeling methods, precisely BiLSTM models with highway connections, for performing information extraction on a corpus of French encyclopedic history texts annotated according to the Berkeley FrameNet formalism. The approach proposed in this study relies on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The purpose of this study is to analyze the task complexity, to highlight the factors that make Semantic Frame parsing a difficult task and to provide detailed evaluations of the performance on different types of frames and sentences.
FrameNet automatic analysis : a study on a French corpus of encyclopedic texts
Dec 19, 2018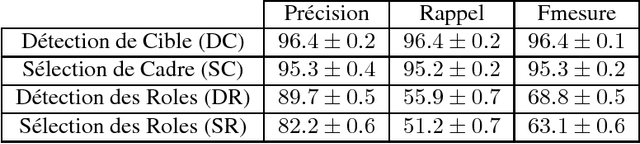



This article presents an automatic frame analysis system evaluated on a corpus of French encyclopedic history texts annotated according to the FrameNet formalism. The chosen approach relies on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The purpose of this study is to analyze the task complexity from several dimensions. Hence we provide detailed evaluations from a feature selection point of view and from the data point of view.
* in French
Semantic Frame Parsing for Information Extraction : the CALOR corpus
Dec 19, 2018


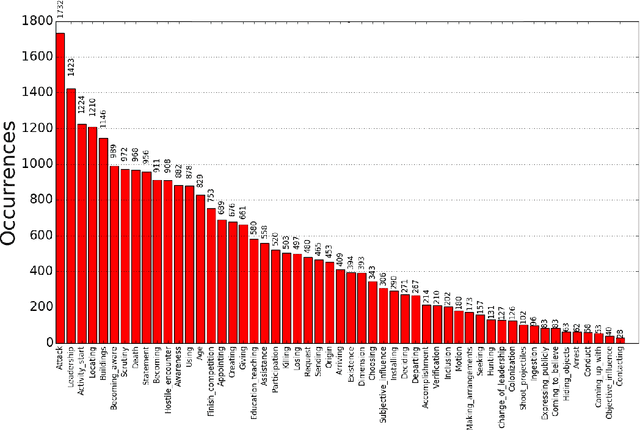
This paper presents a publicly available corpus of French encyclopedic history texts annotated according to the Berkeley FrameNet formalism. The main difference in our approach compared to previous works on semantic parsing with FrameNet is that we are not interested here in full text parsing but rather on partial parsing. The goal is to select from the FrameNet resources the minimal set of frames that are going to be useful for the applicative framework targeted, in our case Information Extraction from encyclopedic documents. Such an approach leverages the manual annotation of larger corpora than those obtained through full text parsing and therefore opens the door to alternative methods for Frame parsing than those used so far on the FrameNet 1.5 benchmark corpus. The approaches compared in this study rely on an integrated sequence labeling model which jointly optimizes frame identification and semantic role segmentation and identification. The models compared are CRFs and multitasks bi-LSTMs.