 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting a FrameNet Semantic Parser for Spoken Language Understanding Using Adversarial Learning
Paper and Code
Oct 07, 2019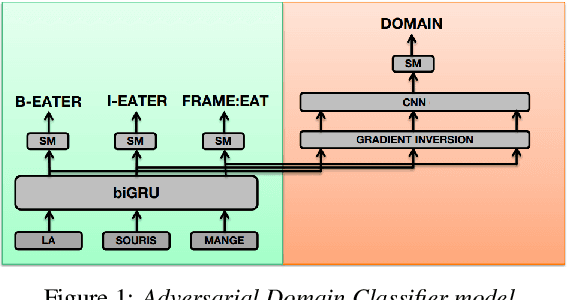
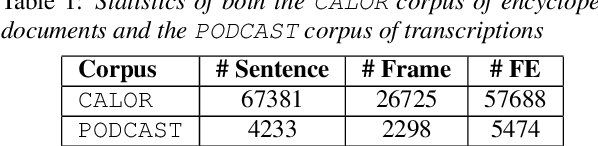
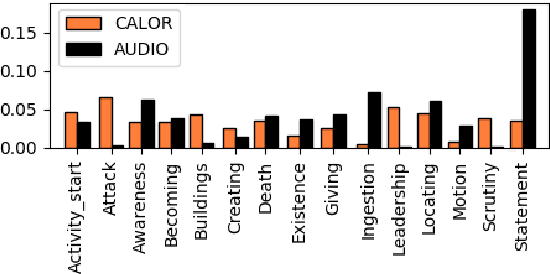
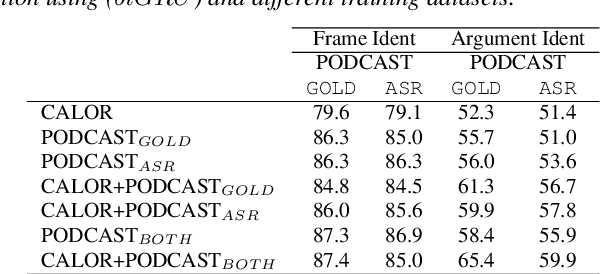
This paper presents a new semantic frame parsing model, based on Berkeley FrameNet, adapted to process spoken documents in order to perform information extraction from broadcast contents. Building upon previous work that had shown the effectiveness of adversarial learning for domain generalization in the context of semantic parsing of encyclopedic written documents, we propose to extend this approach to elocutionary style generalization. The underlying question throughout this study is whether adversarial learning can be used to combine data from different sources and train models on a higher level of abstraction in order to increase their robustness to lexical and stylistic variations as well as automatic speech recognition errors. The proposed strategy is evaluated on a French corpus of encyclopedic written documents and a smaller corpus of radio podcast transcriptions, both annotated with a FrameNet paradigm. We show that adversarial learning increases all models generalization capabilities both on manual and automatic speech transcription as well as on encyclopedic data.