 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
Paper and Code
May 10, 2024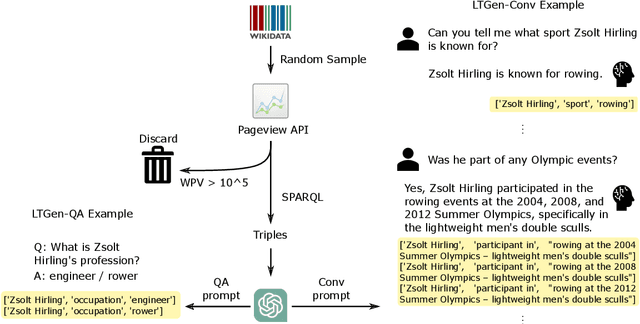
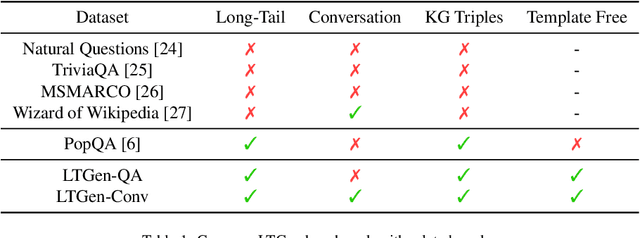
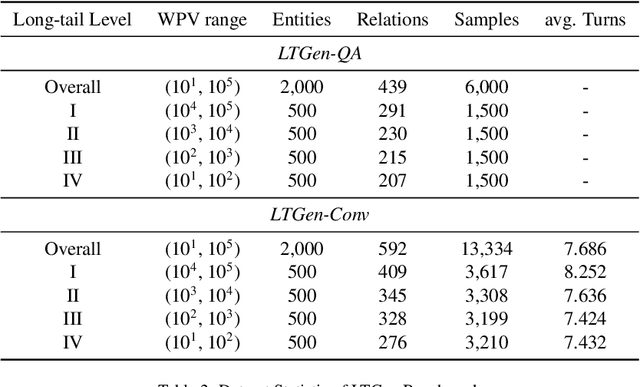
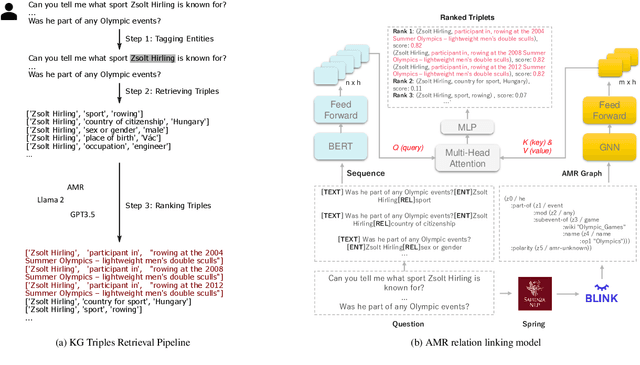
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.