 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
May 14, 2025In recent years, diffusion model has shown its potential across diverse domains from vision generation to language modeling. Transferring its capabilities to modern autonomous driving systems has also emerged as a promising direction.In this work, we propose TransDiffuser, an encoder-decoder based generative trajectory planning model for end-to-end autonomous driving. The encoded scene information serves as the multi-modal conditional input of the denoising decoder. To tackle the mode collapse dilemma in generating high-quality diverse trajectories, we introduce a simple yet effective multi-modal representation decorrelation optimization mechanism during the training process.TransDiffuser achieves PDMS of 94.85 on the NAVSIM benchmark, surpassing previous state-of-the-art methods without any anchor-based prior trajectories.
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
Mar 13, 2025


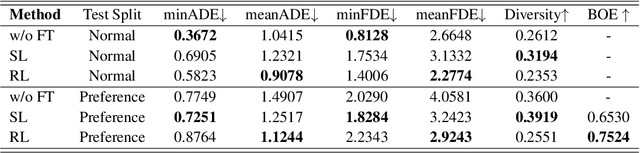
Generating human-like and adaptive trajectories is essential for autonomous driving in dynamic environments. While generative models have shown promise in synthesizing feasible trajectories, they often fail to capture the nuanced variability of human driving styles due to dataset biases and distributional shifts. To address this, we introduce TrajHF, a human feedback-driven finetuning framework for generative trajectory models, designed to align motion planning with diverse driving preferences. TrajHF incorporates multi-conditional denoiser and reinforcement learning with human feedback to refine multi-modal trajectory generation beyond conventional imitation learning. This enables better alignment with human driving preferences while maintaining safety and feasibility constraints. TrajHF achieves PDMS of 93.95 on NavSim benchmark, significantly exceeding other methods. TrajHF sets a new paradigm for personalized and adaptable trajectory generation in autonomous driving.
Generalizing Motion Planners with Mixture of Experts for Autonomous Driving
Oct 21, 2024



Large real-world driving datasets have sparked significant research into various aspects of data-driven motion planners for autonomous driving. These include data augmentation, model architecture, reward design, training strategies, and planner pipelines. These planners promise better generalizations on complicated and few-shot cases than previous methods. However, experiment results show that many of these approaches produce limited generalization abilities in planning performance due to overly complex designs or training paradigms. In this paper, we review and benchmark previous methods focusing on generalizations. The experimental results indicate that as models are appropriately scaled, many design elements become redundant. We introduce StateTransformer-2 (STR2), a scalable, decoder-only motion planner that uses a Vision Transformer (ViT) encoder and a mixture-of-experts (MoE) causal Transformer architecture. The MoE backbone addresses modality collapse and reward balancing by expert routing during training. Extensive experiments on the NuPlan dataset show that our method generalizes better than previous approaches across different test sets and closed-loop simulations. Furthermore, we assess its scalability on billions of real-world urban driving scenarios, demonstrating consistent accuracy improvements as both data and model size grow.