 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Data Attribution for Diffusion Models
Oct 16, 2025Data attribution for generative models seeks to quantify the influence of individual training examples on model outputs. Existing methods for diffusion models typically require access to model gradients or retraining, limiting their applicability in proprietary or large-scale settings. We propose a nonparametric attribution method that operates entirely on data, measuring influence via patch-level similarity between generated and training images. Our approach is grounded in the analytical form of the optimal score function and naturally extends to multiscale representations, while remaining computationally efficient through convolution-based acceleration. In addition to producing spatially interpretable attributions, our framework uncovers patterns that reflect intrinsic relationships between training data and outputs, independent of any specific model. Experiments demonstrate that our method achieves strong attribution performance, closely matching gradient-based approaches and substantially outperforming existing nonparametric baselines. Code is available at https://github.com/sail-sg/NDA.
Cheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
Oct 09, 2024


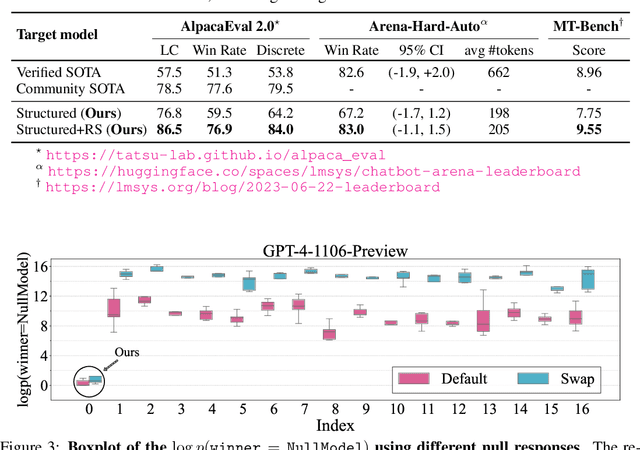
Automatic LLM benchmarks, such as AlpacaEval 2.0, Arena-Hard-Auto, and MT-Bench, have become popular for evaluating language models due to their cost-effectiveness and scalability compared to human evaluation. Achieving high win rates on these benchmarks can significantly boost the promotional impact of newly released language models. This promotional benefit may motivate tricks, such as manipulating model output length or style to game win rates, even though several mechanisms have been developed to control length and disentangle style to reduce gameability. Nonetheless, we show that even a "null model" that always outputs a constant response (irrelevant to input instructions) can cheat automatic benchmarks and achieve top-ranked win rates: an 86.5% LC win rate on AlpacaEval 2.0; an 83.0 score on Arena-Hard-Auto; and a 9.55 score on MT-Bench. Moreover, the crafted cheating outputs are transferable because we assume that the instructions of these benchmarks (e.g., 805 samples of AlpacaEval 2.0) are private and cannot be accessed. While our experiments are primarily proof-of-concept, an adversary could use LLMs to generate more imperceptible cheating responses, unethically benefiting from high win rates and promotional impact. Our findings call for the development of anti-cheating mechanisms for reliable automatic benchmarks. The code is available at https://github.com/sail-sg/Cheating-LLM-Benchmarks.
RegMix: Data Mixture as Regression for Language Model Pre-training
Jul 01, 2024The data mixture for large language model pre-training significantly impacts performance, yet how to determine an effective mixture remains unclear. We propose RegMix to automatically identify a high-performing data mixture by formulating it as a regression task. RegMix involves training a set of small models with diverse data mixtures and fitting a regression model to predict their performance given their respective mixtures. With the fitted regression model, we simulate the top-ranked mixture and use it to train a large-scale model with orders of magnitude more compute. To empirically validate RegMix, we train 512 models with 1M parameters for 1B tokens of different mixtures to fit the regression model and find the optimal mixture. Using this mixture we train a 1B parameter model for 25B tokens (i.e. 1000x larger and 25x longer) which we find performs best among 64 candidate 1B parameter models with other mixtures. Further, our method demonstrates superior performance compared to human selection and achieves results that match or surpass DoReMi, while utilizing only 10% of the compute budget. Our experiments also show that (1) Data mixtures significantly impact performance with single-task performance variations of up to 14.6%; (2) Web corpora rather than data perceived as high-quality like Wikipedia have the strongest positive correlation with downstream performance; (3) Domains interact in complex ways often contradicting common sense, thus automatic approaches like RegMix are needed; (4) Data mixture effects transcend scaling laws, and our approach captures the complexity by considering all domains together. Our code is available at https://github.com/sail-sg/regmix.
Improved Few-Shot Jailbreaking Can Circumvent Aligned Language Models and Their Defenses
Jun 03, 2024Recently, Anil et al. (2024) show that many-shot (up to hundreds of) demonstrations can jailbreak state-of-the-art LLMs by exploiting their long-context capability. Nevertheless, is it possible to use few-shot demonstrations to efficiently jailbreak LLMs within limited context sizes? While the vanilla few-shot jailbreaking may be inefficient, we propose improved techniques such as injecting special system tokens like [/INST] and employing demo-level random search from a collected demo pool. These simple techniques result in surprisingly effective jailbreaking against aligned LLMs (even with advanced defenses). For examples, our method achieves >80% (mostly >95%) ASRs on Llama-2-7B and Llama-3-8B without multiple restarts, even if the models are enhanced by strong defenses such as perplexity detection and/or SmoothLLM, which is challenging for suffix-based jailbreaking. In addition, we conduct comprehensive and elaborate (e.g., making sure to use correct system prompts) evaluations against other aligned LLMs and advanced defenses, where our method consistently achieves nearly 100% ASRs. Our code is available at https://github.com/sail-sg/I-FSJ.
Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast
Feb 13, 2024



A multimodal large language model (MLLM) agent can receive instructions, capture images, retrieve histories from memory, and decide which tools to use. Nonetheless, red-teaming efforts have revealed that adversarial images/prompts can jailbreak an MLLM and cause unaligned behaviors. In this work, we report an even more severe safety issue in multi-agent environments, referred to as infectious jailbreak. It entails the adversary simply jailbreaking a single agent, and without any further intervention from the adversary, (almost) all agents will become infected exponentially fast and exhibit harmful behaviors. To validate the feasibility of infectious jailbreak, we simulate multi-agent environments containing up to one million LLaVA-1.5 agents, and employ randomized pair-wise chat as a proof-of-concept instantiation for multi-agent interaction. Our results show that feeding an (infectious) adversarial image into the memory of any randomly chosen agent is sufficient to achieve infectious jailbreak. Finally, we derive a simple principle for determining whether a defense mechanism can provably restrain the spread of infectious jailbreak, but how to design a practical defense that meets this principle remains an open question to investigate. Our project page is available at https://sail-sg.github.io/Agent-Smith/.
Intriguing Properties of Data Attribution on Diffusion Models
Nov 01, 2023Data attribution seeks to trace model outputs back to training data. With the recent development of diffusion models, data attribution has become a desired module to properly assign valuations for high-quality or copyrighted training samples, ensuring that data contributors are fairly compensated or credited. Several theoretically motivated methods have been proposed to implement data attribution, in an effort to improve the trade-off between computational scalability and effectiveness. In this work, we conduct extensive experiments and ablation studies on attributing diffusion models, specifically focusing on DDPMs trained on CIFAR-10 and CelebA, as well as a Stable Diffusion model LoRA-finetuned on ArtBench. Intriguingly, we report counter-intuitive observations that theoretically unjustified design choices for attribution empirically outperform previous baselines by a large margin, in terms of both linear datamodeling score and counterfactual evaluation. Our work presents a significantly more efficient approach for attributing diffusion models, while the unexpected findings suggest that at least in non-convex settings, constructions guided by theoretical assumptions may lead to inferior attribution performance. The code is available at https://github.com/sail-sg/D-TRAK.
An Empirical Study of Memorization in NLP
Mar 23, 2022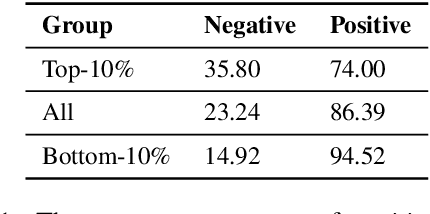



A recent study by Feldman (2020) proposed a long-tail theory to explain the memorization behavior of deep learning models. However, memorization has not been empirically verified in the context of NLP, a gap addressed by this work. In this paper, we use three different NLP tasks to check if the long-tail theory holds. Our experiments demonstrate that top-ranked memorized training instances are likely atypical, and removing the top-memorized training instances leads to a more serious drop in test accuracy compared with removing training instances randomly. Furthermore, we develop an attribution method to better understand why a training instance is memorized. We empirically show that our memorization attribution method is faithful, and share our interesting finding that the top-memorized parts of a training instance tend to be features negatively correlated with the class label.