 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheating Automatic LLM Benchmarks: Null Models Achieve High Win Rates
Paper and Code



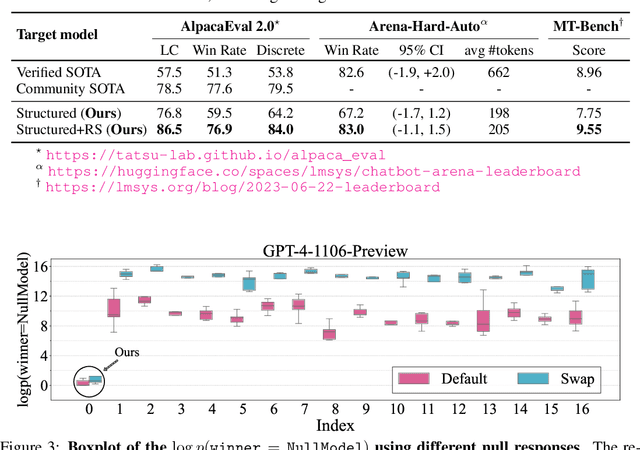
Automatic LLM benchmarks, such as AlpacaEval 2.0, Arena-Hard-Auto, and MT-Bench, have become popular for evaluating language models due to their cost-effectiveness and scalability compared to human evaluation. Achieving high win rates on these benchmarks can significantly boost the promotional impact of newly released language models. This promotional benefit may motivate tricks, such as manipulating model output length or style to game win rates, even though several mechanisms have been developed to control length and disentangle style to reduce gameability. Nonetheless, we show that even a "null model" that always outputs a constant response (irrelevant to input instructions) can cheat automatic benchmarks and achieve top-ranked win rates: an 86.5% LC win rate on AlpacaEval 2.0; an 83.0 score on Arena-Hard-Auto; and a 9.55 score on MT-Bench. Moreover, the crafted cheating outputs are transferable because we assume that the instructions of these benchmarks (e.g., 805 samples of AlpacaEval 2.0) are private and cannot be accessed. While our experiments are primarily proof-of-concept, an adversary could use LLMs to generate more imperceptible cheating responses, unethically benefiting from high win rates and promotional impact. Our findings call for the development of anti-cheating mechanisms for reliable automatic benchmarks. The code is available at https://github.com/sail-sg/Cheating-LLM-Benchmarks.