 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxe: A Simple Unified Layout Abstraction for Machine Learning Compilers
Jan 27, 2026Scaling modern deep learning workloads demands coordinated placement of data and compute across device meshes, memory hierarchies, and heterogeneous accelerators. We present Axe Layout, a hardware-aware abstraction that maps logical tensor coordinates to a multi-axis physical space via named axes. Axe unifies tiling, sharding, replication, and offsets across inter-device distribution and on-device layouts, enabling collective primitives to be expressed consistently from device meshes to threads. Building on Axe, we design a multi-granularity, distribution-aware DSL and compiler that composes thread-local control with collective operators in a single kernel. Experiments show that our unified approach can bring performance close to hand-tuned kernels on across latest GPU devices and multi-device environments and accelerator backends.
Gecko: An Efficient Neural Architecture Inherently Processing Sequences with Arbitrary Lengths
Jan 10, 2026Designing a unified neural network to efficiently and inherently process sequential data with arbitrary lengths is a central and challenging problem in sequence modeling. The design choices in Transformer, including quadratic complexity and weak length extrapolation, have limited their ability to scale to long sequences. In this work, we propose Gecko, a neural architecture that inherits the design of Mega and Megalodon (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability to capture long range dependencies, including timestep decay normalization, sliding chunk attention mechanism, and adaptive working memory. In a controlled pretraining comparison with Llama2 and Megalodon in the scale of 7 billion parameters and 2 trillion training tokens, Gecko achieves better efficiency and long-context scalability. Gecko reaches a training loss of 1.68, significantly outperforming Llama2-7B (1.75) and Megalodon-7B (1.70), and landing close to Llama2-13B (1.67). Notably, without relying on any context-extension techniques, Gecko exhibits inherent long-context processing and retrieval capabilities, stably handling sequences of up to 4 million tokens and retrieving information from contexts up to $4\times$ longer than its attention window. Code: https://github.com/XuezheMax/gecko-llm
Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs
Dec 22, 2025We introduce Mirage Persistent Kernel (MPK), the first compiler and runtime system that automatically transforms multi-GPU model inference into a single high-performance megakernel. MPK introduces an SM-level graph representation that captures data dependencies at the granularity of individual streaming multiprocessors (SMs), enabling cross-operator software pipelining, fine-grained kernel overlap, and other previously infeasible GPU optimizations. The MPK compiler lowers tensor programs into highly optimized SM-level task graphs and generates optimized CUDA implementations for all tasks, while the MPK in-kernel parallel runtime executes these tasks within a single mega-kernel using decentralized scheduling across SMs. Together, these components provide end-to-end kernel fusion with minimal developer effort, while preserving the flexibility of existing programming models. Our evaluation shows that MPK significantly outperforms existing kernel-per-operator LLM serving systems by reducing end-to-end inference latency by up to 1.7x, pushing LLM inference performance close to hardware limits. MPK is publicly available at https://github.com/mirage-project/mirage.
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Jan 02, 2025



Transformers, driven by attention mechanisms, form the foundation of large language models (LLMs). As these models scale up, efficient GPU attention kernels become essential for high-throughput and low-latency inference. Diverse LLM applications demand flexible and high-performance attention solutions. We present FlashInfer: a customizable and efficient attention engine for LLM serving. FlashInfer tackles KV-cache storage heterogeneity using block-sparse format and composable formats to optimize memory access and reduce redundancy. It also offers a customizable attention template, enabling adaptation to various settings through Just-In-Time (JIT) compilation. Additionally, FlashInfer's load-balanced scheduling algorithm adjusts to dynamism of user requests while maintaining compatibility with CUDAGraph which requires static configuration. FlashInfer have been integrated into leading LLM serving frameworks like SGLang, vLLM and MLC-Engine. Comprehensive kernel-level and end-to-end evaluations demonstrate FlashInfer's ability to significantly boost kernel performance across diverse inference scenarios: compared to state-of-the-art LLM serving solutions, FlashInfer achieve 29-69% inter-token-latency reduction compared to compiler backends for LLM serving benchmark, 28-30% latency reduction for long-context inference, and 13-17% speedup for LLM serving with parallel generation.
WebLLM: A High-Performance In-Browser LLM Inference Engine
Dec 20, 2024

Advancements in large language models (LLMs) have unlocked remarkable capabilities. While deploying these models typically requires server-grade GPUs and cloud-based inference, the recent emergence of smaller open-source models and increasingly powerful consumer devices have made on-device deployment practical. The web browser as a platform for on-device deployment is universally accessible, provides a natural agentic environment, and conveniently abstracts out the different backends from diverse device vendors. To address this opportunity, we introduce WebLLM, an open-source JavaScript framework that enables high-performance LLM inference entirely within web browsers. WebLLM provides an OpenAI-style API for seamless integration into web applications, and leverages WebGPU for efficient local GPU acceleration and WebAssembly for performant CPU computation. With machine learning compilers MLC-LLM and Apache TVM, WebLLM leverages optimized WebGPU kernels, overcoming the absence of performant WebGPU kernel libraries. Evaluations show that WebLLM can retain up to 80% native performance on the same device, with room to further close the gap. WebLLM paves the way for universally accessible, privacy-preserving, personalized, and locally powered LLM applications in web browsers. The code is available at: https://github.com/mlc-ai/web-llm.
XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models
Nov 22, 2024



The applications of LLM Agents are becoming increasingly complex and diverse, leading to a high demand for structured outputs that can be parsed into code, structured function calls, and embodied agent commands. These developments bring significant demands for structured generation in LLM inference. Context-free grammar is a flexible approach to enable structured generation via constrained decoding. However, executing context-free grammar requires going through several stack states over all tokens in vocabulary during runtime, bringing non-negligible overhead for structured generation. In this paper, we propose XGrammar, a flexible and efficient structure generation engine for large language models. XGrammar accelerates context-free grammar execution by dividing the vocabulary into context-independent tokens that can be prechecked and context-dependent tokens that need to be interpreted during runtime. We further build transformations to expand the grammar context and reduce the number of context-independent tokens. Additionally, we build an efficient persistent stack to accelerate the context-dependent token checks. Finally, we co-design the grammar engine with LLM inference engine to overlap grammar computation with GPU executions. Evaluation results show that XGrammar can achieve up to 100x speedup over existing solutions. Combined with an LLM inference engine, it can generate near-zero overhead structure generation in end-to-end low-LLM serving.
Emerging Platforms Meet Emerging LLMs: A Year-Long Journey of Top-Down Development
Apr 14, 2024Deploying machine learning (ML) on diverse computing platforms is crucial to accelerate and broaden their applications. However, it presents significant software engineering challenges due to the fast evolution of models, especially the recent \llmfull{s} (\llm{s}), and the emergence of new computing platforms. Current ML frameworks are primarily engineered for CPU and CUDA platforms, leaving a big gap in enabling emerging ones like Metal, Vulkan, and WebGPU. While a traditional bottom-up development pipeline fails to close the gap timely, we introduce TapML, a top-down approach and tooling designed to streamline the deployment of ML systems on diverse platforms, optimized for developer productivity. Unlike traditional bottom-up methods, which involve extensive manual testing and debugging, TapML automates unit testing through test carving and adopts a migration-based strategy for gradually offloading model computations from mature source platforms to emerging target platforms. By leveraging realistic inputs and remote connections for gradual target offloading, TapML accelerates the validation and minimizes debugging scopes, significantly optimizing development efforts. TapML was developed and applied through a year-long, real-world effort that successfully deployed significant emerging models and platforms. Through serious deployments of 82 emerging models in 17 distinct architectures across 5 emerging platforms, we showcase the effectiveness of TapML in enhancing developer productivity while ensuring model reliability and efficiency. Furthermore, we summarize comprehensive case studies from our real-world development, offering best practices for developing emerging ML systems.
Relax: Composable Abstractions for End-to-End Dynamic Machine Learning
Nov 01, 2023



Dynamic shape computations have become critical in modern machine learning workloads, especially in emerging large language models. The success of these models has driven demand for deploying them to a diverse set of backend environments. In this paper, we present Relax, a compiler abstraction for optimizing end-to-end dynamic machine learning workloads. Relax introduces first-class symbolic shape annotations to track dynamic shape computations globally across the program. It also introduces a cross-level abstraction that encapsulates computational graphs, loop-level tensor programs, and library calls in a single representation to enable cross-level optimizations. We build an end-to-end compilation framework using the proposed approach to optimize dynamic shape models. Experimental results on large language models show that Relax delivers performance competitive with state-of-the-art hand-optimized systems across platforms and enables deployment of emerging dynamic models to a broader set of environments, including mobile phones, embedded devices, and web browsers.
SparseTIR: Composable Abstractions for Sparse Compilation in Deep Learning
Jul 11, 2022



Sparse tensors are rapidly becoming critical components of modern deep learning workloads. However, developing high-performance sparse operators can be difficult and tedious, and existing vendor libraries cannot satisfy the escalating demands from new operators. Sparse tensor compilers simplify the development of operators, but efficient sparse compilation for deep learning remains challenging because a single sparse format cannot maximize hardware efficiency, and single-shot compilers cannot keep up with latest hardware and system advances. We show that the key to addressing both challenges is two forms of composability. In this paper, we propose SparseTIR, a sparse tensor compilation abstraction that offers composable formats and composable transformations for deep learning workloads. SparseTIR constructs a search space over these composable components for performance tuning. With these improvements, SparseTIR obtains consistent performance speedups vs vendor libraries on GPUs for single operators: 1.1-3.3x for GNN operators and 1.1-4.4x for sparse transformer operators. SparseTIR also accelerates end-to-end GNNs by 1.1-2.2x for GraphSAGE training and 0.9-26x for RGCN inference.
TensorIR: An Abstraction for Automatic Tensorized Program Optimization
Jul 09, 2022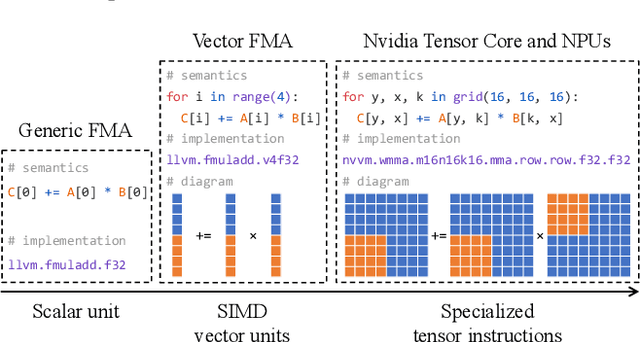

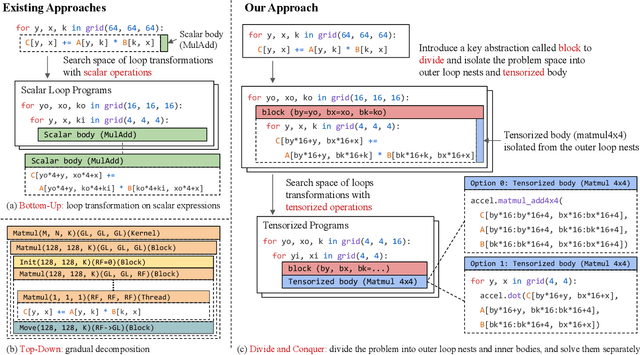
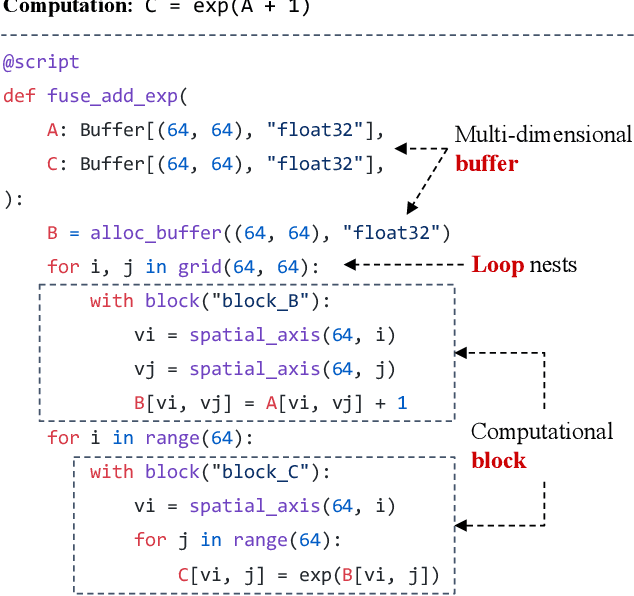
Deploying deep learning models on various devices has become an important topic. The wave of hardware specialization brings a diverse set of acceleration primitives for multi-dimensional tensor computations. These new acceleration primitives, along with the emerging machine learning models, bring tremendous engineering challenges. In this paper, we present TensorIR, a compiler abstraction for optimizing programs with these tensor computation primitives. TensorIR generalizes the loop nest representation used in existing machine learning compilers to bring tensor computation as the first-class citizen. Finally, we build an end-to-end framework on top of our abstraction to automatically optimize deep learning models for given tensor computation primitives. Experimental results show that TensorIR compilation automatically uses the tensor computation primitives for given hardware backends and delivers performance that is competitive to state-of-art hand-optimized systems across platforms.