 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebLLM: A High-Performance In-Browser LLM Inference Engine
Dec 20, 2024

Advancements in large language models (LLMs) have unlocked remarkable capabilities. While deploying these models typically requires server-grade GPUs and cloud-based inference, the recent emergence of smaller open-source models and increasingly powerful consumer devices have made on-device deployment practical. The web browser as a platform for on-device deployment is universally accessible, provides a natural agentic environment, and conveniently abstracts out the different backends from diverse device vendors. To address this opportunity, we introduce WebLLM, an open-source JavaScript framework that enables high-performance LLM inference entirely within web browsers. WebLLM provides an OpenAI-style API for seamless integration into web applications, and leverages WebGPU for efficient local GPU acceleration and WebAssembly for performant CPU computation. With machine learning compilers MLC-LLM and Apache TVM, WebLLM leverages optimized WebGPU kernels, overcoming the absence of performant WebGPU kernel libraries. Evaluations show that WebLLM can retain up to 80% native performance on the same device, with room to further close the gap. WebLLM paves the way for universally accessible, privacy-preserving, personalized, and locally powered LLM applications in web browsers. The code is available at: https://github.com/mlc-ai/web-llm.
Federated Evaluation and Tuning for On-Device Personalization: System Design & Applications
Feb 16, 2021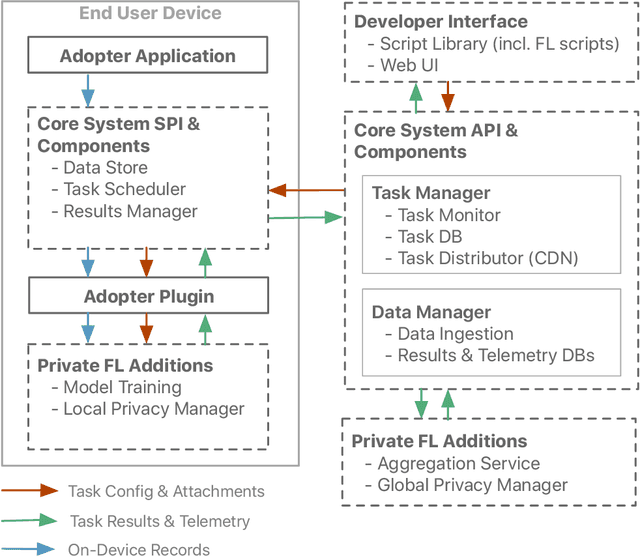
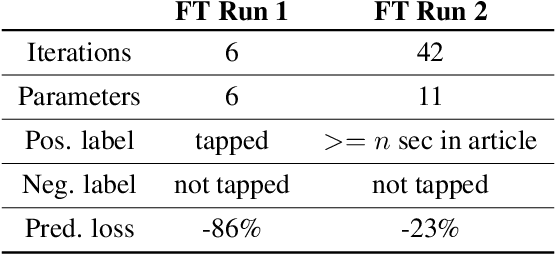

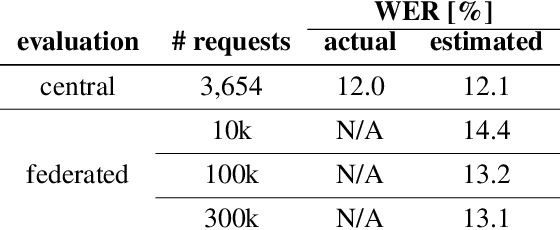
We describe the design of our federated task processing system. Originally, the system was created to support two specific federated tasks: evaluation and tuning of on-device ML systems, primarily for the purpose of personalizing these systems. In recent years, support for an additional federated task has been added: federated learning (FL) of deep neural networks. To our knowledge, only one other system has been described in literature that supports FL at scale. We include comparisons to that system to help discuss design decisions and attached trade-offs. Finally, we describe two specific large scale personalization use cases in detail to showcase the applicability of federated tuning to on-device personalization and to highlight application specific solutions.