 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePithTrain: A Compact and Agent-Native MoE Training System
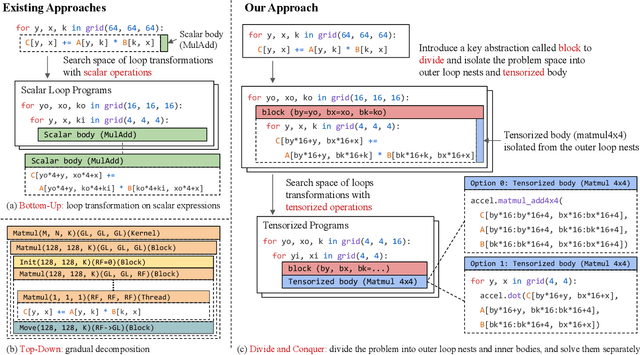
May 29, 2026Mixture-of-Experts (MoE) has become the dominant architecture for frontier language models. To meet this demand, production frameworks have built optimized MoE training stacks over years of engineering effort. Yet evolving these stacks for new architectures and system optimizations remains expensive. With the rise of AI coding agents, they could automate parts of training-framework development and accelerate this evolution. But applying them to these existing frameworks carries hidden costs, invisible to today's throughput-only evaluations. We name this missing dimension agent-task efficiency (ATE): the cost of using coding agents to understand, operate, and extend a framework. Grounded in four agent-native design principles, we build PithTrain, a compact, agent-native MoE training framework. We further introduce ATE-Bench, covering real-world training-framework tasks. Our evaluation shows PithTrain matches the throughput of production frameworks, and on ATE-Bench, PithTrain enables higher agent-task efficiency, with up to 62% fewer Agent Turns and 64% less Active GPU Time.
Relax: Composable Abstractions for End-to-End Dynamic Machine Learning
Nov 01, 2023



Dynamic shape computations have become critical in modern machine learning workloads, especially in emerging large language models. The success of these models has driven demand for deploying them to a diverse set of backend environments. In this paper, we present Relax, a compiler abstraction for optimizing end-to-end dynamic machine learning workloads. Relax introduces first-class symbolic shape annotations to track dynamic shape computations globally across the program. It also introduces a cross-level abstraction that encapsulates computational graphs, loop-level tensor programs, and library calls in a single representation to enable cross-level optimizations. We build an end-to-end compilation framework using the proposed approach to optimize dynamic shape models. Experimental results on large language models show that Relax delivers performance competitive with state-of-the-art hand-optimized systems across platforms and enables deployment of emerging dynamic models to a broader set of environments, including mobile phones, embedded devices, and web browsers.
RAF: Holistic Compilation for Deep Learning Model Training
Mar 08, 2023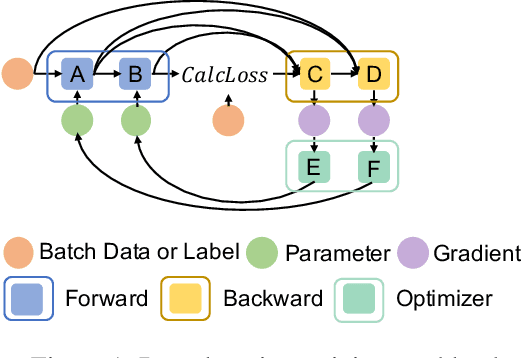
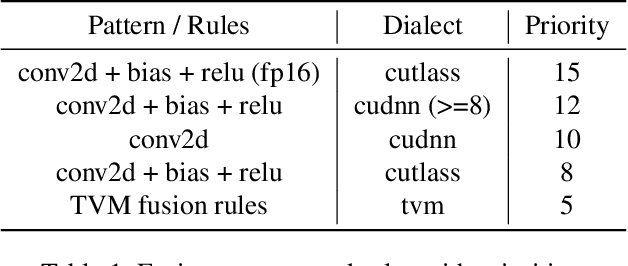
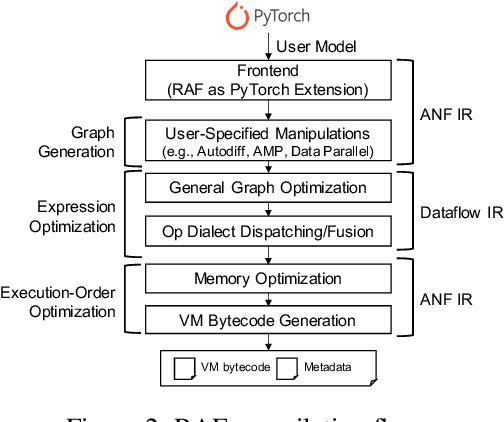

As deep learning is pervasive in modern applications, many deep learning frameworks are presented for deep learning practitioners to develop and train DNN models rapidly. Meanwhile, as training large deep learning models becomes a trend in recent years, the training throughput and memory footprint are getting crucial. Accordingly, optimizing training workloads with compiler optimizations is inevitable and getting more and more attentions. However, existing deep learning compilers (DLCs) mainly target inference and do not incorporate holistic optimizations, such as automatic differentiation and automatic mixed precision, in training workloads. In this paper, we present RAF, a deep learning compiler for training. Unlike existing DLCs, RAF accepts a forward model and in-house generates a training graph. Accordingly, RAF is able to systematically consolidate graph optimizations for performance, memory and distributed training. In addition, to catch up to the state-of-the-art performance with hand-crafted kernel libraries as well as tensor compilers, RAF proposes an operator dialect mechanism to seamlessly integrate all possible kernel implementations. We demonstrate that by in-house training graph generation and operator dialect mechanism, we are able to perform holistic optimizations and achieve either better training throughput or larger batch size against PyTorch (eager and torchscript mode), XLA, and DeepSpeed for popular transformer models on GPUs.
SparseTIR: Composable Abstractions for Sparse Compilation in Deep Learning
Jul 11, 2022



Sparse tensors are rapidly becoming critical components of modern deep learning workloads. However, developing high-performance sparse operators can be difficult and tedious, and existing vendor libraries cannot satisfy the escalating demands from new operators. Sparse tensor compilers simplify the development of operators, but efficient sparse compilation for deep learning remains challenging because a single sparse format cannot maximize hardware efficiency, and single-shot compilers cannot keep up with latest hardware and system advances. We show that the key to addressing both challenges is two forms of composability. In this paper, we propose SparseTIR, a sparse tensor compilation abstraction that offers composable formats and composable transformations for deep learning workloads. SparseTIR constructs a search space over these composable components for performance tuning. With these improvements, SparseTIR obtains consistent performance speedups vs vendor libraries on GPUs for single operators: 1.1-3.3x for GNN operators and 1.1-4.4x for sparse transformer operators. SparseTIR also accelerates end-to-end GNNs by 1.1-2.2x for GraphSAGE training and 0.9-26x for RGCN inference.
TensorIR: An Abstraction for Automatic Tensorized Program Optimization
Jul 09, 2022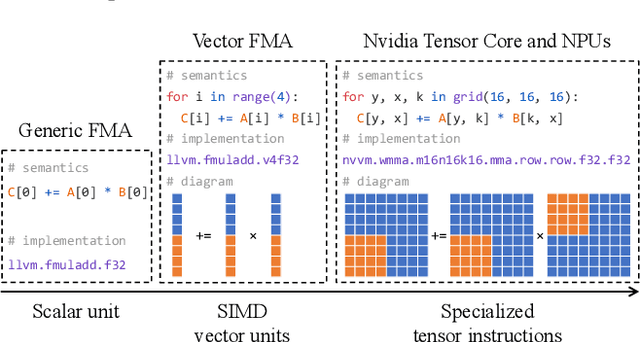

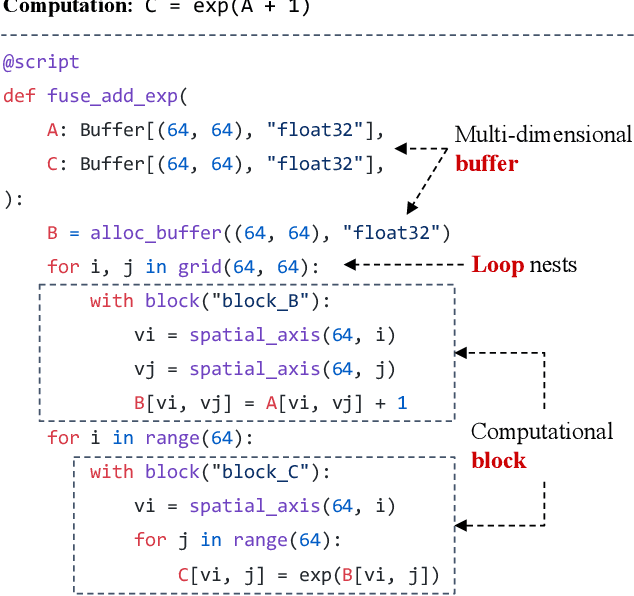
Deploying deep learning models on various devices has become an important topic. The wave of hardware specialization brings a diverse set of acceleration primitives for multi-dimensional tensor computations. These new acceleration primitives, along with the emerging machine learning models, bring tremendous engineering challenges. In this paper, we present TensorIR, a compiler abstraction for optimizing programs with these tensor computation primitives. TensorIR generalizes the loop nest representation used in existing machine learning compilers to bring tensor computation as the first-class citizen. Finally, we build an end-to-end framework on top of our abstraction to automatically optimize deep learning models for given tensor computation primitives. Experimental results show that TensorIR compilation automatically uses the tensor computation primitives for given hardware backends and delivers performance that is competitive to state-of-art hand-optimized systems across platforms.
Tensor Program Optimization with Probabilistic Programs
May 26, 2022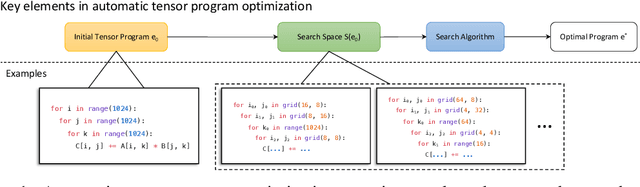

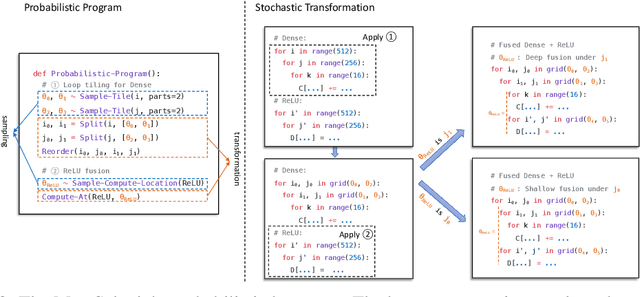
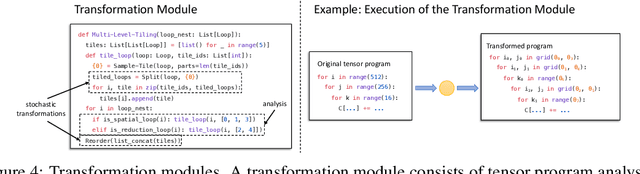
Automatic optimization for tensor programs becomes increasingly important as we deploy deep learning in various environments, and efficient optimization relies on a rich search space and effective search. Most existing efforts adopt a search space which lacks the ability to efficiently enable domain experts to grow the search space. This paper introduces MetaSchedule, a domain-specific probabilistic programming language abstraction to construct a rich search space of tensor programs. Our abstraction allows domain experts to analyze the program, and easily propose stochastic choices in a modular way to compose program transformation accordingly. We also build an end-to-end learning-driven framework to find an optimized program for a given search space. Experimental results show that MetaSchedule can cover the search space used in the state-of-the-art tensor program optimization frameworks in a modular way. Additionally, it empowers domain experts to conveniently grow the search space and modularly enhance the system, which brings 48% speedup on end-to-end deep learning workloads.
Deep Neural Networks with Multi-Branch Architectures Are Less Non-Convex
Jun 21, 2018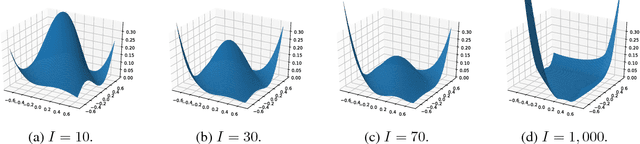
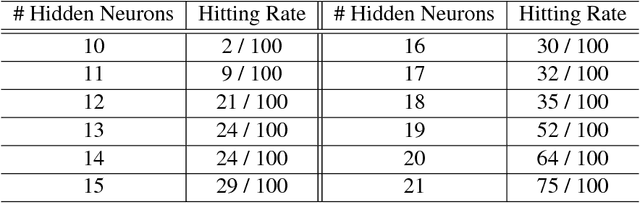
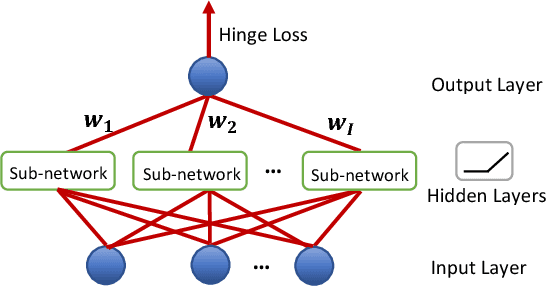
Several recently proposed architectures of neural networks such as ResNeXt, Inception, Xception, SqueezeNet and Wide ResNet are based on the designing idea of having multiple branches and have demonstrated improved performance in many applications. We show that one cause for such success is due to the fact that the multi-branch architecture is less non-convex in terms of duality gap. The duality gap measures the degree of intrinsic non-convexity of an optimization problem: smaller gap in relative value implies lower degree of intrinsic non-convexity. The challenge is to quantitatively measure the duality gap of highly non-convex problems such as deep neural networks. In this work, we provide strong guarantees of this quantity for two classes of network architectures. For the neural networks with arbitrary activation functions, multi-branch architecture and a variant of hinge loss, we show that the duality gap of both population and empirical risks shrinks to zero as the number of branches increases. This result sheds light on better understanding the power of over-parametrization where increasing the network width tends to make the loss surface less non-convex. For the neural networks with linear activation function and $\ell_2$ loss, we show that the duality gap of empirical risk is zero. Our two results work for arbitrary depths and adversarial data, while the analytical techniques might be of independent interest to non-convex optimization more broadly. Experiments on both synthetic and real-world datasets validate our results.
Learning to Ask: Neural Question Generation for Reading Comprehension
Apr 29, 2017

We study automatic question generation for sentences from text passages in reading comprehension. We introduce an attention-based sequence learning model for the task and investigate the effect of encoding sentence- vs. paragraph-level information. In contrast to all previous work, our model does not rely on hand-crafted rules or a sophisticated NLP pipeline; it is instead trainable end-to-end via sequence-to-sequence learning. Automatic evaluation results show that our system significantly outperforms the state-of-the-art rule-based system. In human evaluations, questions generated by our system are also rated as being more natural (i.e., grammaticality, fluency) and as more difficult to answer (in terms of syntactic and lexical divergence from the original text and reasoning needed to answer).
Accelerated Distance Computation with Encoding Tree for High Dimensional Data
Sep 18, 2015
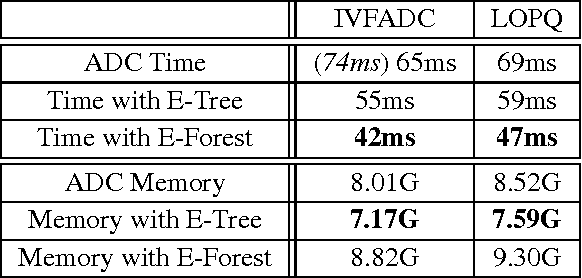
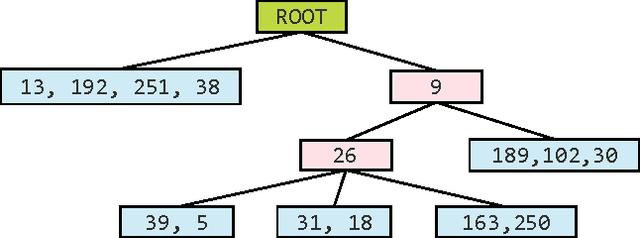
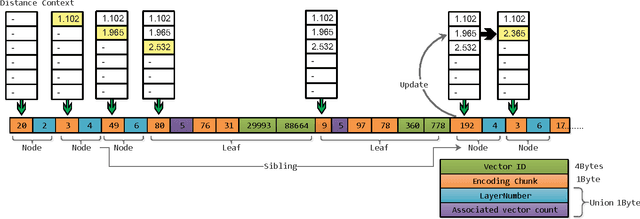
We propose a novel distance to calculate distance between high dimensional vector pairs, utilizing vector quantization generated encodings. Vector quantization based methods are successful in handling large scale high dimensional data. These methods compress vectors into short encodings, and allow efficient distance computation between an uncompressed vector and compressed dataset without decompressing explicitly. However for large datasets, these distance computing methods perform excessive computations. We avoid excessive computations by storing the encodings on an Encoding Tree(E-Tree), interestingly the memory consumption is also lowered. We also propose Encoding Forest(E-Forest) to further lower the computation cost. E-Tree and E-Forest is compatible with various existing quantization-based methods. We show by experiments our methods speed-up distance computing for high dimensional data drastically, and various existing algorithms can benefit from our methods.
Improved Residual Vector Quantization for High-dimensional Approximate Nearest Neighbor Search
Sep 17, 2015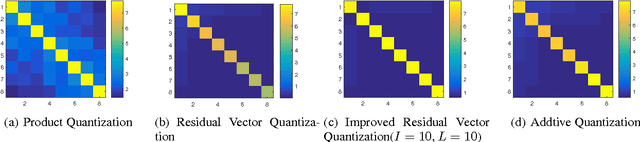
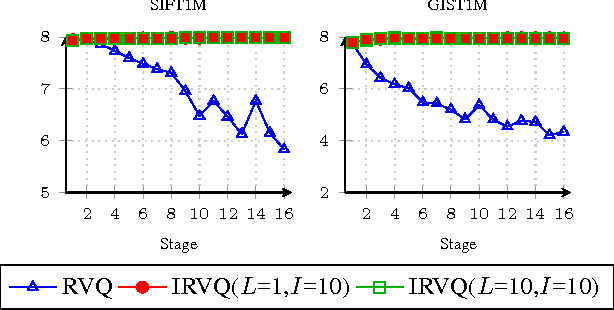
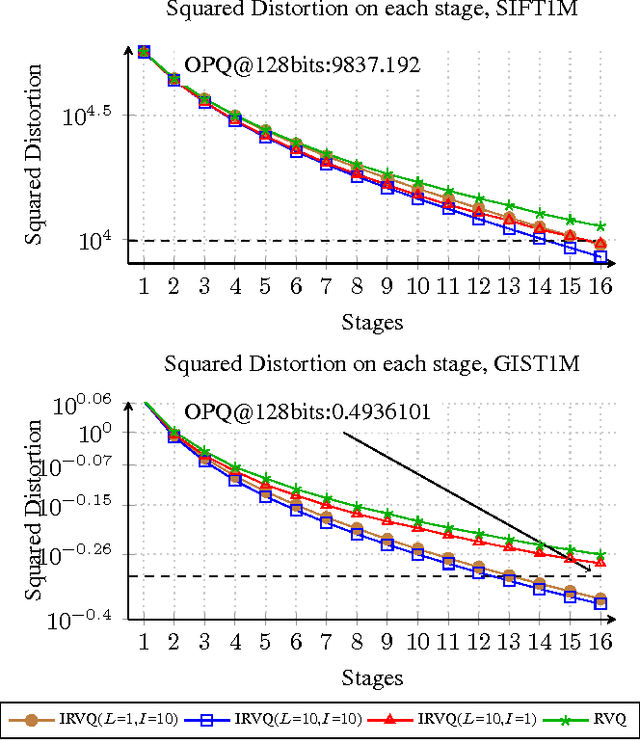
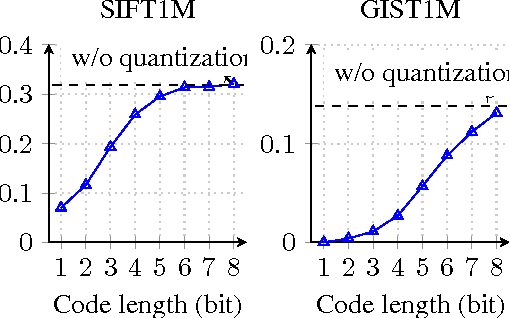
Quantization methods have been introduced to perform large scale approximate nearest search tasks. Residual Vector Quantization (RVQ) is one of the effective quantization methods. RVQ uses a multi-stage codebook learning scheme to lower the quantization error stage by stage. However, there are two major limitations for RVQ when applied to on high-dimensional approximate nearest neighbor search: 1. The performance gain diminishes quickly with added stages. 2. Encoding a vector with RVQ is actually NP-hard. In this paper, we propose an improved residual vector quantization (IRVQ) method, our IRVQ learns codebook with a hybrid method of subspace clustering and warm-started k-means on each stage to prevent performance gain from dropping, and uses a multi-path encoding scheme to encode a vector with lower distortion. Experimental results on the benchmark datasets show that our method gives substantially improves RVQ and delivers better performance compared to the state-of-the-art.