 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Automated Backend-Aware Post-Training Quantization
Mar 27, 2021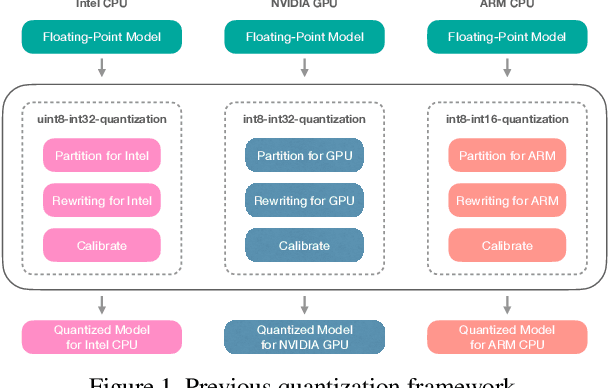
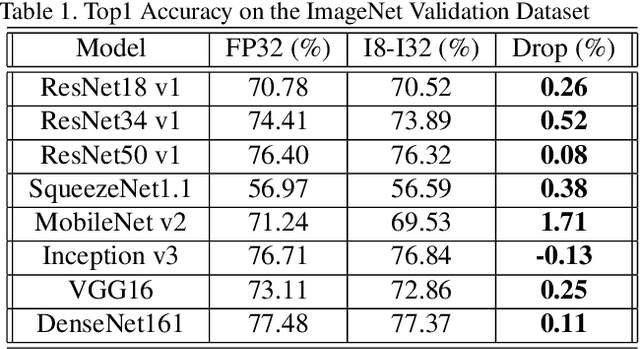
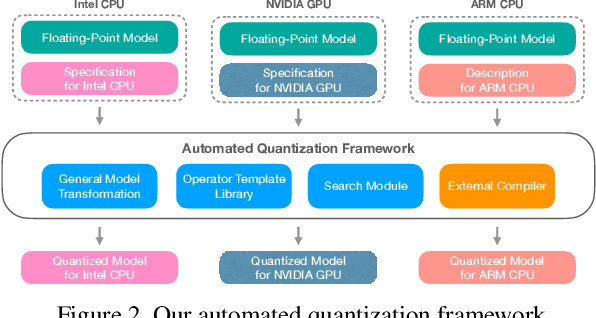
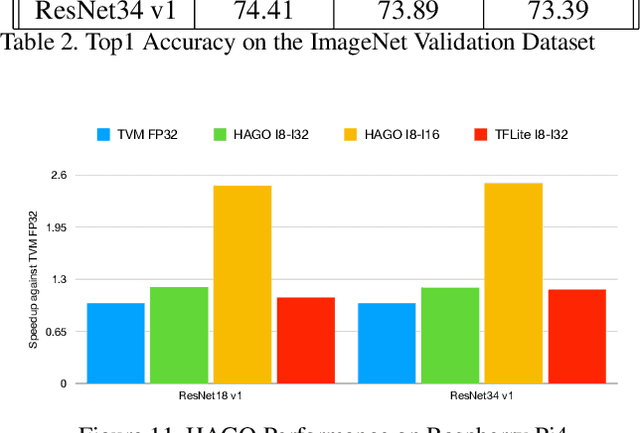
Quantization is a key technique to reduce the resource requirement and improve the performance of neural network deployment. However, different hardware backends such as x86 CPU, NVIDIA GPU, ARM CPU, and accelerators may demand different implementations for quantized networks. This diversity calls for specialized post-training quantization pipelines to built for each hardware target, an engineering effort that is often too large for developers to keep up with. We tackle this problem with an automated post-training quantization framework called HAGO. HAGO provides a set of general quantization graph transformations based on a user-defined hardware specification and implements a search mechanism to find the optimal quantization strategy while satisfying hardware constraints for any model. We observe that HAGO achieves speedups of 2.09x, 1.97x, and 2.48x on Intel Xeon Cascade Lake CPUs, NVIDIA Tesla T4 GPUs, ARM Cortex-A CPUs on Raspberry Pi4 relative to full precision respectively, while maintaining the highest reported post-training quantization accuracy in each case.
SplitSR: An End-to-End Approach to Super-Resolution on Mobile Devices
Jan 20, 2021
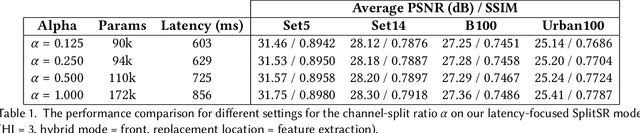
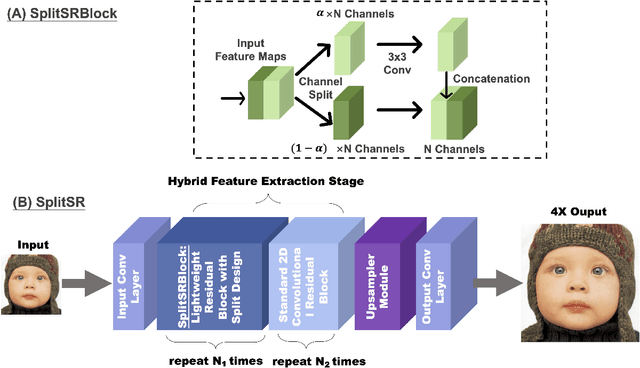

Super-resolution (SR) is a coveted image processing technique for mobile apps ranging from the basic camera apps to mobile health. Existing SR algorithms rely on deep learning models with significant memory requirements, so they have yet to be deployed on mobile devices and instead operate in the cloud to achieve feasible inference time. This shortcoming prevents existing SR methods from being used in applications that require near real-time latency. In this work, we demonstrate state-of-the-art latency and accuracy for on-device super-resolution using a novel hybrid architecture called SplitSR and a novel lightweight residual block called SplitSRBlock. The SplitSRBlock supports channel-splitting, allowing the residual blocks to retain spatial information while reducing the computation in the channel dimension. SplitSR has a hybrid design consisting of standard convolutional blocks and lightweight residual blocks, allowing people to tune SplitSR for their computational budget. We evaluate our system on a low-end ARM CPU, demonstrating both higher accuracy and up to 5 times faster inference than previous approaches. We then deploy our model onto a smartphone in an app called ZoomSR to demonstrate the first-ever instance of on-device, deep learning-based SR. We conducted a user study with 15 participants to have them assess the perceived quality of images that were post-processed by SplitSR. Relative to bilinear interpolation -- the existing standard for on-device SR -- participants showed a statistically significant preference when looking at both images (Z=-9.270, p<0.01) and text (Z=-6.486, p<0.01).
MetaPhys: Unsupervised Few-Shot Adaptation for Non-Contact Physiological Measurement
Oct 05, 2020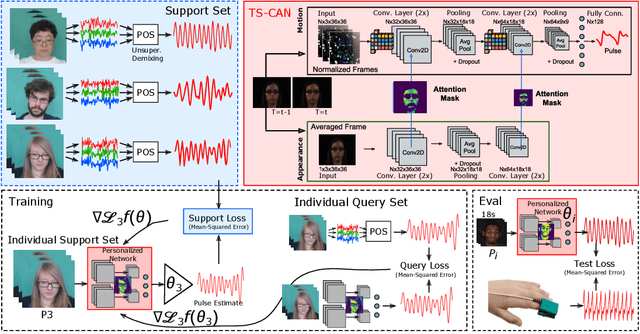
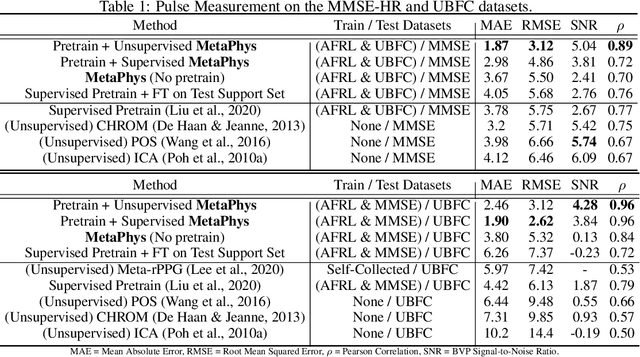
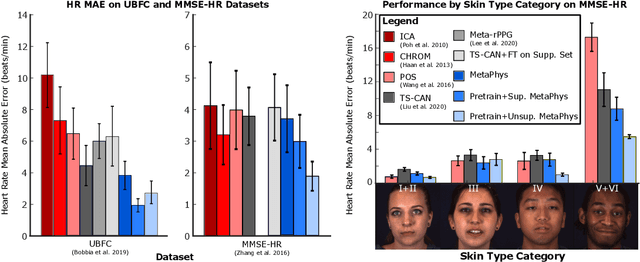

There are large individual differences in physiological processes, making designing personalized health sensing algorithms challenging. Existing machine learning systems struggle to generalize well to unseen subjects or contexts, especially in video-based physiological measurement. Although fine-tuning for a user might address this issue, it is difficult to collect large sets of training data for specific individuals because supervised algorithms require medical-grade sensors for generating the training target. Therefore, learning personalized or customized models from a small number of unlabeled samples is very attractive as it would allow fast calibrations. In this paper, we present a novel unsupervised meta-learning approach called MetaPhys for learning personalized cardiac signals from 18-seconds of unlabeled video data. We evaluate our proposed approach on two benchmark datasets and demonstrate superior performance in cross-dataset evaluation with substantial reductions (42% to 44%) in errors compared with state-of-the-art approaches. Visualization of attention maps and ablation experiments reveal how the model adapts to each subject and why our proposed approach leads to these improvements. We have also demonstrated our proposed method significantly helps reduce the bias in skin type.
Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement
Jun 06, 2020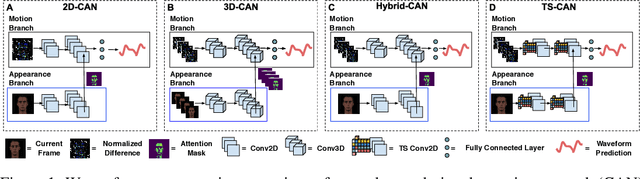
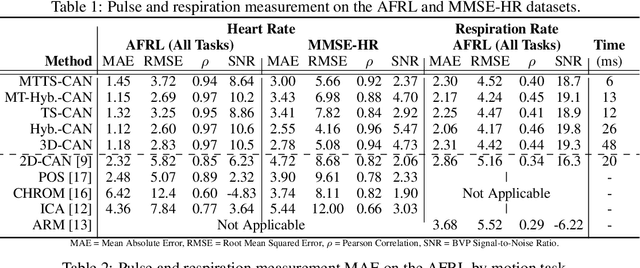
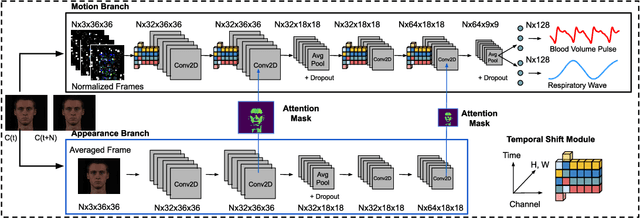
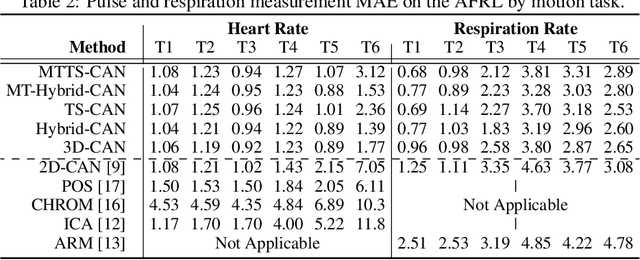
Telehealth and remote health monitoring have become increasingly important during the SARS-CoV-2 pandemic and it is widely expected that this will have a lasting impact on healthcare practices. These tools can help reduce the risk of exposing patients and medical staff to infection, make healthcare services more accessible, and allow providers to see more patients. However, objective measurement of vital signs is challenging without direct contact with a patient. We present a video-based and on-device optical cardiopulmonary vital sign measurement approach. It leverages a novel multi-task temporal shift convolutional attention network (MTTS-CAN) and enables real-time cardiovascular and respiratory measurements on mobile platforms. We evaluate our system on an ARM CPU and achieve state-of-the-art accuracy while running at over 150 frames per second which enables real-time applications. Systematic experimentation on large benchmark datasets reveals that our approach leads to substantial (20%-50%) reductions in error and generalizes well across datasets.
Heterogeneous Bitwidth Binarization in Convolutional Neural Networks
Oct 31, 2018
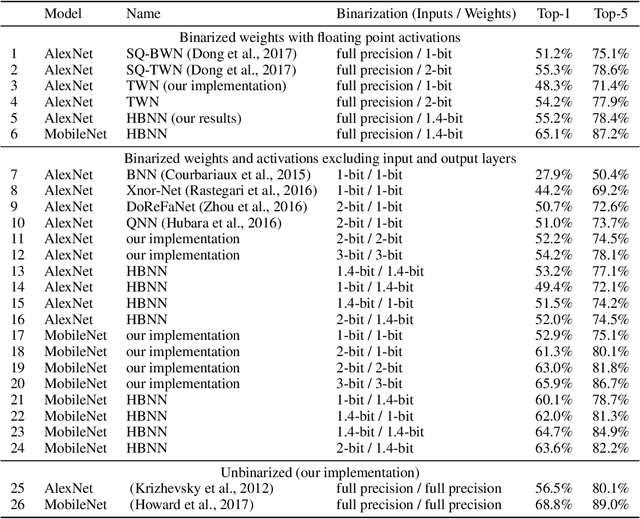
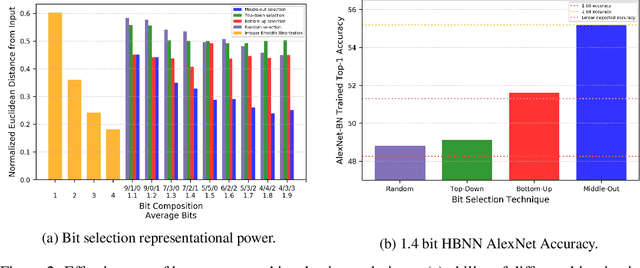
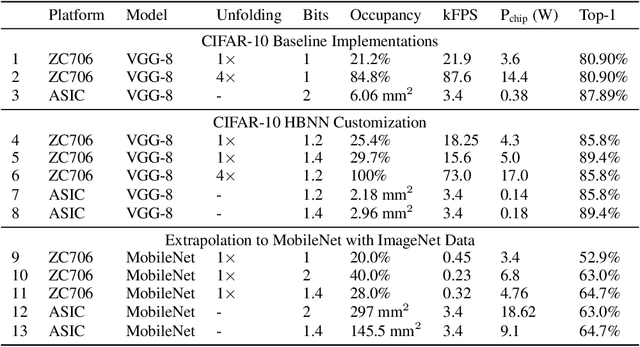
Recent work has shown that fast, compact low-bitwidth neural networks can be surprisingly accurate. These networks use homogeneous binarization: all parameters in each layer or (more commonly) the whole model have the same low bitwidth (e.g., 2 bits). However, modern hardware allows efficient designs where each arithmetic instruction can have a custom bitwidth, motivating heterogeneous binarization, where every parameter in the network may have a different bitwidth. In this paper, we show that it is feasible and useful to select bitwidths at the parameter granularity during training. For instance a heterogeneously quantized version of modern networks such as AlexNet and MobileNet, with the right mix of 1-, 2- and 3-bit parameters that average to just 1.4 bits can equal the accuracy of homogeneous 2-bit versions of these networks. Further, we provide analyses to show that the heterogeneously binarized systems yield FPGA- and ASIC-based implementations that are correspondingly more efficient in both circuit area and energy efficiency than their homogeneous counterparts.