 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Backend-Aware Post-Training Quantization
Paper and Code
Mar 27, 2021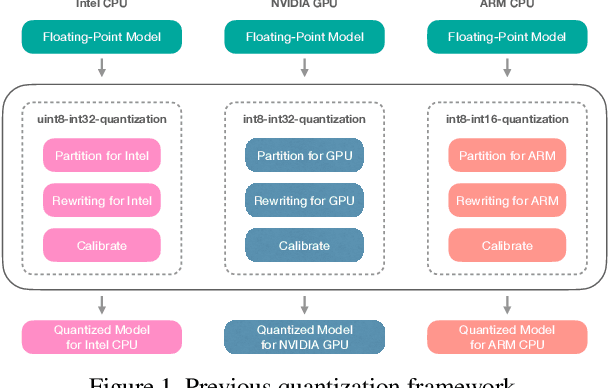
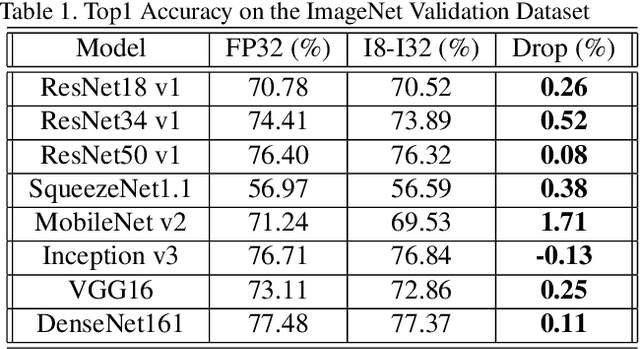
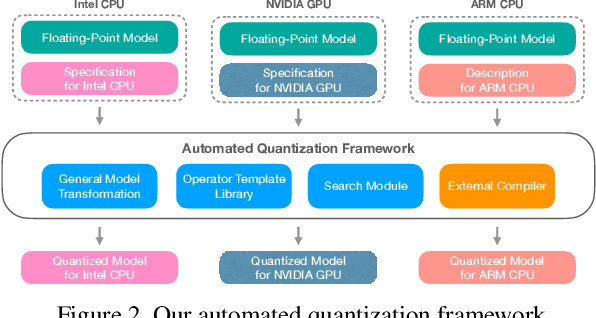
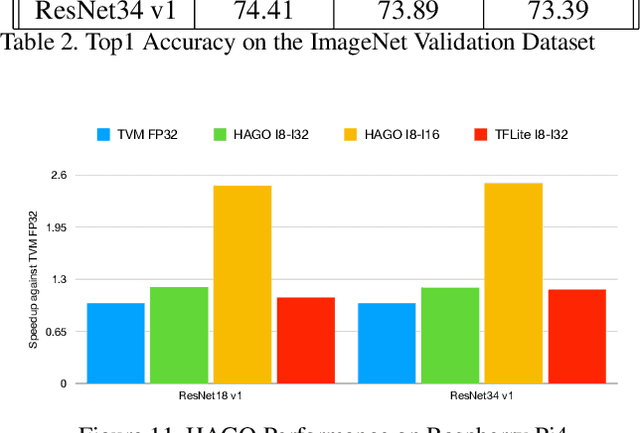
Quantization is a key technique to reduce the resource requirement and improve the performance of neural network deployment. However, different hardware backends such as x86 CPU, NVIDIA GPU, ARM CPU, and accelerators may demand different implementations for quantized networks. This diversity calls for specialized post-training quantization pipelines to built for each hardware target, an engineering effort that is often too large for developers to keep up with. We tackle this problem with an automated post-training quantization framework called HAGO. HAGO provides a set of general quantization graph transformations based on a user-defined hardware specification and implements a search mechanism to find the optimal quantization strategy while satisfying hardware constraints for any model. We observe that HAGO achieves speedups of 2.09x, 1.97x, and 2.48x on Intel Xeon Cascade Lake CPUs, NVIDIA Tesla T4 GPUs, ARM Cortex-A CPUs on Raspberry Pi4 relative to full precision respectively, while maintaining the highest reported post-training quantization accuracy in each case.