 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMIC: Multimodal Inversion for Model Interpretation and Conceptualization
Aug 11, 2025Vision Language Models (VLMs) encode multimodal inputs over large, complex, and difficult-to-interpret architectures, which limit transparency and trust. We propose a Multimodal Inversion for Model Interpretation and Conceptualization (MIMIC) framework to visualize the internal representations of VLMs by synthesizing visual concepts corresponding to internal encodings. MIMIC uses a joint VLM-based inversion and a feature alignment objective to account for VLM's autoregressive processing. It additionally includes a triplet of regularizers for spatial alignment, natural image smoothness, and semantic realism. We quantitatively and qualitatively evaluate MIMIC by inverting visual concepts over a range of varying-length free-form VLM output texts. Reported results include both standard visual quality metrics as well as semantic text-based metrics. To the best of our knowledge, this is the first model inversion approach addressing visual interpretations of VLM concepts.
Automatic Attention Pruning: Improving and Automating Model Pruning using Attentions
Mar 14, 2023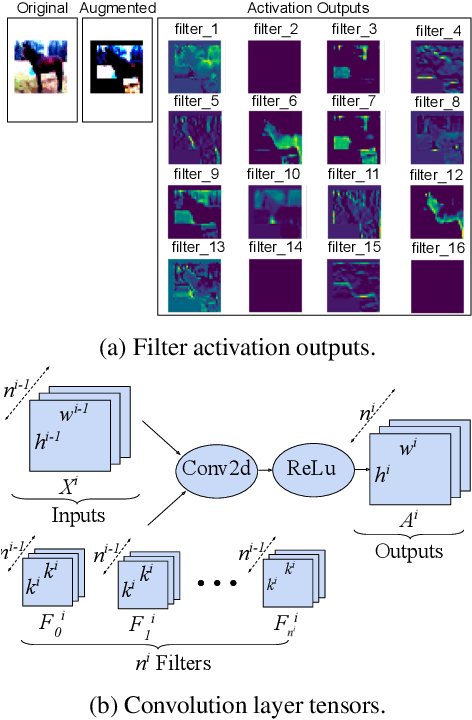


Pruning is a promising approach to compress deep learning models in order to deploy them on resource-constrained edge devices. However, many existing pruning solutions are based on unstructured pruning, which yields models that cannot efficiently run on commodity hardware; and they often require users to manually explore and tune the pruning process, which is time-consuming and often leads to sub-optimal results. To address these limitations, this paper presents Automatic Attention Pruning (AAP), an adaptive, attention-based, structured pruning approach to automatically generate small, accurate, and hardware-efficient models that meet user objectives. First, it proposes iterative structured pruning using activation-based attention maps to effectively identify and prune unimportant filters. Then, it proposes adaptive pruning policies for automatically meeting the pruning objectives of accuracy-critical, memory-constrained, and latency-sensitive tasks. A comprehensive evaluation shows that AAP substantially outperforms the state-of-the-art structured pruning works for a variety of model architectures. Our code is at: https://github.com/kaiqi123/Automatic-Attention-Pruning.git.
Iterative Activation-based Structured Pruning
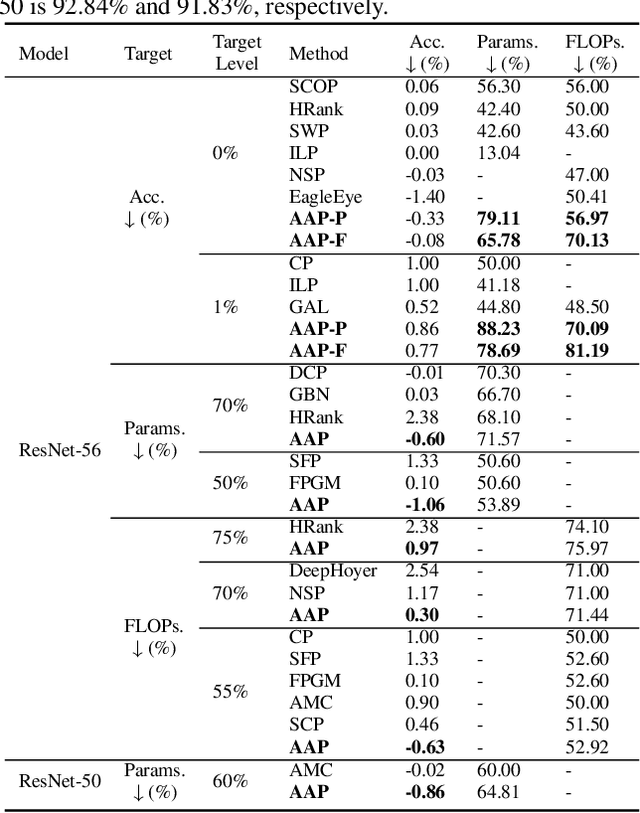
Jan 22, 2022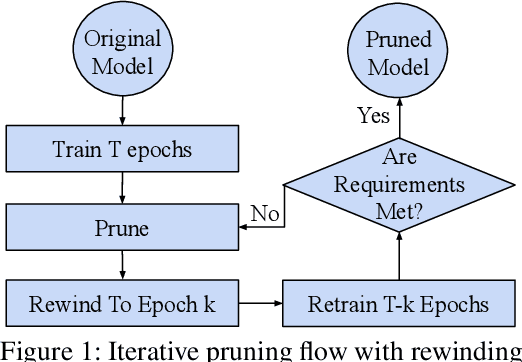
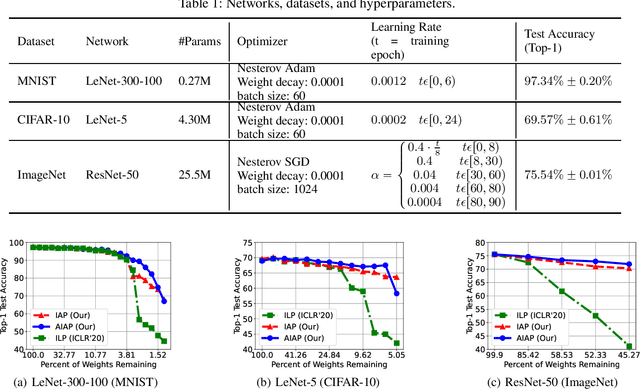


Deploying complex deep learning models on edge devices is challenging because they have substantial compute and memory resource requirements, whereas edge devices' resource budget is limited. To solve this problem, extensive pruning techniques have been proposed for compressing networks. Recent advances based on the Lottery Ticket Hypothesis (LTH) show that iterative model pruning tends to produce smaller and more accurate models. However, LTH research focuses on unstructured pruning, which is hardware-inefficient and difficult to accelerate on hardware platforms. In this paper, we investigate iterative pruning in the context of structured pruning because structurally pruned models map well on commodity hardware. We find that directly applying a structured weight-based pruning technique iteratively, called iterative L1-norm based pruning (ILP), does not produce accurate pruned models. To solve this problem, we propose two activation-based pruning methods, Iterative Activation-based Pruning (IAP) and Adaptive Iterative Activation-based Pruning (AIAP). We observe that, with only 1% accuracy loss, IAP and AIAP achieve 7.75X and 15.88$X compression on LeNet-5, and 1.25X and 1.71X compression on ResNet-50, whereas ILP achieves 4.77X and 1.13X, respectively.
Adaptive Activation-based Structured Pruning
Jan 21, 2022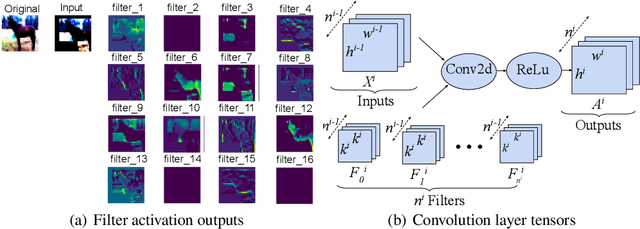
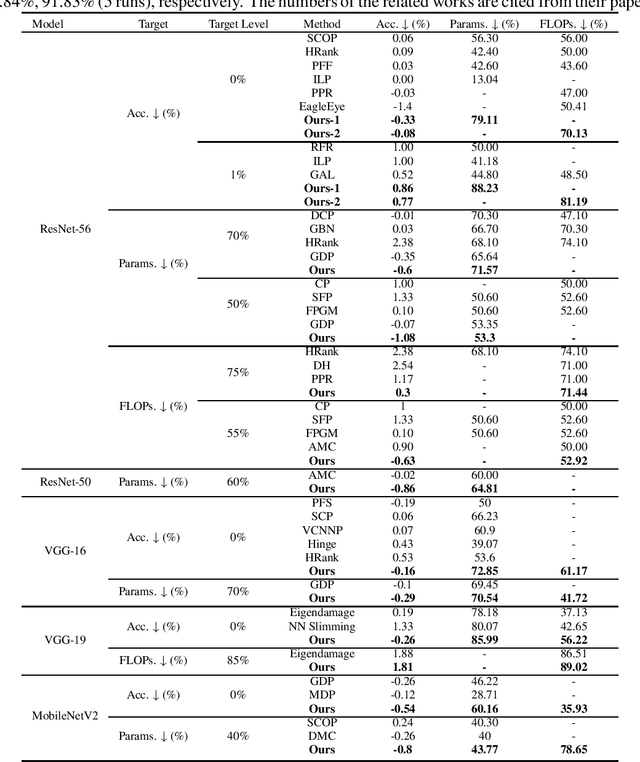
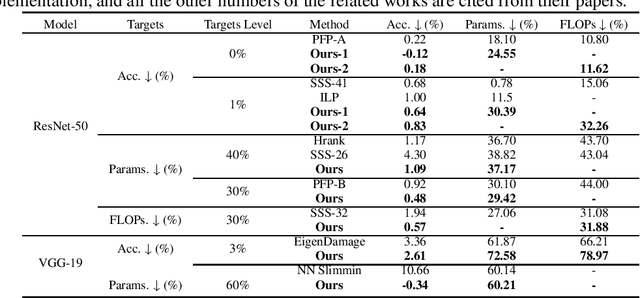
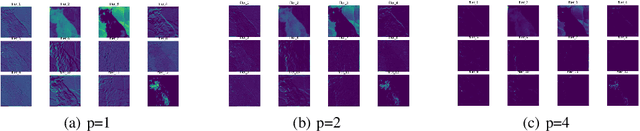
Pruning is a promising approach to compress complex deep learning models in order to deploy them on resource-constrained edge devices. However, many existing pruning solutions are based on unstructured pruning, which yield models that cannot efficiently run on commodity hardware, and require users to manually explore and tune the pruning process, which is time consuming and often leads to sub-optimal results. To address these limitations, this paper presents an adaptive, activation-based, structured pruning approach to automatically and efficiently generate small, accurate, and hardware-efficient models that meet user requirements. First, it proposes iterative structured pruning using activation-based attention feature maps to effectively identify and prune unimportant filters. Then, it proposes adaptive pruning policies for automatically meeting the pruning objectives of accuracy-critical, memory-constrained, and latency-sensitive tasks. A comprehensive evaluation shows that the proposed method can substantially outperform the state-of-the-art structured pruning works on CIFAR-10 and ImageNet datasets. For example, on ResNet-56 with CIFAR-10, without any accuracy drop, our method achieves the largest parameter reduction (79.11%), outperforming the related works by 22.81% to 66.07%, and the largest FLOPs reduction (70.13%), outperforming the related works by 14.13% to 26.53%.
Automated Backend-Aware Post-Training Quantization
Mar 27, 2021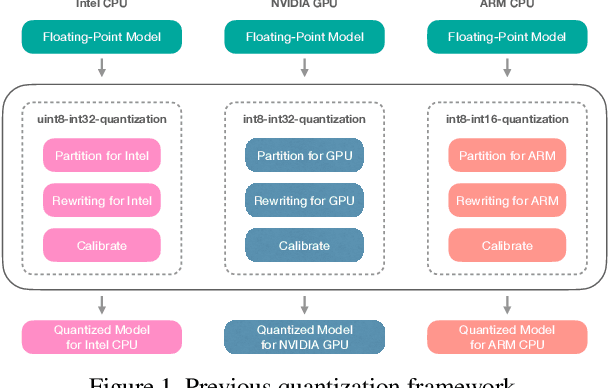
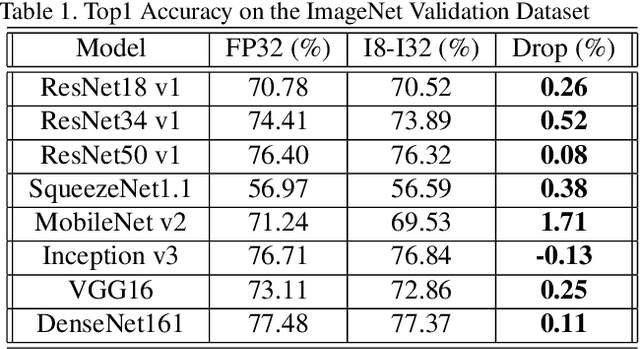
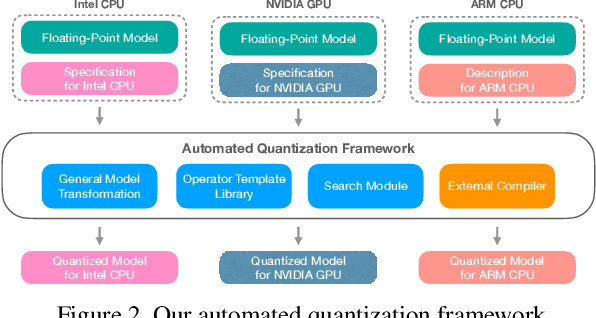
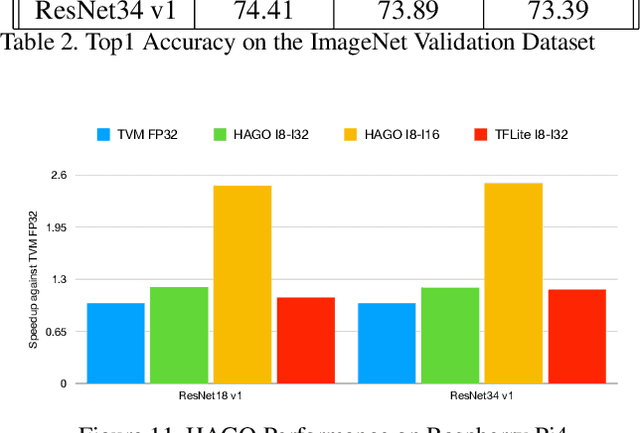
Quantization is a key technique to reduce the resource requirement and improve the performance of neural network deployment. However, different hardware backends such as x86 CPU, NVIDIA GPU, ARM CPU, and accelerators may demand different implementations for quantized networks. This diversity calls for specialized post-training quantization pipelines to built for each hardware target, an engineering effort that is often too large for developers to keep up with. We tackle this problem with an automated post-training quantization framework called HAGO. HAGO provides a set of general quantization graph transformations based on a user-defined hardware specification and implements a search mechanism to find the optimal quantization strategy while satisfying hardware constraints for any model. We observe that HAGO achieves speedups of 2.09x, 1.97x, and 2.48x on Intel Xeon Cascade Lake CPUs, NVIDIA Tesla T4 GPUs, ARM Cortex-A CPUs on Raspberry Pi4 relative to full precision respectively, while maintaining the highest reported post-training quantization accuracy in each case.
UNIT: Unifying Tensorized Instruction Compilation
Jan 21, 2021

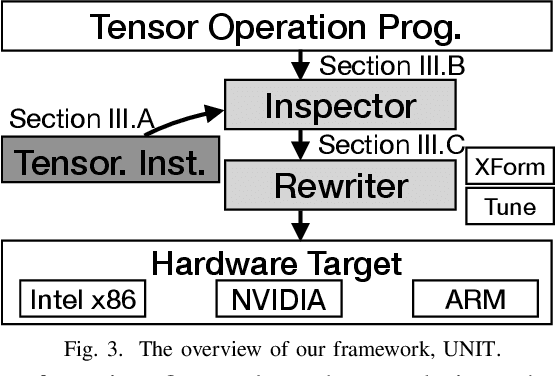

Because of the increasing demand for computation in DNN, researchers develope both hardware and software mechanisms to reduce the compute and memory burden. A widely adopted approach is to use mixed precision data types. However, it is hard to leverage mixed precision without hardware support because of the overhead of data casting. Hardware vendors offer tensorized instructions for mixed-precision tensor operations, like Intel VNNI, Tensor Core, and ARM-DOT. These instructions involve a computing idiom that reduces multiple low precision elements into one high precision element. The lack of compilation techniques for this makes it hard to utilize these instructions: Using vendor-provided libraries for computationally-intensive kernels is inflexible and prevents further optimizations, and manually writing hardware intrinsics is error-prone and difficult for programmers. Some prior works address this problem by creating compilers for each instruction. This requires excessive effort when it comes to many tensorized instructions. In this work, we develop a compiler framework to unify the compilation for these instructions -- a unified semantics abstraction eases the integration of new instructions, and reuses the analysis and transformations. Tensorized instructions from different platforms can be compiled via UNIT with moderate effort for favorable performance. Given a tensorized instruction and a tensor operation, UNIT automatically detects the applicability, transforms the loop organization of the operation,and rewrites the loop body to leverage the tensorized instruction. According to our evaluation, UNIT can target various mainstream hardware platforms. The generated end-to-end inference model achieves 1.3x speedup over Intel oneDNN on an x86 CPU, 1.75x speedup over Nvidia cuDNN on an NvidiaGPU, and 1.13x speedup over a carefully tuned TVM solution for ARM DOT on an ARM CPU.
Efficient Execution of Quantized Deep Learning Models: A Compiler Approach
Jun 18, 2020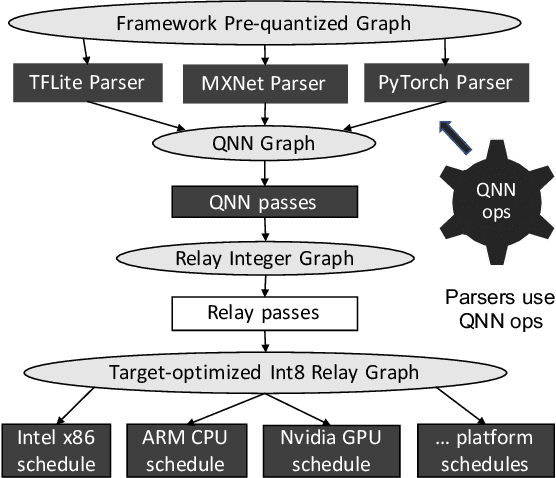
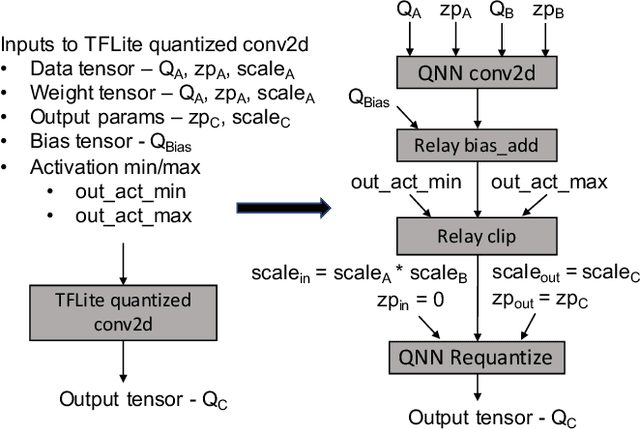
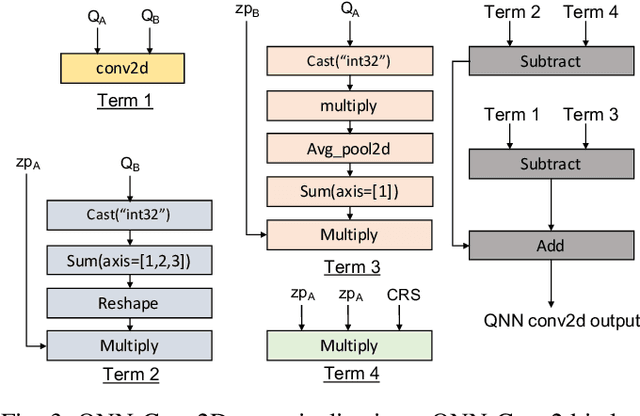
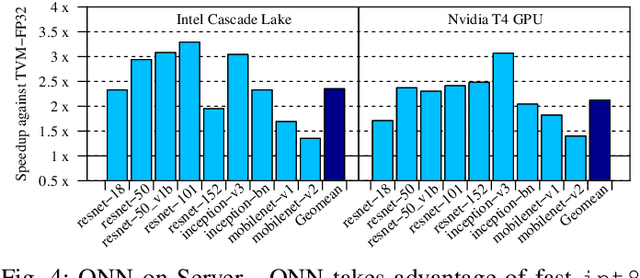
A growing number of applications implement predictive functions using deep learning models, which require heavy use of compute and memory. One popular technique for increasing resource efficiency is 8-bit integer quantization, in which 32-bit floating point numbers (fp32) are represented using shorter 8-bit integer numbers. Although deep learning frameworks such as TensorFlow, TFLite, MXNet, and PyTorch enable developers to quantize models with only a small drop in accuracy, they are not well suited to execute quantized models on a variety of hardware platforms. For example, TFLite is optimized to run inference on ARM CPU edge devices but it does not have efficient support for Intel CPUs and Nvidia GPUs. In this paper, we address the challenges of executing quantized deep learning models on diverse hardware platforms by proposing an augmented compiler approach. A deep learning compiler such as Apache TVM can enable the efficient execution of model from various frameworks on various targets. Many deep learning compilers today, however, are designed primarily for fp32 computation and cannot optimize a pre-quantized INT8 model. To address this issue, we created a new dialect called Quantized Neural Network (QNN) that extends the compiler's internal representation with a quantization context. With this quantization context, the compiler can generate efficient code for pre-quantized models on various hardware platforms. As implemented in Apache TVM, we observe that the QNN-augmented deep learning compiler achieves speedups of 2.35x, 2.15x, 1.35x and 1.40x on Intel Xeon Cascade Lake CPUs, Nvidia Tesla T4 GPUs, ARM Raspberry Pi3 and Pi4 respectively against well optimized fp32 execution, and comparable performance to the state-of-the-art framework-specific solutions.
Optimizing Memory-Access Patterns for Deep Learning Accelerators
Feb 27, 2020Deep learning (DL) workloads are moving towards accelerators for faster processing and lower cost. Modern DL accelerators are good at handling the large-scale multiply-accumulate operations that dominate DL workloads; however, it is challenging to make full use of the compute power of an accelerator since the data must be properly staged in a software-managed scratchpad memory. Failing to do so can result in significant performance loss. This paper proposes a systematic approach which leverages the polyhedral model to analyze all operators of a DL model together to minimize the number of memory accesses. Experiments show that our approach can substantially reduce the impact of memory accesses required by common neural-network models on a homegrown AWS machine-learning inference chip named Inferentia, which is available through Amazon EC2 Inf1 instances.