 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Analytics in Practice: Engineering for Privacy, Scalability and Practicality
Dec 03, 2024



Cross-device Federated Analytics (FA) is a distributed computation paradigm designed to answer analytics queries about and derive insights from data held locally on users' devices. On-device computations combined with other privacy and security measures ensure that only minimal data is transmitted off-device, achieving a high standard of data protection. Despite FA's broad relevance, the applicability of existing FA systems is limited by compromised accuracy; lack of flexibility for data analytics; and an inability to scale effectively. In this paper, we describe our approach to combine privacy, scalability, and practicality to build and deploy a system that overcomes these limitations. Our FA system leverages trusted execution environments (TEEs) and optimizes the use of on-device computing resources to facilitate federated data processing across large fleets of devices, while ensuring robust, defensible, and verifiable privacy safeguards. We focus on federated analytics (statistics and monitoring), in contrast to systems for federated learning (ML workloads), and we flag the key differences.
Efficient Execution of Quantized Deep Learning Models: A Compiler Approach
Jun 18, 2020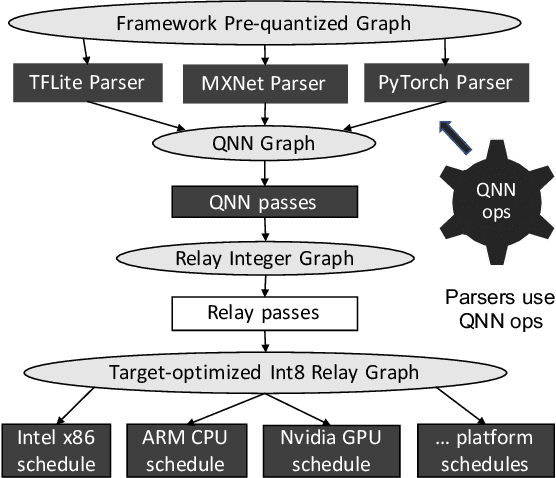
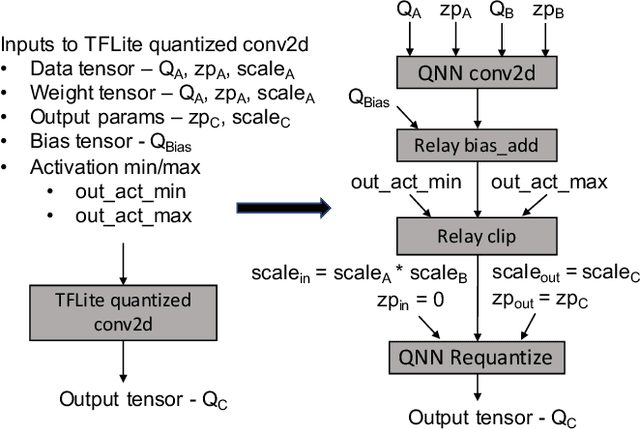
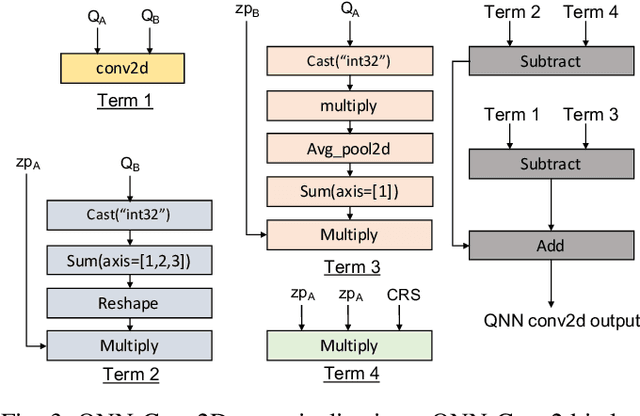
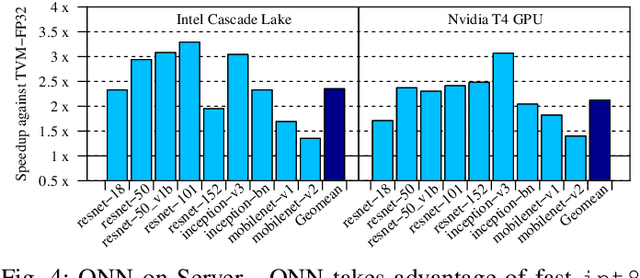
A growing number of applications implement predictive functions using deep learning models, which require heavy use of compute and memory. One popular technique for increasing resource efficiency is 8-bit integer quantization, in which 32-bit floating point numbers (fp32) are represented using shorter 8-bit integer numbers. Although deep learning frameworks such as TensorFlow, TFLite, MXNet, and PyTorch enable developers to quantize models with only a small drop in accuracy, they are not well suited to execute quantized models on a variety of hardware platforms. For example, TFLite is optimized to run inference on ARM CPU edge devices but it does not have efficient support for Intel CPUs and Nvidia GPUs. In this paper, we address the challenges of executing quantized deep learning models on diverse hardware platforms by proposing an augmented compiler approach. A deep learning compiler such as Apache TVM can enable the efficient execution of model from various frameworks on various targets. Many deep learning compilers today, however, are designed primarily for fp32 computation and cannot optimize a pre-quantized INT8 model. To address this issue, we created a new dialect called Quantized Neural Network (QNN) that extends the compiler's internal representation with a quantization context. With this quantization context, the compiler can generate efficient code for pre-quantized models on various hardware platforms. As implemented in Apache TVM, we observe that the QNN-augmented deep learning compiler achieves speedups of 2.35x, 2.15x, 1.35x and 1.40x on Intel Xeon Cascade Lake CPUs, Nvidia Tesla T4 GPUs, ARM Raspberry Pi3 and Pi4 respectively against well optimized fp32 execution, and comparable performance to the state-of-the-art framework-specific solutions.