 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Bring Your Own Codegen to Deep Learning Compiler
May 03, 2021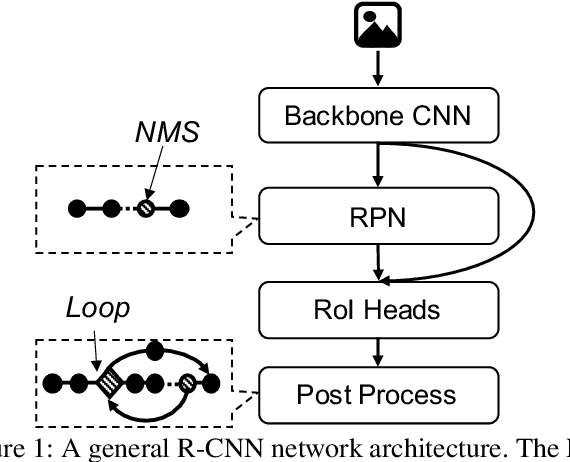
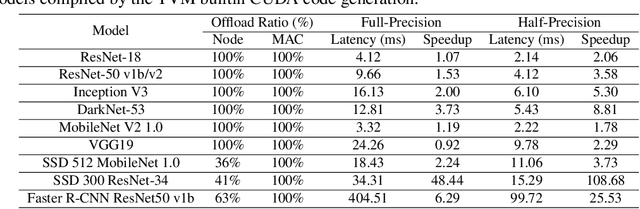

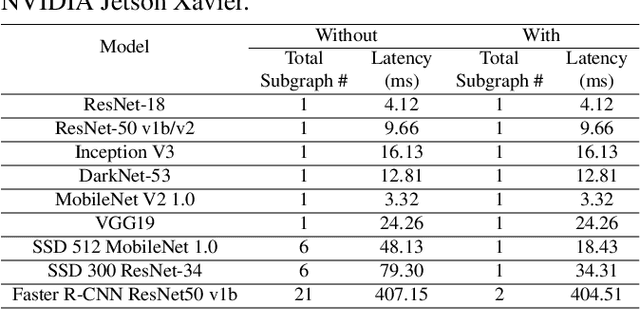
Deep neural networks (DNNs) have been ubiquitously applied in many applications, and accelerators are emerged as an enabler to support the fast and efficient inference tasks of these applications. However, to achieve high model coverage with high performance, each accelerator vendor has to develop a full compiler stack to ingest, optimize, and execute the DNNs. This poses significant challenges in the development and maintenance of the software stack. In addition, the vendors have to contiguously update their hardware and/or software to cope with the rapid evolution of the DNN model architectures and operators. To address these issues, this paper proposes an open source framework that enables users to only concentrate on the development of their proprietary code generation tools by reusing as many as possible components in the existing deep learning compilers. Our framework provides users flexible and easy-to-use interfaces to partition their models into segments that can be executed on "the best" processors to take advantage of the powerful computation capability of accelerators. Our case study shows that our framework has been deployed in multiple commercial vendors' compiler stacks with only a few thousand lines of code.
Efficient Execution of Quantized Deep Learning Models: A Compiler Approach
Jun 18, 2020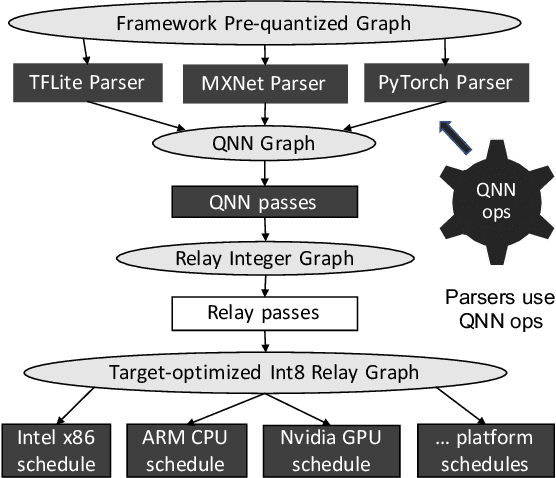
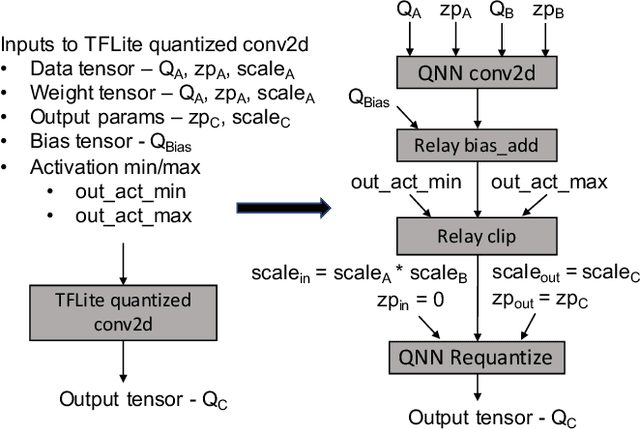
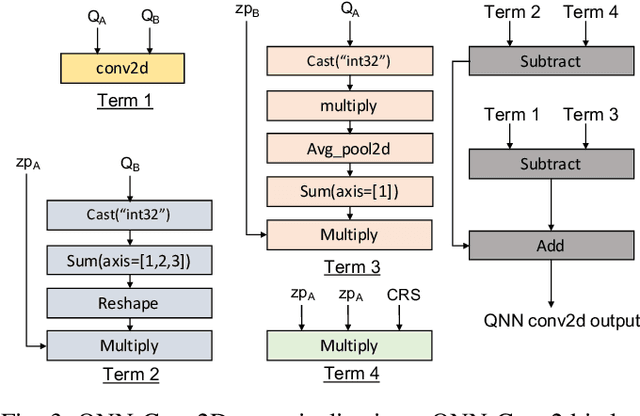
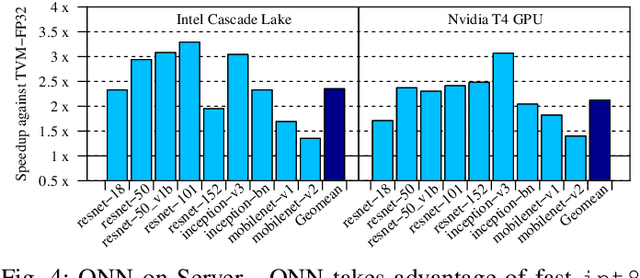
A growing number of applications implement predictive functions using deep learning models, which require heavy use of compute and memory. One popular technique for increasing resource efficiency is 8-bit integer quantization, in which 32-bit floating point numbers (fp32) are represented using shorter 8-bit integer numbers. Although deep learning frameworks such as TensorFlow, TFLite, MXNet, and PyTorch enable developers to quantize models with only a small drop in accuracy, they are not well suited to execute quantized models on a variety of hardware platforms. For example, TFLite is optimized to run inference on ARM CPU edge devices but it does not have efficient support for Intel CPUs and Nvidia GPUs. In this paper, we address the challenges of executing quantized deep learning models on diverse hardware platforms by proposing an augmented compiler approach. A deep learning compiler such as Apache TVM can enable the efficient execution of model from various frameworks on various targets. Many deep learning compilers today, however, are designed primarily for fp32 computation and cannot optimize a pre-quantized INT8 model. To address this issue, we created a new dialect called Quantized Neural Network (QNN) that extends the compiler's internal representation with a quantization context. With this quantization context, the compiler can generate efficient code for pre-quantized models on various hardware platforms. As implemented in Apache TVM, we observe that the QNN-augmented deep learning compiler achieves speedups of 2.35x, 2.15x, 1.35x and 1.40x on Intel Xeon Cascade Lake CPUs, Nvidia Tesla T4 GPUs, ARM Raspberry Pi3 and Pi4 respectively against well optimized fp32 execution, and comparable performance to the state-of-the-art framework-specific solutions.
Nimble: Efficiently Compiling Dynamic Neural Networks for Model Inference
Jun 04, 2020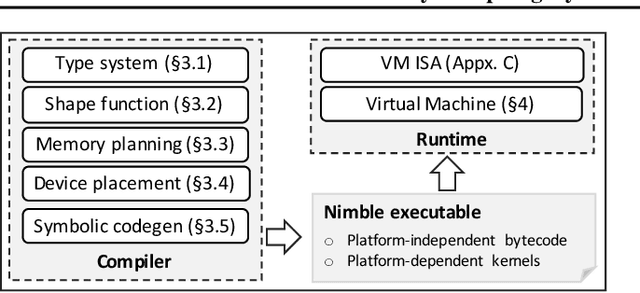
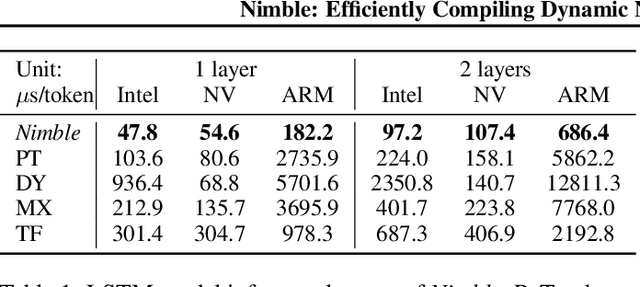
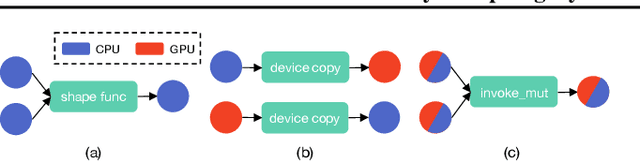

Modern deep neural networks increasingly make use of features such as dynamic control flow, data structures and dynamic tensor shapes. Existing deep learning systems focus on optimizing and executing static neural networks which assume a pre-determined model architecture and input data shapes--assumptions which are violated by dynamic neural networks. Therefore, executing dynamic models with deep learning systems is currently both inflexible and sub-optimal, if not impossible. Optimizing dynamic neural networks is more challenging than static neural networks; optimizations must consider all possible execution paths and tensor shapes. This paper proposes Nimble, a high-performance and flexible system to optimize, compile, and execute dynamic neural networks on multiple platforms. Nimble handles model dynamism by introducing a dynamic type system, a set of dynamism-oriented optimizations, and a light-weight virtual machine runtime. Our evaluation demonstrates that Nimble outperforms state-of-the-art deep learning frameworks and runtime systems for dynamic neural networks by up to 20x on hardware platforms including Intel CPUs, ARM CPUs, and Nvidia GPUs.