 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBring Your Own Codegen to Deep Learning Compiler
Paper and Code
May 03, 2021
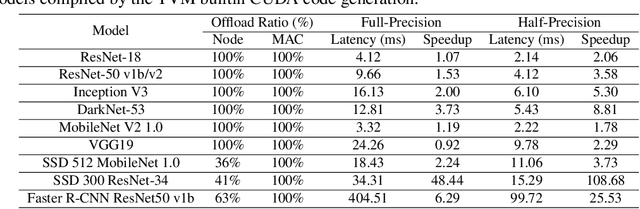

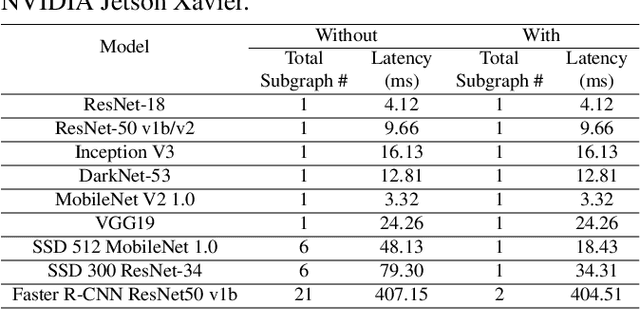
Deep neural networks (DNNs) have been ubiquitously applied in many applications, and accelerators are emerged as an enabler to support the fast and efficient inference tasks of these applications. However, to achieve high model coverage with high performance, each accelerator vendor has to develop a full compiler stack to ingest, optimize, and execute the DNNs. This poses significant challenges in the development and maintenance of the software stack. In addition, the vendors have to contiguously update their hardware and/or software to cope with the rapid evolution of the DNN model architectures and operators. To address these issues, this paper proposes an open source framework that enables users to only concentrate on the development of their proprietary code generation tools by reusing as many as possible components in the existing deep learning compilers. Our framework provides users flexible and easy-to-use interfaces to partition their models into segments that can be executed on "the best" processors to take advantage of the powerful computation capability of accelerators. Our case study shows that our framework has been deployed in multiple commercial vendors' compiler stacks with only a few thousand lines of code.