 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Activation-based Structured Pruning
Paper and Code
Jan 22, 2022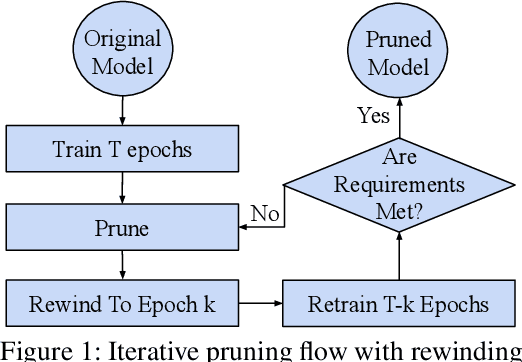
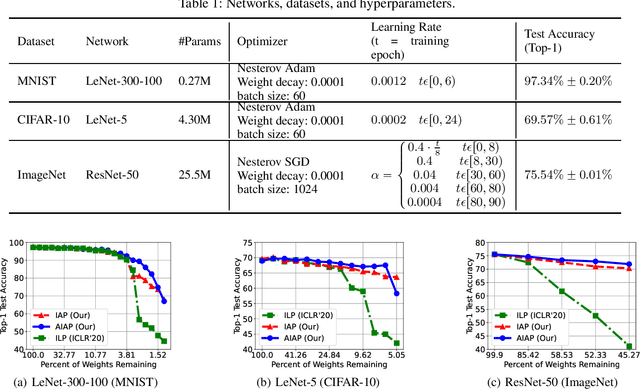


Deploying complex deep learning models on edge devices is challenging because they have substantial compute and memory resource requirements, whereas edge devices' resource budget is limited. To solve this problem, extensive pruning techniques have been proposed for compressing networks. Recent advances based on the Lottery Ticket Hypothesis (LTH) show that iterative model pruning tends to produce smaller and more accurate models. However, LTH research focuses on unstructured pruning, which is hardware-inefficient and difficult to accelerate on hardware platforms. In this paper, we investigate iterative pruning in the context of structured pruning because structurally pruned models map well on commodity hardware. We find that directly applying a structured weight-based pruning technique iteratively, called iterative L1-norm based pruning (ILP), does not produce accurate pruned models. To solve this problem, we propose two activation-based pruning methods, Iterative Activation-based Pruning (IAP) and Adaptive Iterative Activation-based Pruning (AIAP). We observe that, with only 1% accuracy loss, IAP and AIAP achieve 7.75X and 15.88$X compression on LeNet-5, and 1.25X and 1.71X compression on ResNet-50, whereas ILP achieves 4.77X and 1.13X, respectively.