 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIT: Unifying Tensorized Instruction Compilation
Paper and Code
Jan 21, 2021

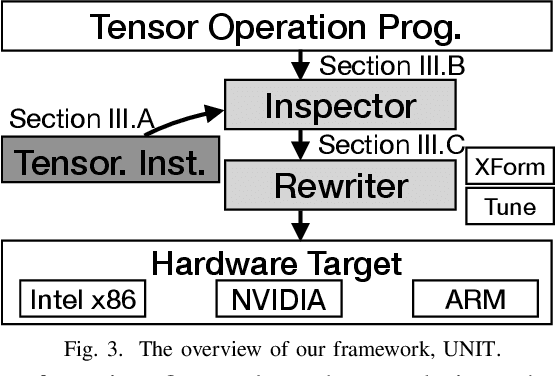

Because of the increasing demand for computation in DNN, researchers develope both hardware and software mechanisms to reduce the compute and memory burden. A widely adopted approach is to use mixed precision data types. However, it is hard to leverage mixed precision without hardware support because of the overhead of data casting. Hardware vendors offer tensorized instructions for mixed-precision tensor operations, like Intel VNNI, Tensor Core, and ARM-DOT. These instructions involve a computing idiom that reduces multiple low precision elements into one high precision element. The lack of compilation techniques for this makes it hard to utilize these instructions: Using vendor-provided libraries for computationally-intensive kernels is inflexible and prevents further optimizations, and manually writing hardware intrinsics is error-prone and difficult for programmers. Some prior works address this problem by creating compilers for each instruction. This requires excessive effort when it comes to many tensorized instructions. In this work, we develop a compiler framework to unify the compilation for these instructions -- a unified semantics abstraction eases the integration of new instructions, and reuses the analysis and transformations. Tensorized instructions from different platforms can be compiled via UNIT with moderate effort for favorable performance. Given a tensorized instruction and a tensor operation, UNIT automatically detects the applicability, transforms the loop organization of the operation,and rewrites the loop body to leverage the tensorized instruction. According to our evaluation, UNIT can target various mainstream hardware platforms. The generated end-to-end inference model achieves 1.3x speedup over Intel oneDNN on an x86 CPU, 1.75x speedup over Nvidia cuDNN on an NvidiaGPU, and 1.13x speedup over a carefully tuned TVM solution for ARM DOT on an ARM CPU.