 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaggleDBQA: Realistic Evaluation of Text-to-SQL Parsers
Paper and Code
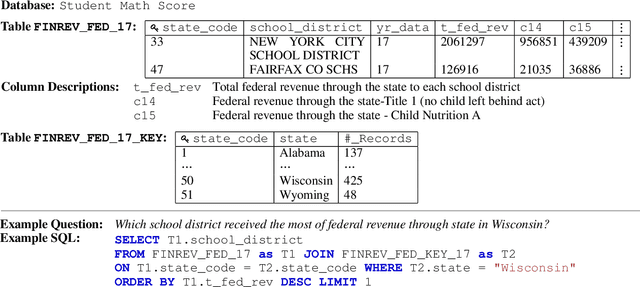
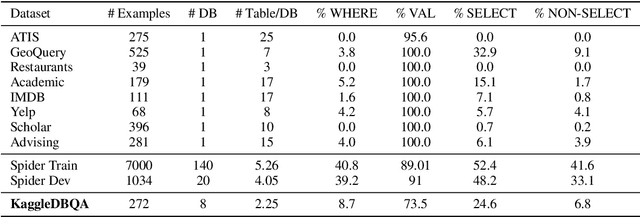
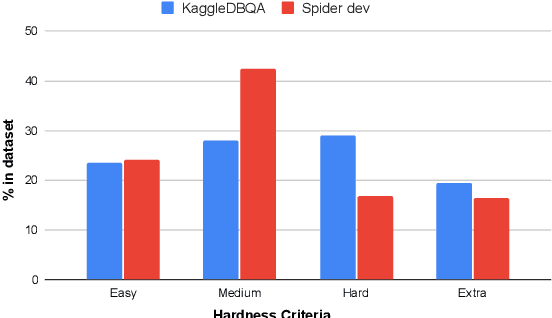

The goal of database question answering is to enable natural language querying of real-life relational databases in diverse application domains. Recently, large-scale datasets such as Spider and WikiSQL facilitated novel modeling techniques for text-to-SQL parsing, improving zero-shot generalization to unseen databases. In this work, we examine the challenges that still prevent these techniques from practical deployment. First, we present KaggleDBQA, a new cross-domain evaluation dataset of real Web databases, with domain-specific data types, original formatting, and unrestricted questions. Second, we re-examine the choice of evaluation tasks for text-to-SQL parsers as applied in real-life settings. Finally, we augment our in-domain evaluation task with database documentation, a naturally occurring source of implicit domain knowledge. We show that KaggleDBQA presents a challenge to state-of-the-art zero-shot parsers but a more realistic evaluation setting and creative use of associated database documentation boosts their accuracy by over 13.2%, doubling their performance.