 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrb: A Fast, Scalable Neural Network Potential
Oct 29, 2024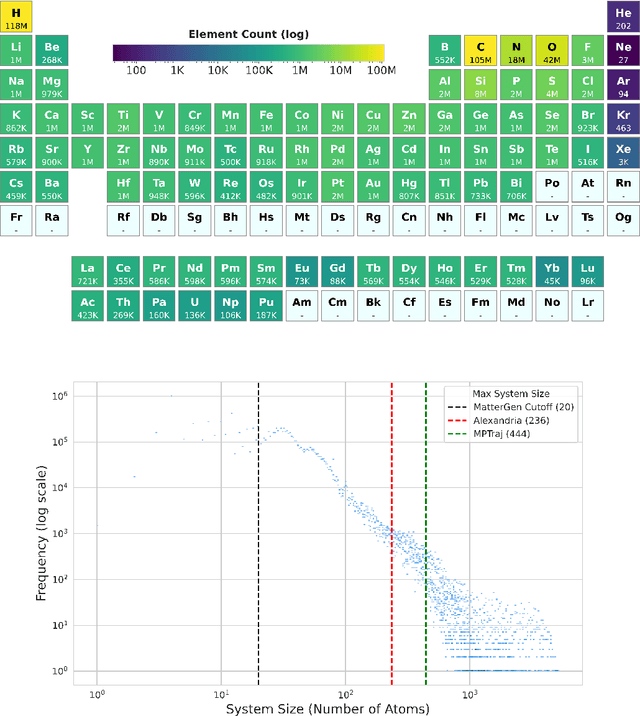
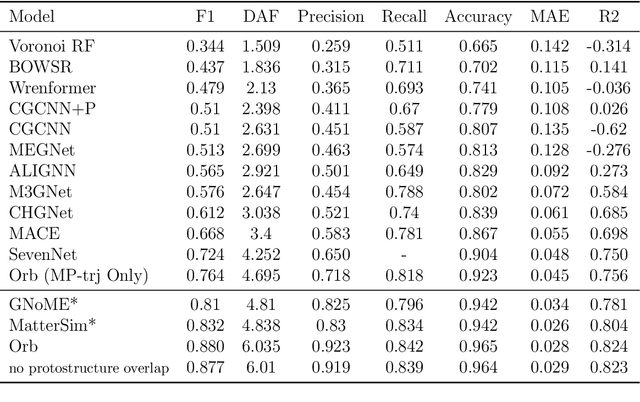
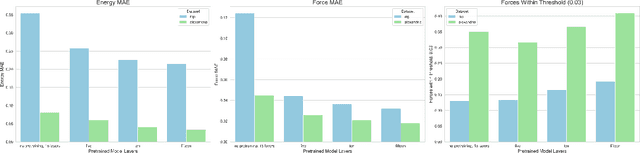
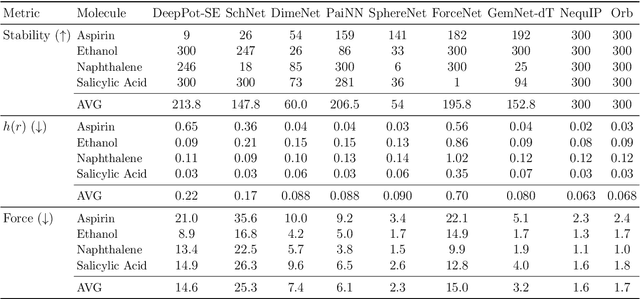
We introduce Orb, a family of universal interatomic potentials for atomistic modelling of materials. Orb models are 3-6 times faster than existing universal potentials, stable under simulation for a range of out of distribution materials and, upon release, represented a 31% reduction in error over other methods on the Matbench Discovery benchmark. We explore several aspects of foundation model development for materials, with a focus on diffusion pretraining. We evaluate Orb as a model for geometry optimization, Monte Carlo and molecular dynamics simulations.
PAWLS: PDF Annotation With Labels and Structure
Jan 25, 2021


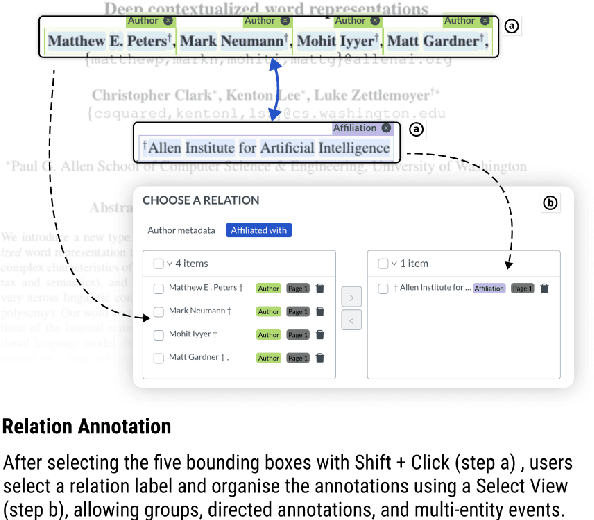
Adobe's Portable Document Format (PDF) is a popular way of distributing view-only documents with a rich visual markup. This presents a challenge to NLP practitioners who wish to use the information contained within PDF documents for training models or data analysis, because annotating these documents is difficult. In this paper, we present PDF Annotation with Labels and Structure (PAWLS), a new annotation tool designed specifically for the PDF document format. PAWLS is particularly suited for mixed-mode annotation and scenarios in which annotators require extended context to annotate accurately. PAWLS supports span-based textual annotation, N-ary relations and freeform, non-textual bounding boxes, all of which can be exported in convenient formats for training multi-modal machine learning models. A read-only PAWLS server is available at https://pawls.apps.allenai.org/ and the source code is available at https://github.com/allenai/pawls.
PySBD: Pragmatic Sentence Boundary Disambiguation
Oct 19, 2020
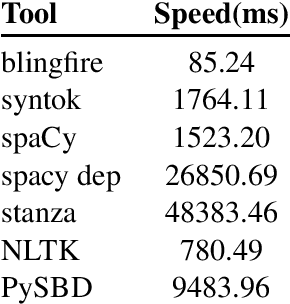
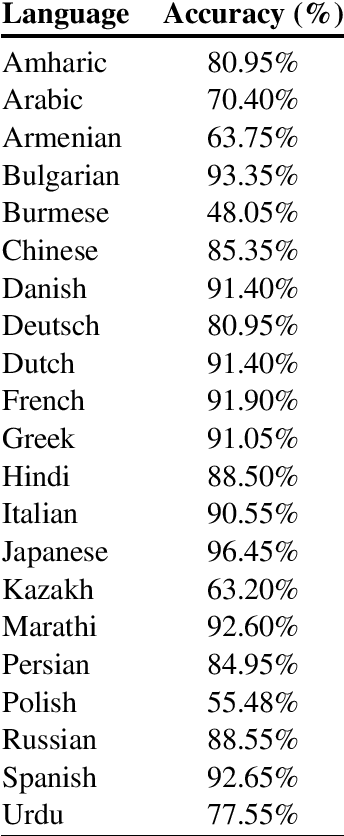
In this paper, we present a rule-based sentence boundary disambiguation Python package that works out-of-the-box for 22 languages. We aim to provide a realistic segmenter which can provide logical sentences even when the format and domain of the input text is unknown. In our work, we adapt the Golden Rules Set (a language-specific set of sentence boundary exemplars) originally implemented as a ruby gem - pragmatic_segmenter - which we ported to Python with additional improvements and functionality. PySBD passes 97.92% of the Golden Rule Set exemplars for English, an improvement of 25% over the next best open-source Python tool.
GORC: A large contextual citation graph of academic papers
Nov 07, 2019
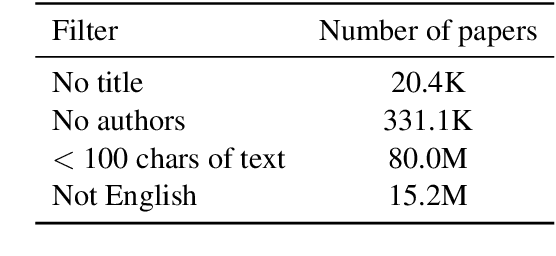
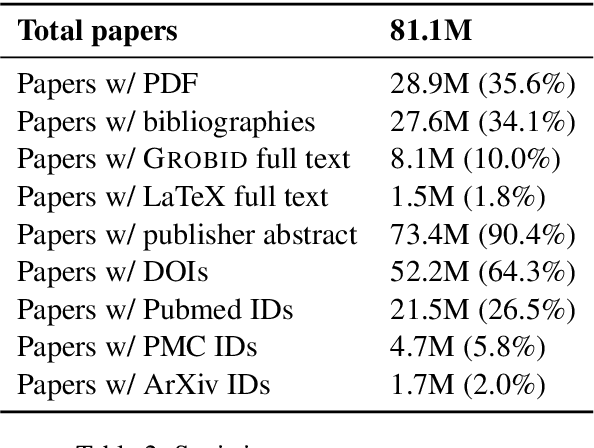

We introduce the Semantic Scholar Graph of References in Context (GORC), a large contextual citation graph of 81.1M academic publications, including parsed full text for 8.1M open access papers, across broad domains of science. Each paper is represented with rich paper metadata (title, authors, abstract, etc.), and where available: cleaned full text, section headers, figure and table captions, and parsed bibliography entries. In-line citation mentions in full text are linked to their corresponding bibliography entries, which are in turn linked to in-corpus cited papers, forming the edges of a contextual citation graph. To our knowledge, this is the largest publicly available contextual citation graph; the full text alone is the largest parsed academic text corpus publicly available. We demonstrate the ability to identify similar papers using these citation contexts and propose several applications for language modeling and citation-related tasks.
Knowledge Enhanced Contextual Word Representations
Sep 09, 2019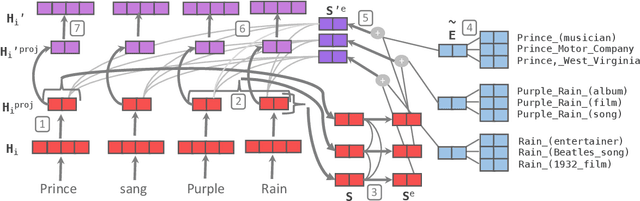
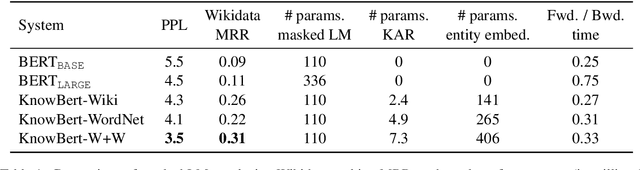


Contextual word representations, typically trained on unstructured, unlabeled text, do not contain any explicit grounding to real world entities and are often unable to remember facts about those entities. We propose a general method to embed multiple knowledge bases (KBs) into large scale models, and thereby enhance their representations with structured, human-curated knowledge. For each KB, we first use an integrated entity linker to retrieve relevant entity embeddings, then update contextual word representations via a form of word-to-entity attention. In contrast to previous approaches, the entity linkers and self-supervised language modeling objective are jointly trained end-to-end in a multitask setting that combines a small amount of entity linking supervision with a large amount of raw text. After integrating WordNet and a subset of Wikipedia into BERT, the knowledge enhanced BERT (KnowBert) demonstrates improved perplexity, ability to recall facts as measured in a probing task and downstream performance on relationship extraction, entity typing, and word sense disambiguation. KnowBert's runtime is comparable to BERT's and it scales to large KBs.
Grammar-based Neural Text-to-SQL Generation
May 30, 2019



The sequence-to-sequence paradigm employed by neural text-to-SQL models typically performs token-level decoding and does not consider generating SQL hierarchically from a grammar. Grammar-based decoding has shown significant improvements for other semantic parsing tasks, but SQL and other general programming languages have complexities not present in logical formalisms that make writing hierarchical grammars difficult. We introduce techniques to handle these complexities, showing how to construct a schema-dependent grammar with minimal over-generation. We analyze these techniques on ATIS and Spider, two challenging text-to-SQL datasets, demonstrating that they yield 14--18\% relative reductions in error.
ScispaCy: Fast and Robust Models for Biomedical Natural Language Processing
Feb 21, 2019
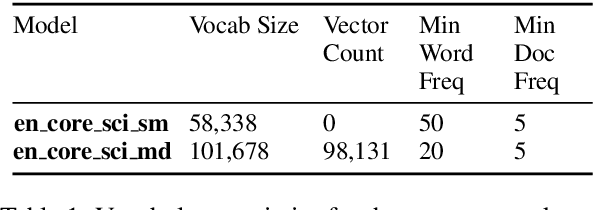


Despite recent advances in natural language processing, many statistical models for processing text perform extremely poorly under domain shift. Processing biomedical and clinical text is a critically important application area of natural language processing, for which there are few robust, practical, publicly available models. This paper describes scispaCy, a new tool for practical biomedical/scientific text processing, which heavily leverages the spaCy library. We detail the performance of two packages of models released in scispaCy and demonstrate their robustness on several tasks and datasets. Models and code are available at https://allenai.github.io/scispacy/
Dissecting Contextual Word Embeddings: Architecture and Representation
Sep 27, 2018
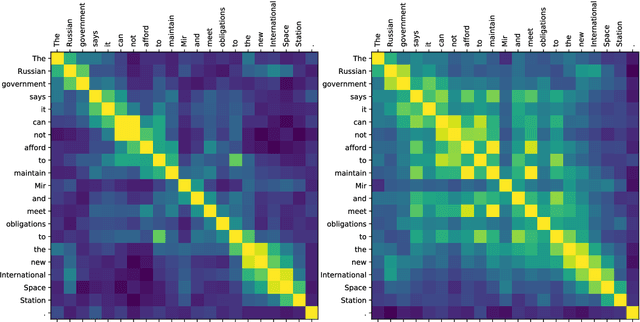
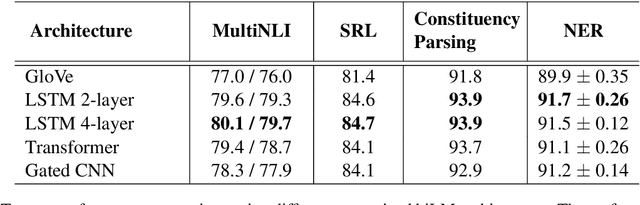

Contextual word representations derived from pre-trained bidirectional language models (biLMs) have recently been shown to provide significant improvements to the state of the art for a wide range of NLP tasks. However, many questions remain as to how and why these models are so effective. In this paper, we present a detailed empirical study of how the choice of neural architecture (e.g. LSTM, CNN, or self attention) influences both end task accuracy and qualitative properties of the representations that are learned. We show there is a tradeoff between speed and accuracy, but all architectures learn high quality contextual representations that outperform word embeddings for four challenging NLP tasks. Additionally, all architectures learn representations that vary with network depth, from exclusively morphological based at the word embedding layer through local syntax based in the lower contextual layers to longer range semantics such coreference at the upper layers. Together, these results suggest that unsupervised biLMs, independent of architecture, are learning much more about the structure of language than previously appreciated.
Ontology Alignment in the Biomedical Domain Using Entity Definitions and Context
Jun 20, 2018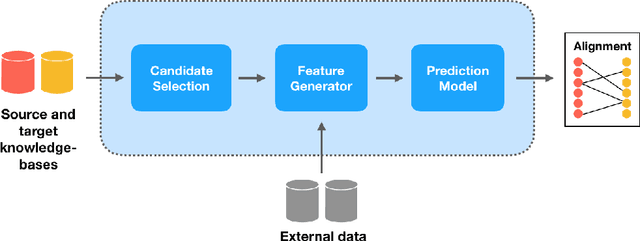
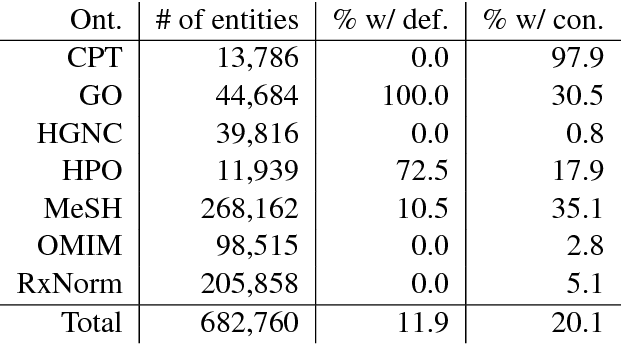
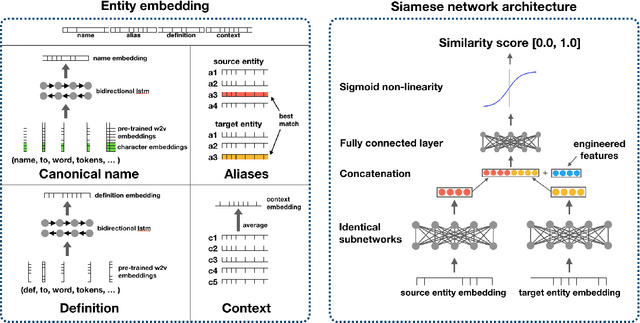

Ontology alignment is the task of identifying semantically equivalent entities from two given ontologies. Different ontologies have different representations of the same entity, resulting in a need to de-duplicate entities when merging ontologies. We propose a method for enriching entities in an ontology with external definition and context information, and use this additional information for ontology alignment. We develop a neural architecture capable of encoding the additional information when available, and show that the addition of external data results in an F1-score of 0.69 on the Ontology Alignment Evaluation Initiative (OAEI) largebio SNOMED-NCI subtask, comparable with the entity-level matchers in a SOTA system.
AllenNLP: A Deep Semantic Natural Language Processing Platform
May 31, 2018This paper describes AllenNLP, a platform for research on deep learning methods in natural language understanding. AllenNLP is designed to support researchers who want to build novel language understanding models quickly and easily. It is built on top of PyTorch, allowing for dynamic computation graphs, and provides (1) a flexible data API that handles intelligent batching and padding, (2) high-level abstractions for common operations in working with text, and (3) a modular and extensible experiment framework that makes doing good science easy. It also includes reference implementations of high quality approaches for both core semantic problems (e.g. semantic role labeling (Palmer et al., 2005)) and language understanding applications (e.g. machine comprehension (Rajpurkar et al., 2016)). AllenNLP is an ongoing open-source effort maintained by engineers and researchers at the Allen Institute for Artificial Intelligence.