 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Predictable Scale: Part I -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining
Mar 06, 2025The impressive capabilities of Large Language Models (LLMs) across diverse tasks are now well-established, yet their effective deployment necessitates careful hyperparameter optimization. Through extensive empirical studies involving grid searches across diverse configurations, we discover universal scaling laws governing these hyperparameters: optimal learning rate follows a power-law relationship with both model parameters and data sizes, while optimal batch size scales primarily with data sizes. Our analysis reveals a convex optimization landscape for hyperparameters under fixed models and data size conditions. This convexity implies an optimal hyperparameter plateau. We contribute a universal, plug-and-play optimal hyperparameter tool for the community. Its estimated values on the test set are merely 0.07\% away from the globally optimal LLM performance found via an exhaustive search. These laws demonstrate remarkable robustness across variations in model sparsity, training data distribution, and model shape. To our best known, this is the first work that unifies different model shapes and structures, such as Mixture-of-Experts models and dense transformers, as well as establishes optimal hyperparameter scaling laws across diverse data distributions. This exhaustive optimization process demands substantial computational resources, utilizing nearly one million NVIDIA H800 GPU hours to train 3,700 LLMs of varying sizes and hyperparameters from scratch and consuming approximately 100 trillion tokens in total. To facilitate reproducibility and further research, we will progressively release all loss measurements and model checkpoints through our designated repository https://step-law.github.io/
Energy-Based Preference Model Offers Better Offline Alignment than the Bradley-Terry Preference Model
Dec 18, 2024



Since the debut of DPO, it has been shown that aligning a target LLM with human preferences via the KL-constrained RLHF loss is mathematically equivalent to a special kind of reward modeling task. Concretely, the task requires: 1) using the target LLM to parameterize the reward model, and 2) tuning the reward model so that it has a 1:1 linear relationship with the true reward. However, we identify a significant issue: the DPO loss might have multiple minimizers, of which only one satisfies the required linearity condition. The problem arises from a well-known issue of the underlying Bradley-Terry preference model: it does not always have a unique maximum likelihood estimator (MLE). Consequently,the minimizer of the RLHF loss might be unattainable because it is merely one among many minimizers of the DPO loss. As a better alternative, we propose an energy-based model (EBM) that always has a unique MLE, inherently satisfying the linearity requirement. To approximate the MLE in practice, we propose a contrastive loss named Energy Preference Alignment (EPA), wherein each positive sample is contrasted against one or more strong negatives as well as many free weak negatives. Theoretical properties of our EBM enable the approximation error of EPA to almost surely vanish when a sufficient number of negatives are used. Empirically, we demonstrate that EPA consistently delivers better performance on open benchmarks compared to DPO, thereby showing the superiority of our EBM.
Uncertainty Sentence Sampling by Virtual Adversarial Perturbation
Oct 27, 2022
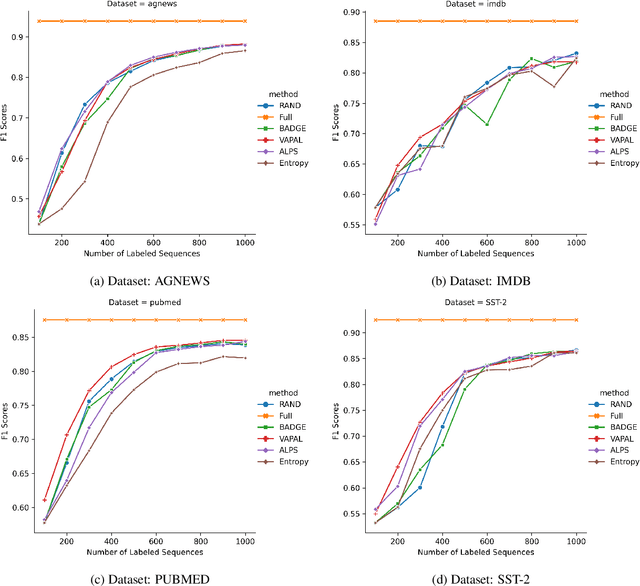
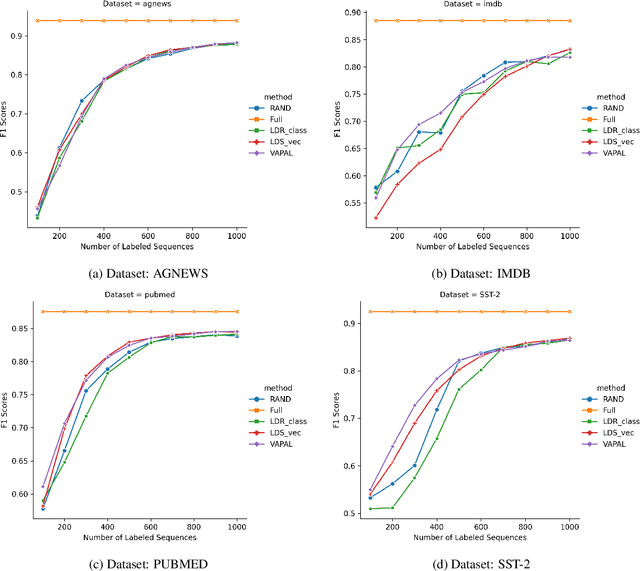
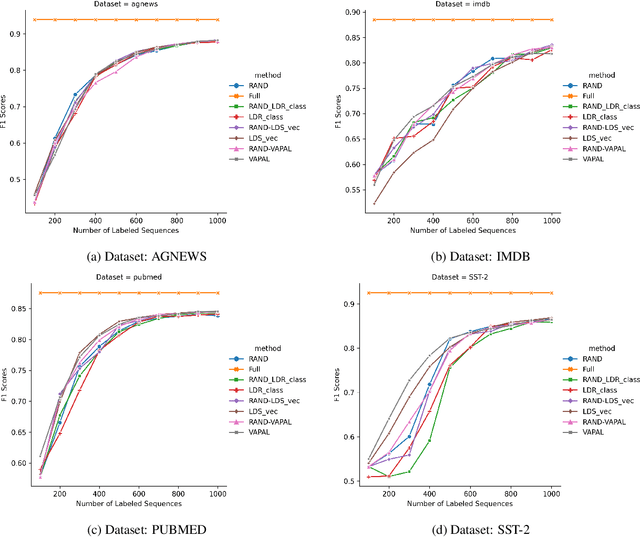
Active learning for sentence understanding attempts to reduce the annotation cost by identifying the most informative examples. Common methods for active learning use either uncertainty or diversity sampling in the pool-based scenario. In this work, to incorporate both predictive uncertainty and sample diversity, we propose Virtual Adversarial Perturbation for Active Learning (VAPAL) , an uncertainty-diversity combination framework, using virtual adversarial perturbation (Miyato et al., 2019) as model uncertainty representation. VAPAL consistently performs equally well or even better than the strong baselines on four sentence understanding datasets: AGNEWS, IMDB, PUBMED, and SST-2, offering a potential option for active learning on sentence understanding tasks.