 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLCCSP: A Scalable Framework for Enhancing Time Series Forecasting with Time-Lagged Cross-Correlations
Aug 09, 2025



Time series forecasting is critical across various domains, such as weather, finance and real estate forecasting, as accurate forecasts support informed decision-making and risk mitigation. While recent deep learning models have improved predictive capabilities, they often overlook time-lagged cross-correlations between related sequences, which are crucial for capturing complex temporal relationships. To address this, we propose the Time-Lagged Cross-Correlations-based Sequence Prediction framework (TLCCSP), which enhances forecasting accuracy by effectively integrating time-lagged cross-correlated sequences. TLCCSP employs the Sequence Shifted Dynamic Time Warping (SSDTW) algorithm to capture lagged correlations and a contrastive learning-based encoder to efficiently approximate SSDTW distances. Experimental results on weather, finance and real estate time series datasets demonstrate the effectiveness of our framework. On the weather dataset, SSDTW reduces mean squared error (MSE) by 16.01% compared with single-sequence methods, while the contrastive learning encoder (CLE) further decreases MSE by 17.88%. On the stock dataset, SSDTW achieves a 9.95% MSE reduction, and CLE reduces it by 6.13%. For the real estate dataset, SSDTW and CLE reduce MSE by 21.29% and 8.62%, respectively. Additionally, the contrastive learning approach decreases SSDTW computational time by approximately 99%, ensuring scalability and real-time applicability across multiple time series forecasting tasks.
HiGarment: Cross-modal Harmony Based Diffusion Model for Flat Sketch to Realistic Garment Image
May 29, 2025

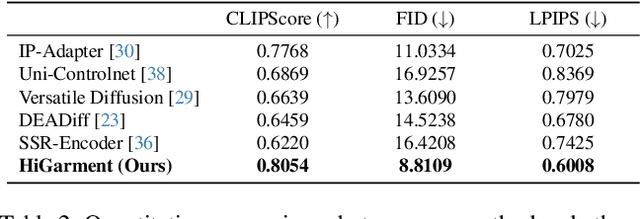

Diffusion-based garment synthesis tasks primarily focus on the design phase in the fashion domain, while the garment production process remains largely underexplored. To bridge this gap, we introduce a new task: Flat Sketch to Realistic Garment Image (FS2RG), which generates realistic garment images by integrating flat sketches and textual guidance. FS2RG presents two key challenges: 1) fabric characteristics are solely guided by textual prompts, providing insufficient visual supervision for diffusion-based models, which limits their ability to capture fine-grained fabric details; 2) flat sketches and textual guidance may provide conflicting information, requiring the model to selectively preserve or modify garment attributes while maintaining structural coherence. To tackle this task, we propose HiGarment, a novel framework that comprises two core components: i) a multi-modal semantic enhancement mechanism that enhances fabric representation across textual and visual modalities, and ii) a harmonized cross-attention mechanism that dynamically balances information from flat sketches and text prompts, allowing controllable synthesis by generating either sketch-aligned (image-biased) or text-guided (text-biased) outputs. Furthermore, we collect Multi-modal Detailed Garment, the largest open-source dataset for garment generation. Experimental results and user studies demonstrate the effectiveness of HiGarment in garment synthesis. The code and dataset will be released.
RETQA: A Large-Scale Open-Domain Tabular Question Answering Dataset for Real Estate Sector
Dec 13, 2024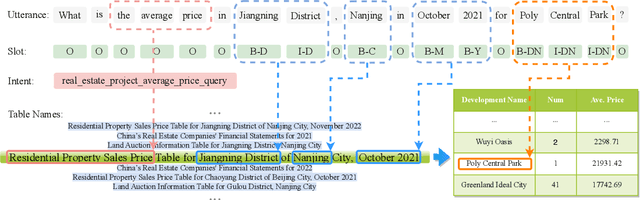

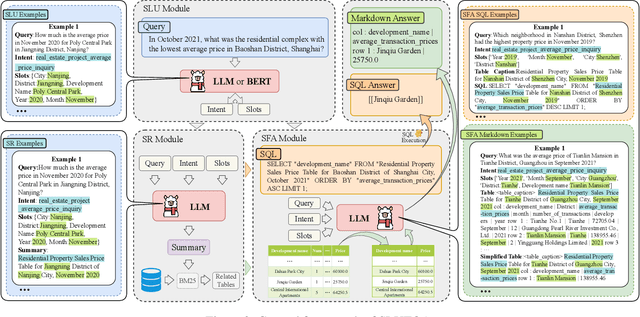

The real estate market relies heavily on structured data, such as property details, market trends, and price fluctuations. However, the lack of specialized Tabular Question Answering datasets in this domain limits the development of automated question-answering systems. To fill this gap, we introduce RETQA, the first large-scale open-domain Chinese Tabular Question Answering dataset for Real Estate. RETQA comprises 4,932 tables and 20,762 question-answer pairs across 16 sub-fields within three major domains: property information, real estate company finance information and land auction information. Compared with existing tabular question answering datasets, RETQA poses greater challenges due to three key factors: long-table structures, open-domain retrieval, and multi-domain queries. To tackle these challenges, we propose the SLUTQA framework, which integrates large language models with spoken language understanding tasks to enhance retrieval and answering accuracy. Extensive experiments demonstrate that SLUTQA significantly improves the performance of large language models on RETQA by in-context learning. RETQA and SLUTQA provide essential resources for advancing tabular question answering research in the real estate domain, addressing critical challenges in open-domain and long-table question-answering. The dataset and code are publicly available at \url{https://github.com/jensen-w/RETQA}.
Overcoming Negative Transfer by Online Selection: Distant Domain Adaptation for Fault Diagnosis
May 25, 2024



Unsupervised domain adaptation (UDA) has achieved remarkable success in fault diagnosis, bringing significant benefits to diverse industrial applications. While most UDA methods focus on cross-working condition scenarios where the source and target domains are notably similar, real-world applications often grapple with severe domain shifts. We coin the term `distant domain adaptation problem' to describe the challenge of adapting from a labeled source domain to a significantly disparate unlabeled target domain. This problem exhibits the risk of negative transfer, where extraneous knowledge from the source domain adversely affects the target domain performance. Unfortunately, conventional UDA methods often falter in mitigating this negative transfer, leading to suboptimal performance. In response to this challenge, we propose a novel Online Selective Adversarial Alignment (OSAA) approach. Central to OSAA is its ability to dynamically identify and exclude distant source samples via an online gradient masking approach, focusing primarily on source samples that closely resemble the target samples. Furthermore, recognizing the inherent complexities in bridging the source and target domains, we construct an intermediate domain to act as a transitional domain and ease the adaptation process. Lastly, we develop a class-conditional adversarial adaptation to address the label distribution disparities while learning domain invariant representation to account for potential label distribution disparities between the domains. Through detailed experiments and ablation studies on two real-world datasets, we validate the superior performance of the OSAA method over state-of-the-art methods, underscoring its significant utility in practical scenarios with severe domain shifts.
A Scope Sensitive and Result Attentive Model for Multi-Intent Spoken Language Understanding
Nov 22, 2022



Multi-Intent Spoken Language Understanding (SLU), a novel and more complex scenario of SLU, is attracting increasing attention. Unlike traditional SLU, each intent in this scenario has its specific scope. Semantic information outside the scope even hinders the prediction, which tremendously increases the difficulty of intent detection. More seriously, guiding slot filling with these inaccurate intent labels suffers error propagation problems, resulting in unsatisfied overall performance. To solve these challenges, in this paper, we propose a novel Scope-Sensitive Result Attention Network (SSRAN) based on Transformer, which contains a Scope Recognizer (SR) and a Result Attention Network (RAN). Scope Recognizer assignments scope information to each token, reducing the distraction of out-of-scope tokens. Result Attention Network effectively utilizes the bidirectional interaction between results of slot filling and intent detection, mitigating the error propagation problem. Experiments on two public datasets indicate that our model significantly improves SLU performance (5.4\% and 2.1\% on Overall accuracy) over the state-of-the-art baseline.
Capture Salient Historical Information: A Fast and Accurate Non-Autoregressive Model for Multi-turn Spoken Language Understanding
Jun 24, 2022
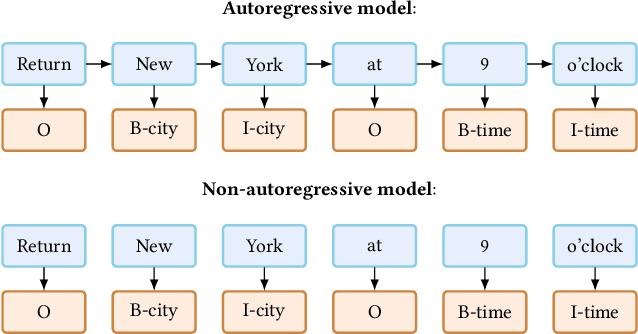
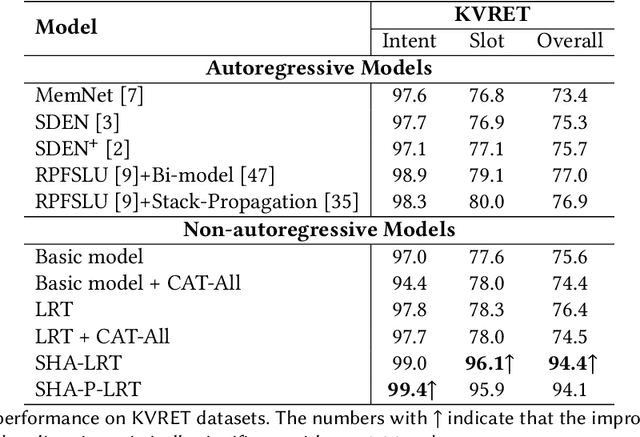
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference facing the impatience of human users. Existing work increases inference speed by designing non-autoregressive models for single-turn SLU tasks but fails to apply to multi-turn SLU in confronting the dialogue history. The intuitive idea is to concatenate all historical utterances and utilize the non-autoregressive models directly. However, this approach seriously misses the salient historical information and suffers from the uncoordinated-slot problems. To overcome those shortcomings, we propose a novel model for multi-turn SLU named Salient History Attention with Layer-Refined Transformer (SHA-LRT), which composes of an SHA module, a Layer-Refined Mechanism (LRM), and a Slot Label Generation (SLG) task. SHA captures salient historical information for the current dialogue from both historical utterances and results via a well-designed history-attention mechanism. LRM predicts preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction, and SLG obtains the sequential dependency information for the non-autoregressive encoder. Experiments on public datasets indicate that our model significantly improves multi-turn SLU performance (17.5% on Overall) with accelerating (nearly 15 times) the inference process over the state-of-the-art baseline as well as effective on the single-turn SLU tasks.
An Effective Non-Autoregressive Model for Spoken Language Understanding
Aug 16, 2021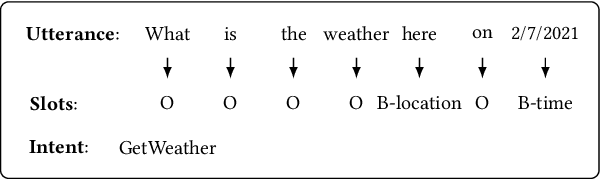
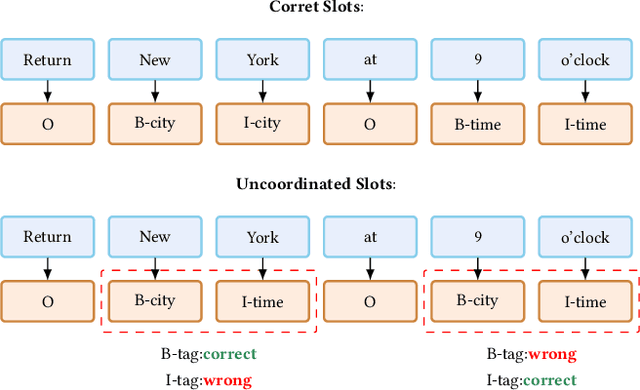
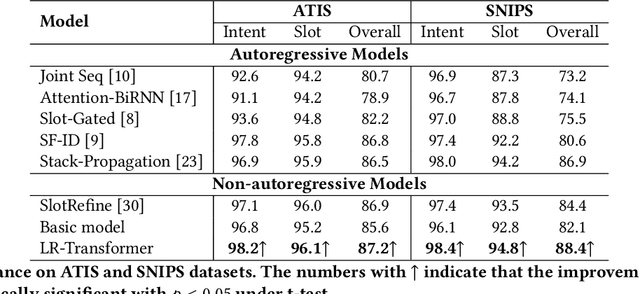
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference latency due to the impatience of humans. Non-autoregressive SLU models clearly increase the inference speed but suffer uncoordinated-slot problems caused by the lack of sequential dependency information among each slot chunk. To gap this shortcoming, in this paper, we propose a novel non-autoregressive SLU model named Layered-Refine Transformer, which contains a Slot Label Generation (SLG) task and a Layered Refine Mechanism (LRM). SLG is defined as generating the next slot label with the token sequence and generated slot labels. With SLG, the non-autoregressive model can efficiently obtain dependency information during training and spend no extra time in inference. LRM predicts the preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction. Experiments on two public datasets indicate that our model significantly improves SLU performance (1.5\% on Overall accuracy) while substantially speed up (more than 10 times) the inference process over the state-of-the-art baseline.
A Result based Portable Framework for Spoken Language Understanding
Mar 10, 2021
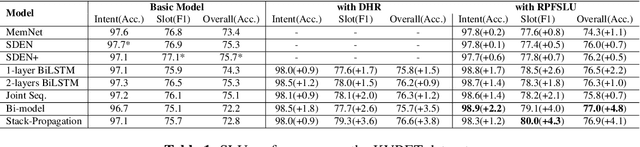
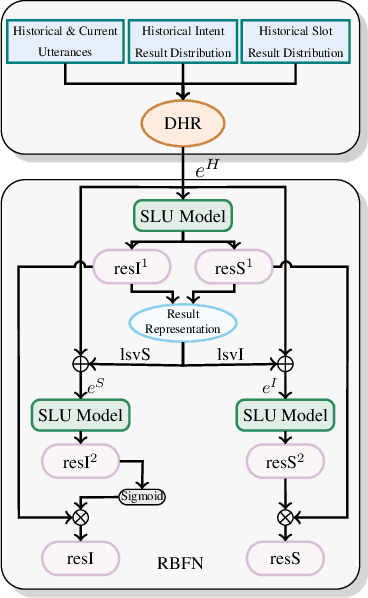
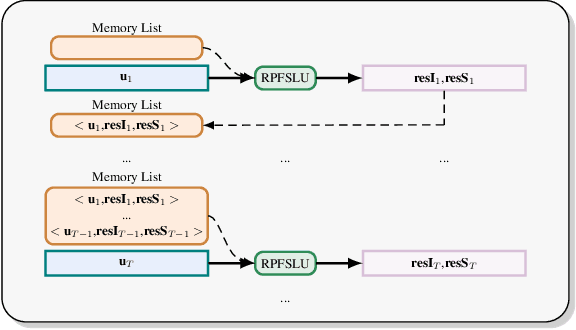
Spoken language understanding (SLU), which is a core component of the task-oriented dialogue system, has made substantial progress in the research of single-turn dialogue. However, the performance in multi-turn dialogue is still not satisfactory in the sense that the existing multi-turn SLU methods have low portability and compatibility for other single-turn SLU models. Further, existing multi-turn SLU methods do not exploit the historical predicted results when predicting the current utterance, which wastes helpful information. To gap those shortcomings, in this paper, we propose a novel Result-based Portable Framework for SLU (RPFSLU). RPFSLU allows most existing single-turn SLU models to obtain the contextual information from multi-turn dialogues and takes full advantage of predicted results in the dialogue history during the current prediction. Experimental results on the public dataset KVRET have shown that all SLU models in baselines acquire enhancement by RPFSLU on multi-turn SLU tasks.
On the Generation of Medical Dialogues for COVID-19
May 11, 2020



Under the pandemic of COVID-19, people experiencing COVID19-related symptoms or exposed to risk factors have a pressing need to consult doctors. Due to hospital closure, a lot of consulting services have been moved online. Because of the shortage of medical professionals, many people cannot receive online consultations timely. To address this problem, we aim to develop a medical dialogue system that can provide COVID19-related consultations. We collected two dialogue datasets -CovidDialog- (in English and Chinese respectively) containing conversations between doctors and patients about COVID-19. On these two datasets, we train several dialogue generation models based on Transformer, GPT, and BERT-GPT. Since the two COVID-19 dialogue datasets are small in size, which bears high risk of overfitting, we leverage transfer learning to mitigate data deficiency. Specifically, we take the pretrained models of Transformer, GPT, and BERT-GPT on dialog datasets and other large-scale texts, then finetune them on our CovidDialog datasets. Experiments demonstrate that these approaches are promising in generating meaningful medical dialogues about COVID-19. But more advanced approaches are needed to build a fully useful dialogue system that can offer accurate COVID-related consultations. The data and code are available at https://github.com/UCSD-AI4H/COVID-Dialogue
Interactive Variance Attention based Online Spoiler Detection for Time-Sync Comments
Aug 21, 2019


Nowadays, time-sync comment (TSC), a new form of interactive comments, has become increasingly popular in Chinese video websites. By posting TSCs, people can easily express their feelings and exchange their opinions with others when watching online videos. However, some spoilers appear among the TSCs. These spoilers reveal crucial plots in videos that ruin people's surprise when they first watch the video. In this paper, we proposed a novel Similarity-Based Network with Interactive Variance Attention (SBN-IVA) to classify comments as spoilers or not. In this framework, we firstly extract textual features of TSCs through the word-level attentive encoder. We design Similarity-Based Network (SBN) to acquire neighbor and keyframe similarity according to semantic similarity and timestamps of TSCs. Then, we implement Interactive Variance Attention (IVA) to eliminate the impact of noise comments. Finally, we obtain the likelihood of spoiler based on the difference between the neighbor and keyframe similarity. Experiments show SBN-IVA is on average 11.2\% higher than the state-of-the-art method on F1-score in baselines.