 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scope Sensitive and Result Attentive Model for Multi-Intent Spoken Language Understanding
Nov 22, 2022



Multi-Intent Spoken Language Understanding (SLU), a novel and more complex scenario of SLU, is attracting increasing attention. Unlike traditional SLU, each intent in this scenario has its specific scope. Semantic information outside the scope even hinders the prediction, which tremendously increases the difficulty of intent detection. More seriously, guiding slot filling with these inaccurate intent labels suffers error propagation problems, resulting in unsatisfied overall performance. To solve these challenges, in this paper, we propose a novel Scope-Sensitive Result Attention Network (SSRAN) based on Transformer, which contains a Scope Recognizer (SR) and a Result Attention Network (RAN). Scope Recognizer assignments scope information to each token, reducing the distraction of out-of-scope tokens. Result Attention Network effectively utilizes the bidirectional interaction between results of slot filling and intent detection, mitigating the error propagation problem. Experiments on two public datasets indicate that our model significantly improves SLU performance (5.4\% and 2.1\% on Overall accuracy) over the state-of-the-art baseline.
Capture Salient Historical Information: A Fast and Accurate Non-Autoregressive Model for Multi-turn Spoken Language Understanding
Jun 24, 2022
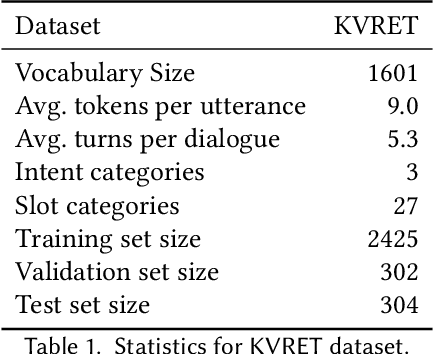
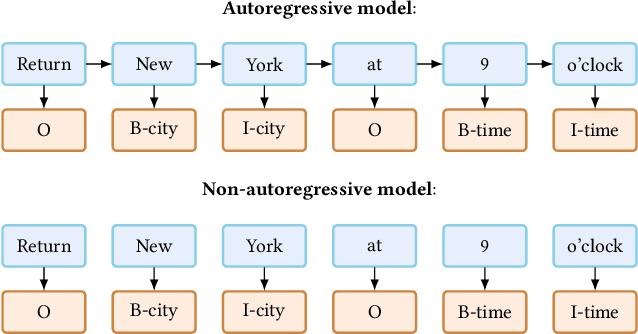
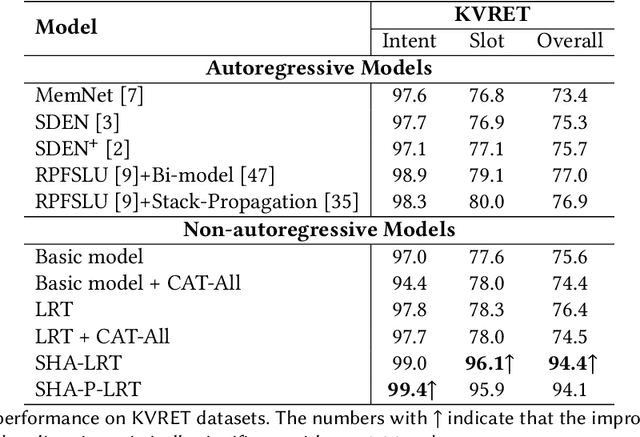
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference facing the impatience of human users. Existing work increases inference speed by designing non-autoregressive models for single-turn SLU tasks but fails to apply to multi-turn SLU in confronting the dialogue history. The intuitive idea is to concatenate all historical utterances and utilize the non-autoregressive models directly. However, this approach seriously misses the salient historical information and suffers from the uncoordinated-slot problems. To overcome those shortcomings, we propose a novel model for multi-turn SLU named Salient History Attention with Layer-Refined Transformer (SHA-LRT), which composes of an SHA module, a Layer-Refined Mechanism (LRM), and a Slot Label Generation (SLG) task. SHA captures salient historical information for the current dialogue from both historical utterances and results via a well-designed history-attention mechanism. LRM predicts preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction, and SLG obtains the sequential dependency information for the non-autoregressive encoder. Experiments on public datasets indicate that our model significantly improves multi-turn SLU performance (17.5% on Overall) with accelerating (nearly 15 times) the inference process over the state-of-the-art baseline as well as effective on the single-turn SLU tasks.
An Effective Non-Autoregressive Model for Spoken Language Understanding
Aug 16, 2021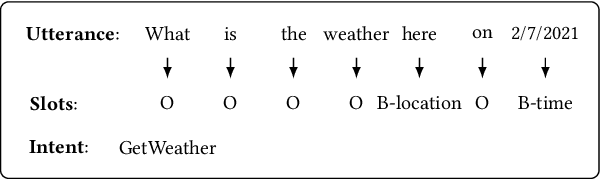
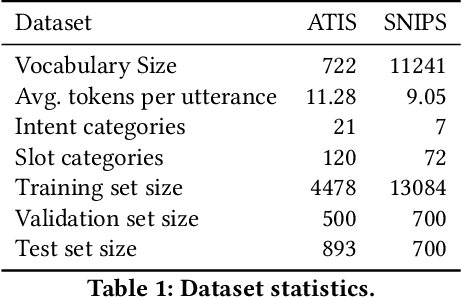
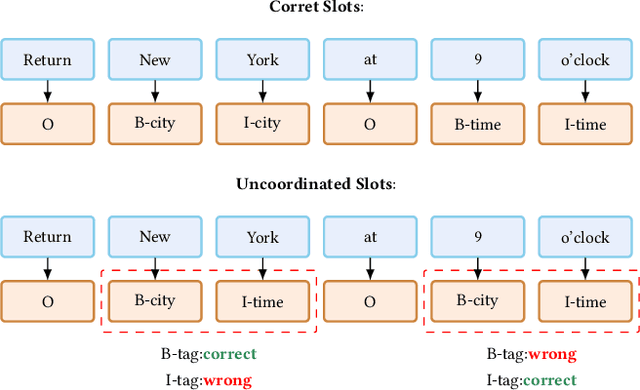
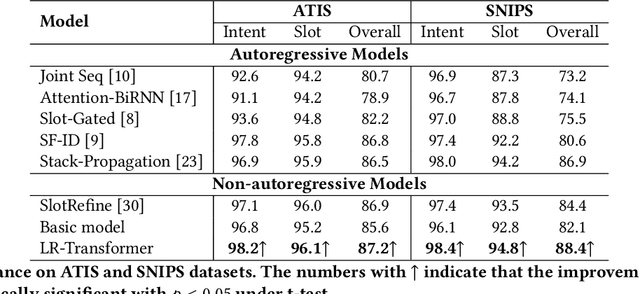
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference latency due to the impatience of humans. Non-autoregressive SLU models clearly increase the inference speed but suffer uncoordinated-slot problems caused by the lack of sequential dependency information among each slot chunk. To gap this shortcoming, in this paper, we propose a novel non-autoregressive SLU model named Layered-Refine Transformer, which contains a Slot Label Generation (SLG) task and a Layered Refine Mechanism (LRM). SLG is defined as generating the next slot label with the token sequence and generated slot labels. With SLG, the non-autoregressive model can efficiently obtain dependency information during training and spend no extra time in inference. LRM predicts the preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction. Experiments on two public datasets indicate that our model significantly improves SLU performance (1.5\% on Overall accuracy) while substantially speed up (more than 10 times) the inference process over the state-of-the-art baseline.
A Result based Portable Framework for Spoken Language Understanding
Mar 10, 2021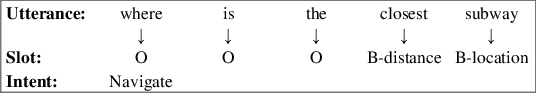
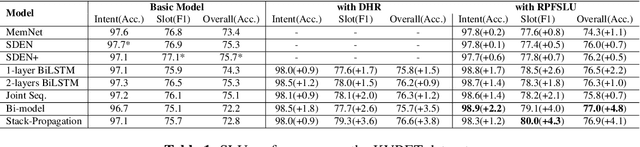
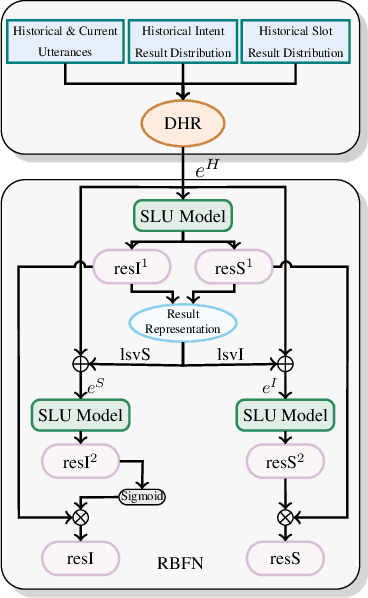
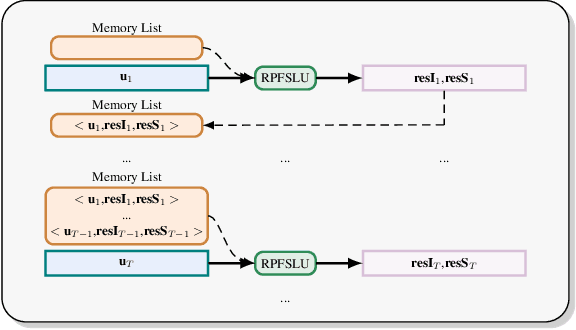
Spoken language understanding (SLU), which is a core component of the task-oriented dialogue system, has made substantial progress in the research of single-turn dialogue. However, the performance in multi-turn dialogue is still not satisfactory in the sense that the existing multi-turn SLU methods have low portability and compatibility for other single-turn SLU models. Further, existing multi-turn SLU methods do not exploit the historical predicted results when predicting the current utterance, which wastes helpful information. To gap those shortcomings, in this paper, we propose a novel Result-based Portable Framework for SLU (RPFSLU). RPFSLU allows most existing single-turn SLU models to obtain the contextual information from multi-turn dialogues and takes full advantage of predicted results in the dialogue history during the current prediction. Experimental results on the public dataset KVRET have shown that all SLU models in baselines acquire enhancement by RPFSLU on multi-turn SLU tasks.
Training GANs with Centripetal Acceleration
Feb 24, 2019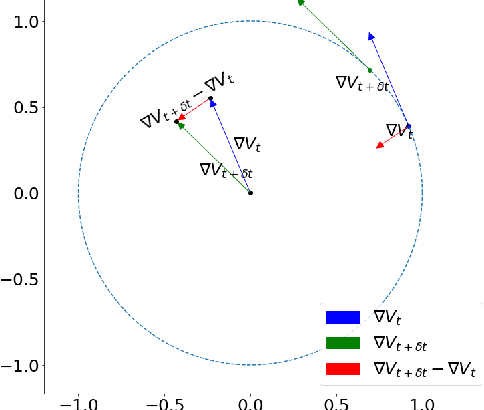
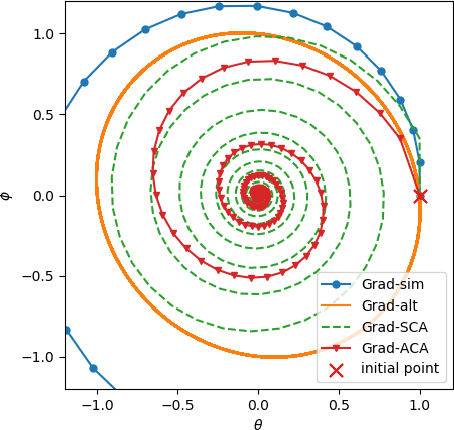
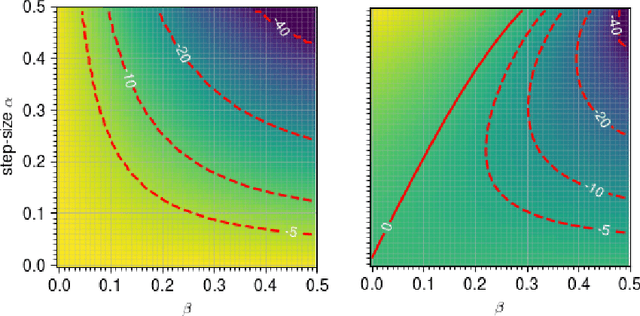
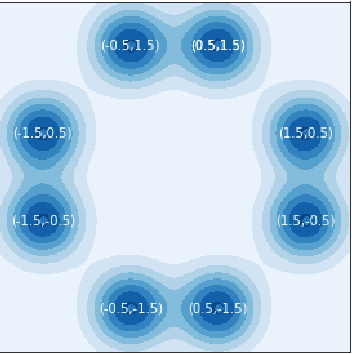
Training generative adversarial networks (GANs) often suffers from cyclic behaviors of iterates. Based on a simple intuition that the direction of centripetal acceleration of an object moving in uniform circular motion is toward the center of the circle, we present the Simultaneous Centripetal Acceleration (SCA) method and the Alternating Centripetal Acceleration (ACA) method to alleviate the cyclic behaviors. Under suitable conditions, gradient descent methods with either SCA or ACA are shown to be linearly convergent for bilinear games. Numerical experiments are conducted by applying ACA to existing gradient-based algorithms in a GAN setup scenario, which demonstrate the superiority of ACA.
A convergence framework for inexact nonconvex and nonsmooth algorithms and its applications to several iterations
Aug 10, 2018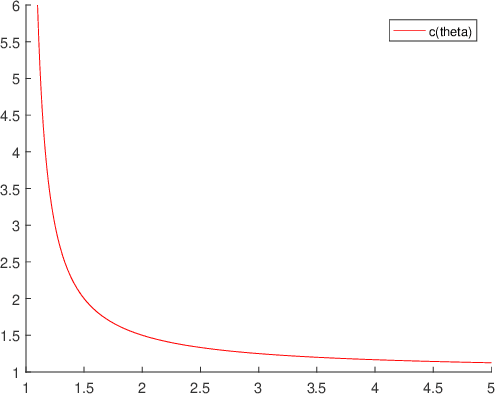
In this paper, we consider the convergence of an abstract inexact nonconvex and nonsmooth algorithm. We promise a pseudo sufficient descent condition and a pseudo relative error condition, which are both related to an auxiliary sequence, for the algorithm; and a continuity condition is assumed to hold. In fact, a lot of classical inexact nonconvex and nonsmooth algorithms allow these three conditions. Under a special kind of summable assumption on the auxiliary sequence, we prove the sequence generated by the general algorithm converges to a critical point of the objective function if being assumed Kurdyka- Lojasiewicz property. The core of the proofs lies in building a new Lyapunov function, whose successive difference provides a bound for the successive difference of the points generated by the algorithm. And then, we apply our findings to several classical nonconvex iterative algorithms and derive the corresponding convergence results
Strongly Convex Programming for Exact Matrix Completion and Robust Principal Component Analysis
Jan 05, 2012The common task in matrix completion (MC) and robust principle component analysis (RPCA) is to recover a low-rank matrix from a given data matrix. These problems gained great attention from various areas in applied sciences recently, especially after the publication of the pioneering works of Cand`es et al.. One fundamental result in MC and RPCA is that nuclear norm based convex optimizations lead to the exact low-rank matrix recovery under suitable conditions. In this paper, we extend this result by showing that strongly convex optimizations can guarantee the exact low-rank matrix recovery as well. The result in this paper not only provides sufficient conditions under which the strongly convex models lead to the exact low-rank matrix recovery, but also guides us on how to choose suitable parameters in practical algorithms.