 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapture Salient Historical Information: A Fast and Accurate Non-Autoregressive Model for Multi-turn Spoken Language Understanding
Jun 24, 2022
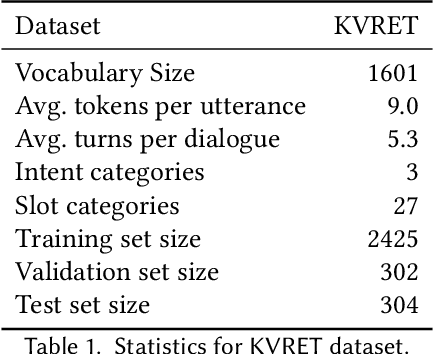
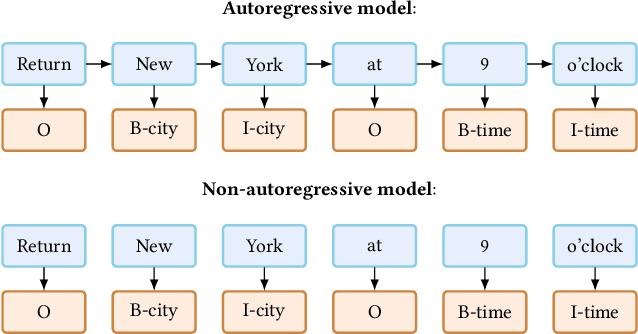
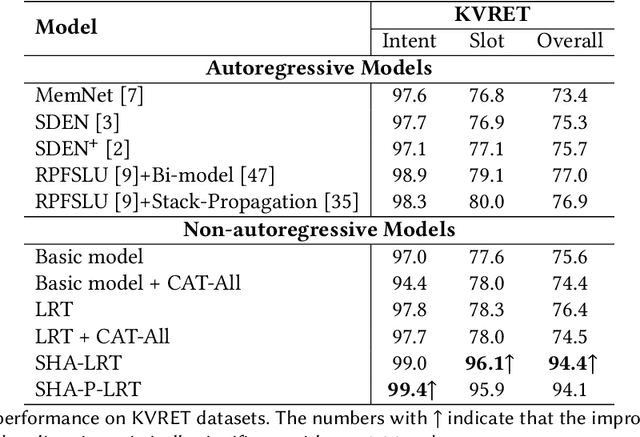
Spoken Language Understanding (SLU), a core component of the task-oriented dialogue system, expects a shorter inference facing the impatience of human users. Existing work increases inference speed by designing non-autoregressive models for single-turn SLU tasks but fails to apply to multi-turn SLU in confronting the dialogue history. The intuitive idea is to concatenate all historical utterances and utilize the non-autoregressive models directly. However, this approach seriously misses the salient historical information and suffers from the uncoordinated-slot problems. To overcome those shortcomings, we propose a novel model for multi-turn SLU named Salient History Attention with Layer-Refined Transformer (SHA-LRT), which composes of an SHA module, a Layer-Refined Mechanism (LRM), and a Slot Label Generation (SLG) task. SHA captures salient historical information for the current dialogue from both historical utterances and results via a well-designed history-attention mechanism. LRM predicts preliminary SLU results from Transformer's middle states and utilizes them to guide the final prediction, and SLG obtains the sequential dependency information for the non-autoregressive encoder. Experiments on public datasets indicate that our model significantly improves multi-turn SLU performance (17.5% on Overall) with accelerating (nearly 15 times) the inference process over the state-of-the-art baseline as well as effective on the single-turn SLU tasks.