 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Table-to-Text Generation with Prefix-Controlled Generator
Aug 23, 2022
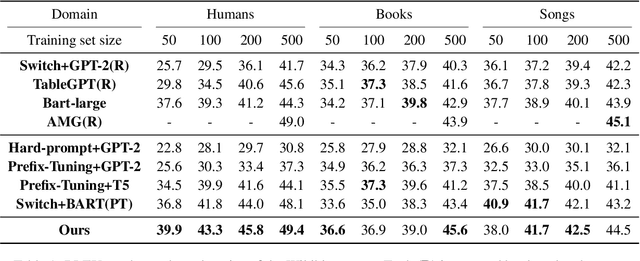
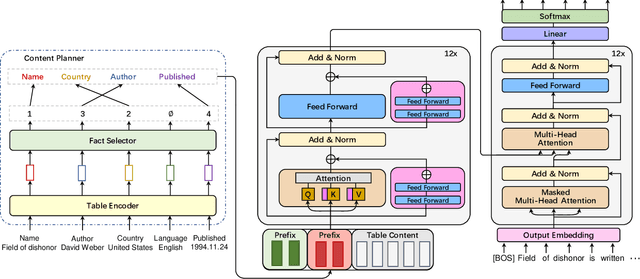
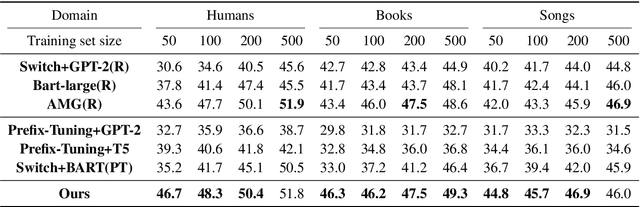
Neural table-to-text generation approaches are data-hungry, limiting their adaptation for low-resource real-world applications. Previous works mostly resort to Pre-trained Language Models (PLMs) to generate fluent summaries of a table. However, they often contain hallucinated contents due to the uncontrolled nature of PLMs. Moreover, the topological differences between tables and sequences are rarely studied. Last but not least, fine-tuning on PLMs with a handful of instances may lead to over-fitting and catastrophic forgetting. To alleviate these problems, we propose a prompt-based approach, Prefix-Controlled Generator (i.e., PCG), for few-shot table-to-text generation. We prepend a task-specific prefix for a PLM to make the table structure better fit the pre-trained input. In addition, we generate an input-specific prefix to control the factual contents and word order of the generated text. Both automatic and human evaluations on different domains (humans, books and songs) of the Wikibio dataset show substantial improvements over baseline approaches.
Interactive Variance Attention based Online Spoiler Detection for Time-Sync Comments
Aug 21, 2019
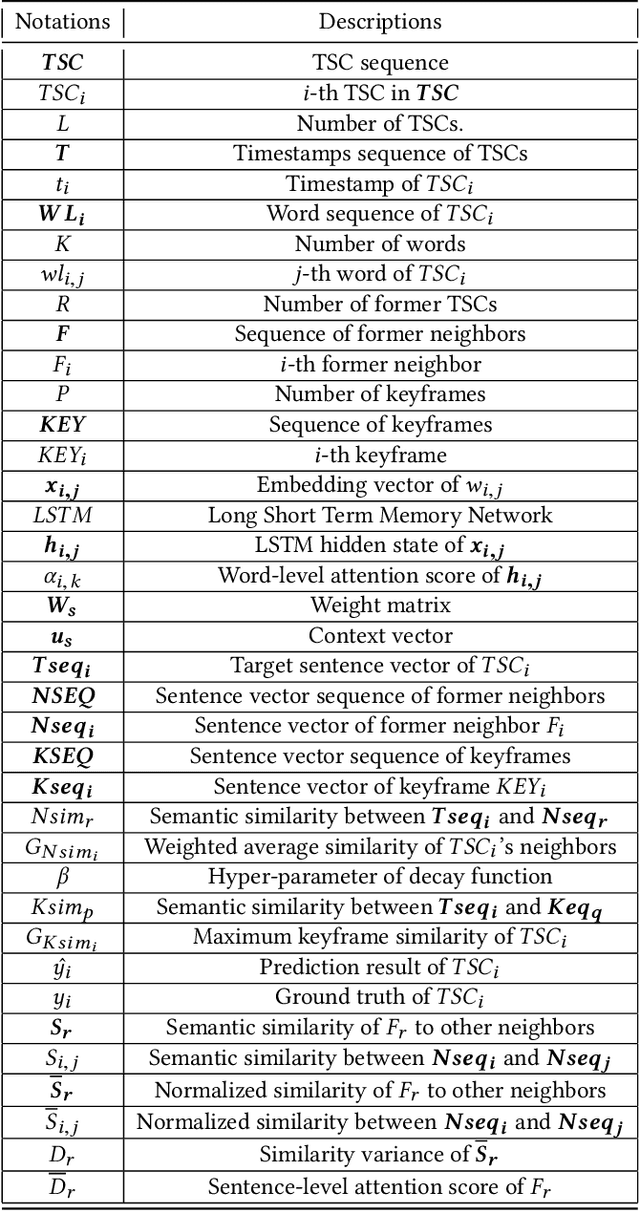


Nowadays, time-sync comment (TSC), a new form of interactive comments, has become increasingly popular in Chinese video websites. By posting TSCs, people can easily express their feelings and exchange their opinions with others when watching online videos. However, some spoilers appear among the TSCs. These spoilers reveal crucial plots in videos that ruin people's surprise when they first watch the video. In this paper, we proposed a novel Similarity-Based Network with Interactive Variance Attention (SBN-IVA) to classify comments as spoilers or not. In this framework, we firstly extract textual features of TSCs through the word-level attentive encoder. We design Similarity-Based Network (SBN) to acquire neighbor and keyframe similarity according to semantic similarity and timestamps of TSCs. Then, we implement Interactive Variance Attention (IVA) to eliminate the impact of noise comments. Finally, we obtain the likelihood of spoiler based on the difference between the neighbor and keyframe similarity. Experiments show SBN-IVA is on average 11.2\% higher than the state-of-the-art method on F1-score in baselines.
Legal Judgment Prediction via Multi-Perspective Bi-Feedback Network
May 16, 2019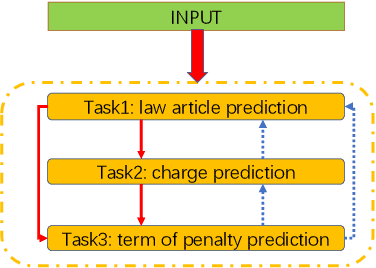
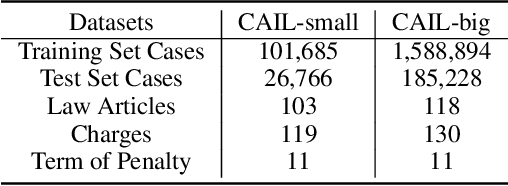
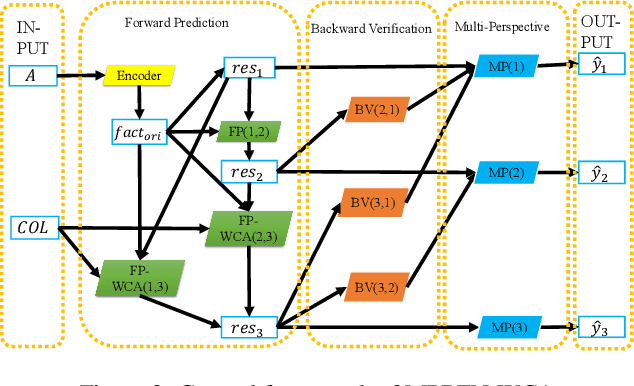

The Legal Judgment Prediction (LJP) is to determine judgment results based on the fact descriptions of the cases. LJP usually consists of multiple subtasks, such as applicable law articles prediction, charges prediction, and the term of the penalty prediction. These multiple subtasks have topological dependencies, the results of which affect and verify each other. However, existing methods use dependencies of results among multiple subtasks inefficiently. Moreover, for cases with similar descriptions but different penalties, current methods cannot predict accurately because the word collocation information is ignored. In this paper, we propose a Multi-Perspective Bi-Feedback Network with the Word Collocation Attention mechanism based on the topology structure among subtasks. Specifically, we design a multi-perspective forward prediction and backward verification framework to utilize result dependencies among multiple subtasks effectively. To distinguish cases with similar descriptions but different penalties, we integrate word collocations features of fact descriptions into the network via an attention mechanism. The experimental results show our model achieves significant improvements over baselines on all prediction tasks.