 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prefix Cache to Fusion RAG Cache: Accelerating LLM Inference in Retrieval-Augmented Generation
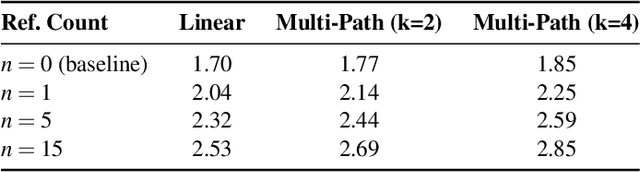
Jan 19, 2026Retrieval-Augmented Generation enhances Large Language Models by integrating external knowledge, which reduces hallucinations but increases prompt length. This increase leads to higher computational costs and longer Time to First Token (TTFT). To mitigate this issue, existing solutions aim to reuse the preprocessed KV cache of each retrieved chunk to accelerate RAG. However, the lack of cross-chunk contextual information leads to a significant drop in generation quality, leaving the potential benefits of KV cache reuse largely unfulfilled. The challenge lies in how to reuse the precomputed KV cache of chunks while preserving generation quality. We propose FusionRAG, a novel inference framework that optimizes both the preprocessing and reprocessing stages of RAG. In the offline preprocessing stage, we embed information from other related text chunks into each chunk, while in the online reprocessing stage, we recompute the KV cache for tokens that the model focuses on. As a result, we achieve a better trade-off between generation quality and efficiency. According to our experiments, FusionRAG significantly improves generation quality at the same recomputation ratio compared to previous state-of-the-art solutions. By recomputing fewer than 15% of the tokens, FusionRAG achieves up to 70% higher normalized F1 scores than baselines and reduces TTFT by 2.66x-9.39x compared to Full Attention.
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
Nov 18, 2025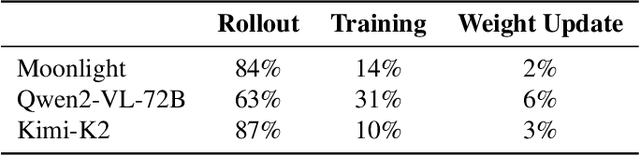
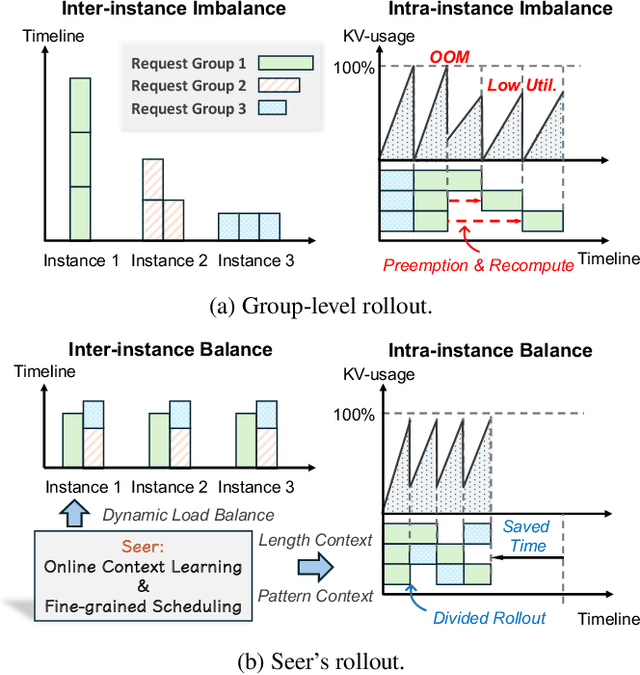
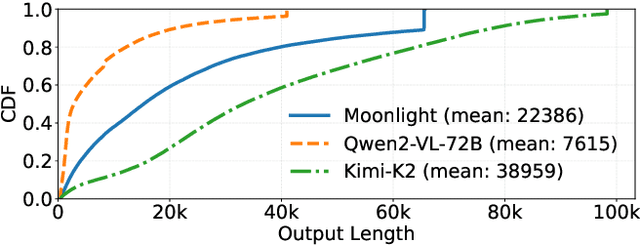
Reinforcement Learning (RL) has become critical for advancing modern Large Language Models (LLMs), yet existing synchronous RL systems face severe performance bottlenecks. The rollout phase, which dominates end-to-end iteration time, suffers from substantial long-tail latency and poor resource utilization due to inherent workload imbalance. We present Seer, a novel online context learning system that addresses these challenges by exploiting previously overlooked similarities in output lengths and generation patterns among requests sharing the same prompt. Seer introduces three key techniques: divided rollout for dynamic load balancing, context-aware scheduling, and adaptive grouped speculative decoding. Together, these mechanisms substantially reduce long-tail latency and improve resource efficiency during rollout. Evaluations on production-grade RL workloads demonstrate that Seer improves end-to-end rollout throughput by 74% to 97% and reduces long-tail latency by 75% to 93% compared to state-of-the-art synchronous RL systems, significantly accelerating RL training iterations.
Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving
Jul 02, 2024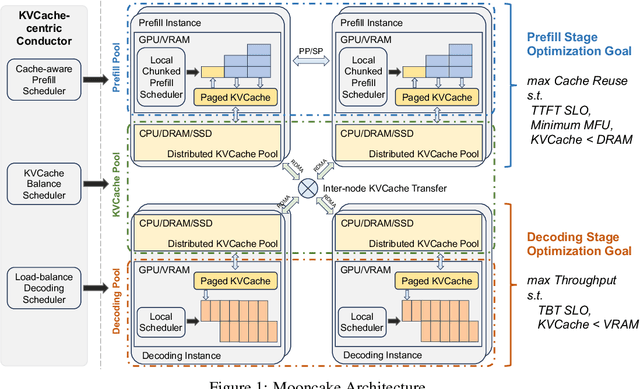


Mooncake is the serving platform for Kimi, a leading LLM service provided by Moonshot AI. It features a KVCache-centric disaggregated architecture that separates the prefill and decoding clusters. It also leverages the underutilized CPU, DRAM, and SSD resources of the GPU cluster to implement a disaggregated cache of KVCache. The core of Mooncake is its KVCache-centric scheduler, which balances maximizing overall effective throughput while meeting latency-related Service Level Objectives (SLOs). Unlike traditional studies that assume all requests will be processed, Mooncake faces challenges due to highly overloaded scenarios. To mitigate these, we developed a prediction-based early rejection policy. Experiments show that Mooncake excels in long-context scenarios. Compared to the baseline method, Mooncake can achieve up to a 525% increase in throughput in certain simulated scenarios while adhering to SLOs. Under real workloads, Mooncake's innovative architecture enables Kimi to handle 75% more requests.
Efficient and Economic Large Language Model Inference with Attention Offloading
May 03, 2024
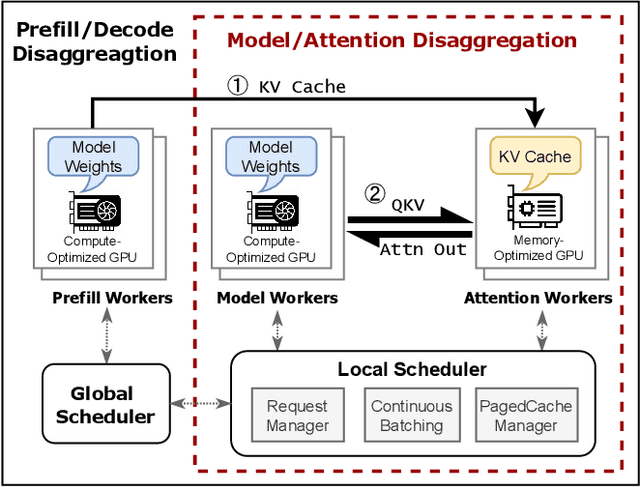


Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.