 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSide Adapter Network for Open-Vocabulary Semantic Segmentation
Paper and Code



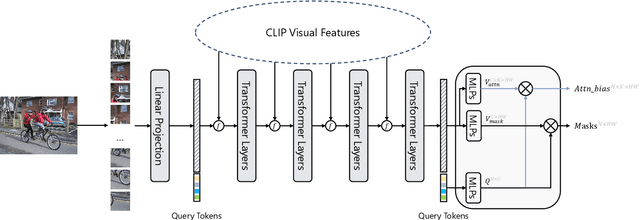
This paper presents a new framework for open-vocabulary semantic segmentation with the pre-trained vision-language model, named Side Adapter Network (SAN). Our approach models the semantic segmentation task as a region recognition problem. A side network is attached to a frozen CLIP model with two branches: one for predicting mask proposals, and the other for predicting attention bias which is applied in the CLIP model to recognize the class of masks. This decoupled design has the benefit CLIP in recognizing the class of mask proposals. Since the attached side network can reuse CLIP features, it can be very light. In addition, the entire network can be trained end-to-end, allowing the side network to be adapted to the frozen CLIP model, which makes the predicted mask proposals CLIP-aware. Our approach is fast, accurate, and only adds a few additional trainable parameters. We evaluate our approach on multiple semantic segmentation benchmarks. Our method significantly outperforms other counterparts, with up to 18 times fewer trainable parameters and 19 times faster inference speed. We hope our approach will serve as a solid baseline and help ease future research in open-vocabulary semantic segmentation. The code will be available at https://github.com/MendelXu/SAN.