 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-boosted Deformable 3D Gaussians for Fast Dynamic Scene Reconstruction
Nov 25, 2024



3D Gaussian Splatting (3D-GS) enables real-time rendering but struggles with fast motion due to low temporal resolution of RGB cameras. To address this, we introduce the first approach combining event cameras, which capture high-temporal-resolution, continuous motion data, with deformable 3D-GS for fast dynamic scene reconstruction. We observe that threshold modeling for events plays a crucial role in achieving high-quality reconstruction. Therefore, we propose a GS-Threshold Joint Modeling (GTJM) strategy, creating a mutually reinforcing process that greatly improves both 3D reconstruction and threshold modeling. Moreover, we introduce a Dynamic-Static Decomposition (DSD) strategy that first identifies dynamic areas by exploiting the inability of static Gaussians to represent motions, then applies a buffer-based soft decomposition to separate dynamic and static areas. This strategy accelerates rendering by avoiding unnecessary deformation in static areas, and focuses on dynamic areas to enhance fidelity. Our approach achieves high-fidelity dynamic reconstruction at 156 FPS with a 400$\times$400 resolution on an RTX 3090 GPU.
CEIA: CLIP-Based Event-Image Alignment for Open-World Event-Based Understanding
Jul 09, 2024



We present CEIA, an effective framework for open-world event-based understanding. Currently training a large event-text model still poses a huge challenge due to the shortage of paired event-text data. In response to this challenge, CEIA learns to align event and image data as an alternative instead of directly aligning event and text data. Specifically, we leverage the rich event-image datasets to learn an event embedding space aligned with the image space of CLIP through contrastive learning. In this way, event and text data are naturally aligned via using image data as a bridge. Particularly, CEIA offers two distinct advantages. First, it allows us to take full advantage of the existing event-image datasets to make up the shortage of large-scale event-text datasets. Second, leveraging more training data, it also exhibits the flexibility to boost performance, ensuring scalable capability. In highlighting the versatility of our framework, we make extensive evaluations through a diverse range of event-based multi-modal applications, such as object recognition, event-image retrieval, event-text retrieval, and domain adaptation. The outcomes demonstrate CEIA's distinct zero-shot superiority over existing methods on these applications.
Event-assisted Low-Light Video Object Segmentation
Apr 02, 2024In the realm of video object segmentation (VOS), the challenge of operating under low-light conditions persists, resulting in notably degraded image quality and compromised accuracy when comparing query and memory frames for similarity computation. Event cameras, characterized by their high dynamic range and ability to capture motion information of objects, offer promise in enhancing object visibility and aiding VOS methods under such low-light conditions. This paper introduces a pioneering framework tailored for low-light VOS, leveraging event camera data to elevate segmentation accuracy. Our approach hinges on two pivotal components: the Adaptive Cross-Modal Fusion (ACMF) module, aimed at extracting pertinent features while fusing image and event modalities to mitigate noise interference, and the Event-Guided Memory Matching (EGMM) module, designed to rectify the issue of inaccurate matching prevalent in low-light settings. Additionally, we present the creation of a synthetic LLE-DAVIS dataset and the curation of a real-world LLE-VOS dataset, encompassing frames and events. Experimental evaluations corroborate the efficacy of our method across both datasets, affirming its effectiveness in low-light scenarios.
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
Nov 30, 2023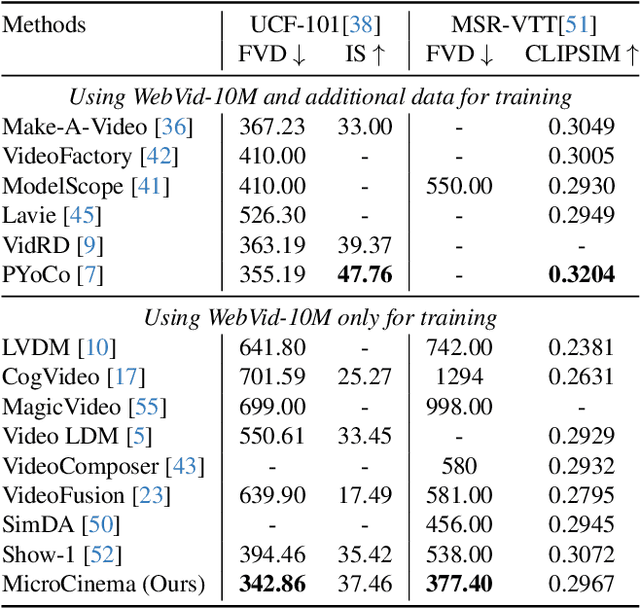
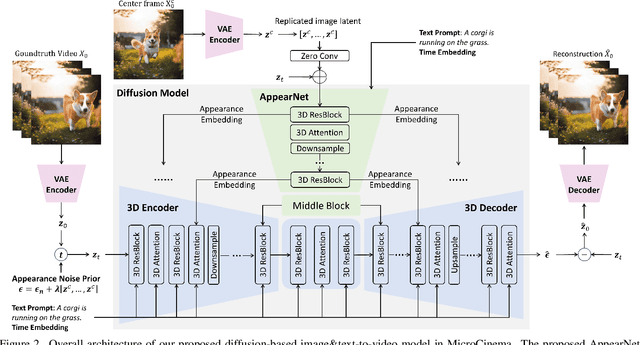
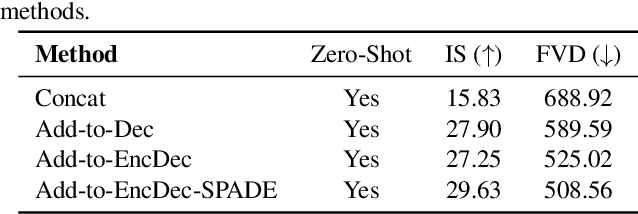
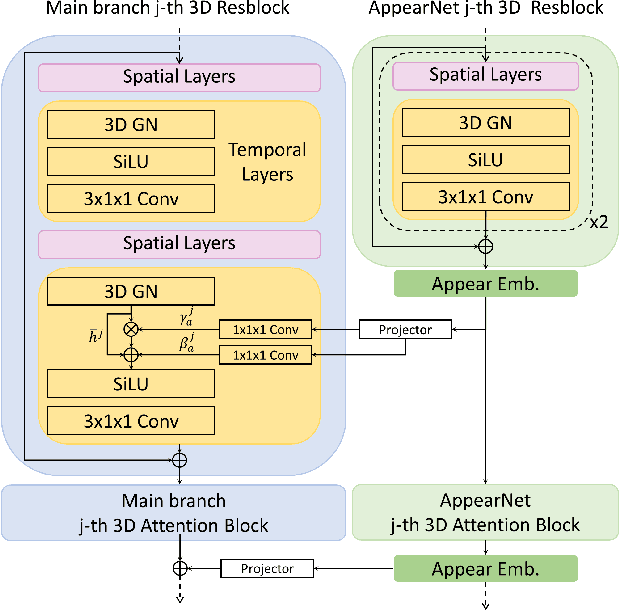
We present MicroCinema, a straightforward yet effective framework for high-quality and coherent text-to-video generation. Unlike existing approaches that align text prompts with video directly, MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage process: text-to-image generation and image\&text-to-video generation. This strategy offers two significant advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b) Leveraging the generated image, the model can allocate less focus to fine-grained appearance details, prioritizing the efficient learning of motion dynamics. To implement this strategy effectively, we introduce two core designs. First, we propose the Appearance Injection Network, enhancing the preservation of the appearance of the given image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on MSR-VTT. See https://wangyanhui666.github.io/MicroCinema.github.io/ for video samples.
ART$\boldsymbol{\cdot}$V: Auto-Regressive Text-to-Video Generation with Diffusion Models
Nov 30, 2023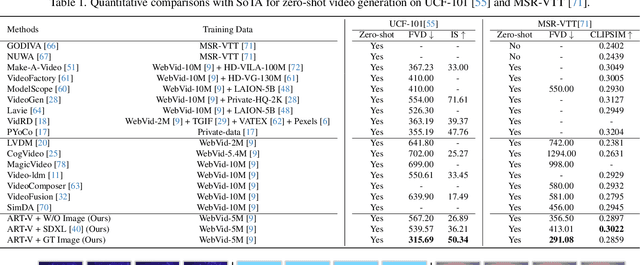
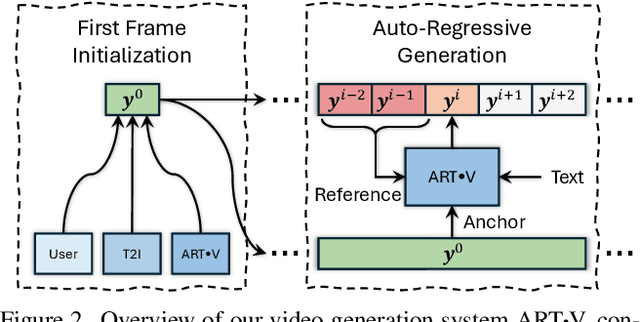
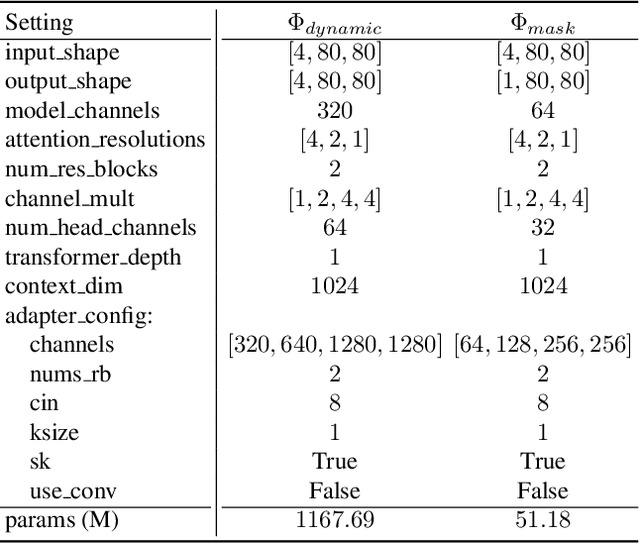
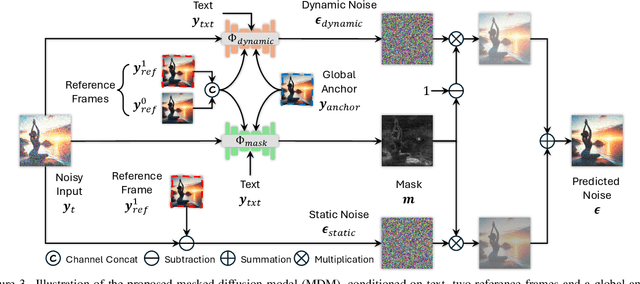
We present ART$\boldsymbol{\cdot}$V, an efficient framework for auto-regressive video generation with diffusion models. Unlike existing methods that generate entire videos in one-shot, ART$\boldsymbol{\cdot}$V generates a single frame at a time, conditioned on the previous ones. The framework offers three distinct advantages. First, it only learns simple continual motions between adjacent frames, therefore avoiding modeling complex long-range motions that require huge training data. Second, it preserves the high-fidelity generation ability of the pre-trained image diffusion models by making only minimal network modifications. Third, it can generate arbitrarily long videos conditioned on a variety of prompts such as text, image or their combinations, making it highly versatile and flexible. To combat the common drifting issue in AR models, we propose masked diffusion model which implicitly learns which information can be drawn from reference images rather than network predictions, in order to reduce the risk of generating inconsistent appearances that cause drifting. Moreover, we further enhance generation coherence by conditioning it on the initial frame, which typically contains minimal noise. This is particularly useful for long video generation. When trained for only two weeks on four GPUs, ART$\boldsymbol{\cdot}$V already can generate videos with natural motions, rich details and a high level of aesthetic quality. Besides, it enables various appealing applications, e.g., composing a long video from multiple text prompts.
EGVD: Event-Guided Video Deraining
Sep 29, 2023



With the rapid development of deep learning, video deraining has experienced significant progress. However, existing video deraining pipelines cannot achieve satisfying performance for scenes with rain layers of complex spatio-temporal distribution. In this paper, we approach video deraining by employing an event camera. As a neuromorphic sensor, the event camera suits scenes of non-uniform motion and dynamic light conditions. We propose an end-to-end learning-based network to unlock the potential of the event camera for video deraining. First, we devise an event-aware motion detection module to adaptively aggregate multi-frame motion contexts using event-aware masks. Second, we design a pyramidal adaptive selection module for reliably separating the background and rain layers by incorporating multi-modal contextualized priors. In addition, we build a real-world dataset consisting of rainy videos and temporally synchronized event streams. We compare our method with extensive state-of-the-art methods on synthetic and self-collected real-world datasets, demonstrating the clear superiority of our method. The code and dataset are available at \url{https://github.com/booker-max/EGVD}.
CCEdit: Creative and Controllable Video Editing via Diffusion Models
Sep 28, 2023



In this work, we present CCEdit, a versatile framework designed to address the challenges of creative and controllable video editing. CCEdit accommodates a wide spectrum of user editing requirements and enables enhanced creative control through an innovative approach that decouples video structure and appearance. We leverage the foundational ControlNet architecture to preserve structural integrity, while seamlessly integrating adaptable temporal modules compatible with state-of-the-art personalization techniques for text-to-image generation, such as DreamBooth and LoRA.Furthermore, we introduce reference-conditioned video editing, empowering users to exercise precise creative control over video editing through the more manageable process of editing key frames. Our extensive experimental evaluations confirm the exceptional functionality and editing capabilities of the proposed CCEdit framework. Demo video is available at https://www.youtube.com/watch?v=UQw4jq-igN4.