 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Only Image Captioning with Multi-Context Data Generation
Paper and Code
May 29, 2023

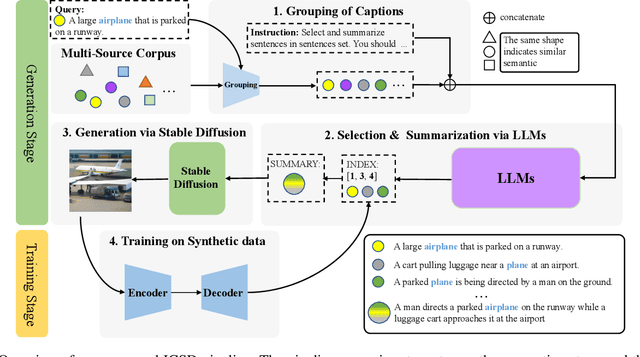

Text-only Image Captioning (TIC) is an approach that aims to construct a model solely based on text that can accurately describe images. Recently, diffusion models have demonstrated remarkable capabilities in generating high-quality images that are semantically coherent with given texts. This presents an opportunity to generate synthetic training images for TIC. However, we have identified a challenge that the images generated from simple descriptions typically exhibit a single perspective with one or limited contexts, which is not aligned with the complexity of real-world scenes in the image domain. In this paper, we propose a novel framework that addresses this issue by introducing multi-context data generation. Starting with an initial text corpus, our framework employs a large language model to select multiple sentences that describe the same scene from various perspectives. These sentences are then summarized into a single sentence with multiple contexts. We generate simple images using the straightforward sentences and complex images using the summarized sentences through diffusion models. Finally, we train the model exclusively using the synthetic image-text pairs obtained from this process. Experimental results demonstrate that our proposed framework effectively tackles the central challenge we have identified, achieving the state-of-the-art performance on popular datasets such as MSCOCO, Flickr30k, and SS1M.